

Identifying disease-associated copy number variations by a doubly penalized regression model
- PMID: 29894562
- PMCID: PMC6663092
- DOI: 10.1111/biom.12920
Identifying disease-associated copy number variations by a doubly penalized regression model
Abstract
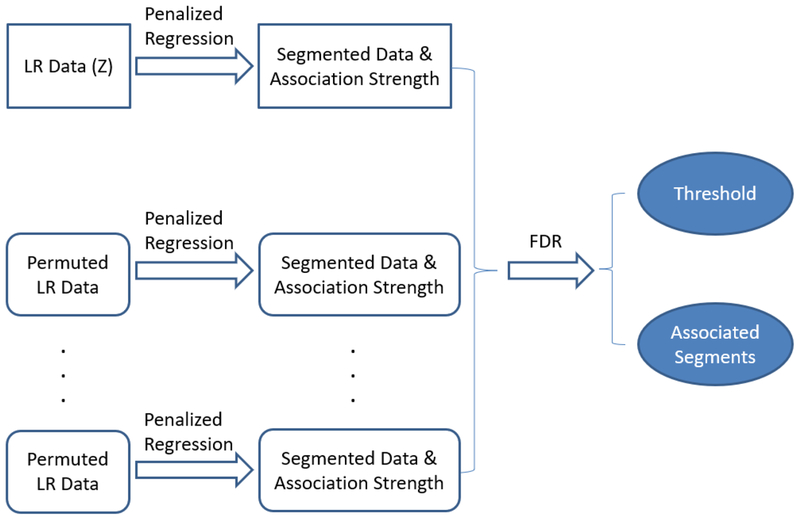
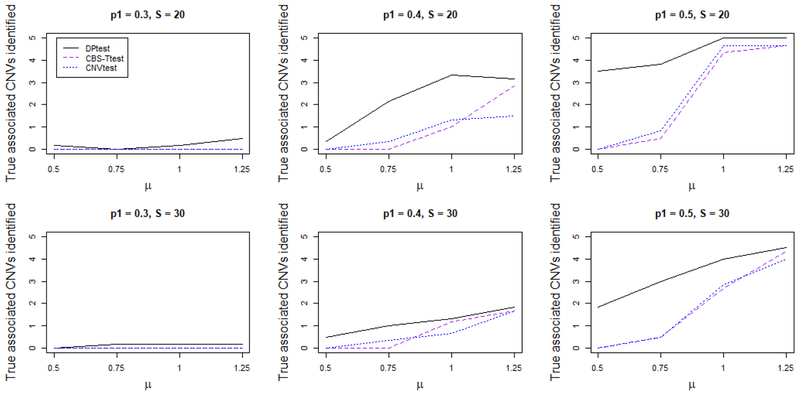
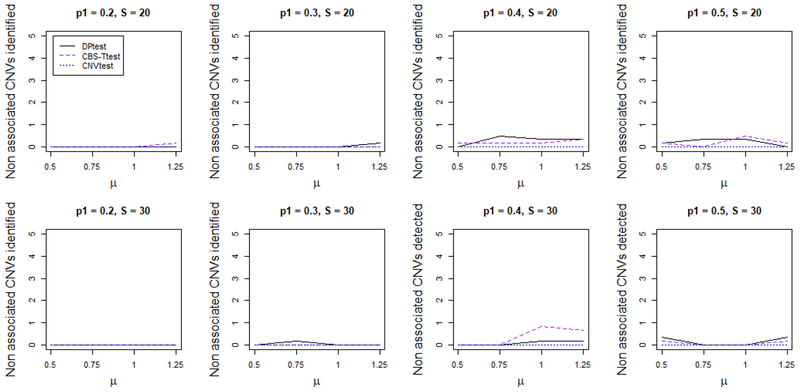
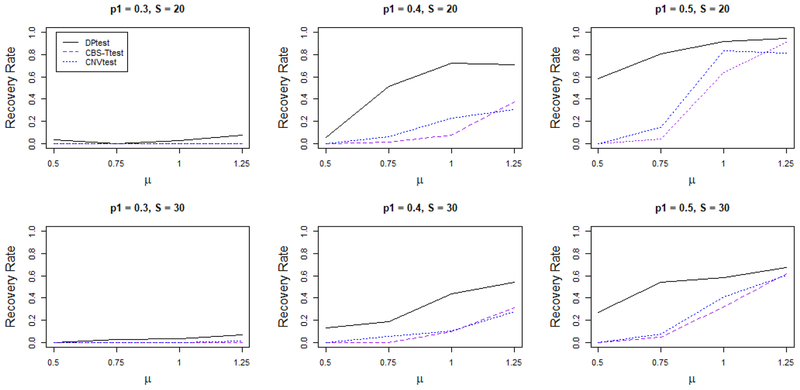
Copy number variation (CNV) of DNA plays an important role in the development of many diseases. However, due to the irregularity and sparsity of the CNVs, studying the association between CNVs and a disease outcome or a trait can be challenging. Up to now, not many methods have been proposed in the literature for this problem. Most of the current researchers reply on an ad hoc two-stage procedure by first identifying CNVs in each individual genome and then performing an association test using these identified CNVs. This potentially leads to information loss and as a result a lower power to identify disease associated CNVs. In this article, we describe a new method that combines the two steps into a single coherent model to identify the common CNV across patients that are associated with certain diseases. We use a double penalty model to capture CNVs' association with both the intensities and the disease trait. We validate its performance in simulated datasets and a data example on platinum resistance and CNV in ovarian cancer genome.
Keywords: Association study; Copy number variation; Ovarian cancer; Penalized regression model.
© 2018, The International Biometric Society.
Figures
References
-
- Alvarez AA, Lambers AR, Lancaster JM, Maxwell GL, Ali S, Gumbs C, et al. (2001). Allele Loss on Chromosome 1p36 in Epithelial Ovarian Cancers. Gynecologic Oncology 82, 94–98. - PubMed
-
- Benjamini Y, and Hochberg Y (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society: Series B 57 289–300.
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
