

Repeated Measures Designs and Analysis of Longitudinal Data: If at First You Do Not Succeed-Try, Try Again
- PMID: 29905618
- PMCID: PMC6072386
- DOI: 10.1213/ANE.0000000000003511
Repeated Measures Designs and Analysis of Longitudinal Data: If at First You Do Not Succeed-Try, Try Again
Abstract
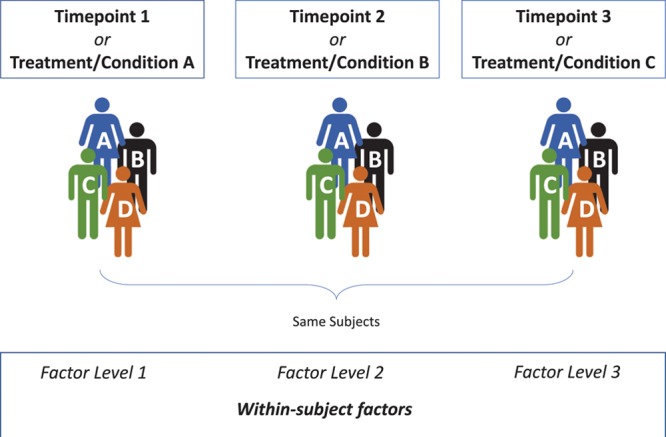
Anesthesia, critical care, perioperative, and pain research often involves study designs in which the same outcome variable is repeatedly measured or observed over time on the same patients. Such repeatedly measured data are referred to as longitudinal data, and longitudinal study designs are commonly used to investigate changes in an outcome over time and to compare these changes among treatment groups. From a statistical perspective, longitudinal studies usually increase the precision of estimated treatment effects, thus increasing the power to detect such effects. Commonly used statistical techniques mostly assume independence of the observations or measurements. However, values repeatedly measured in the same individual will usually be more similar to each other than values of different individuals and ignoring the correlation between repeated measurements may lead to biased estimates as well as invalid P values and confidence intervals. Therefore, appropriate analysis of repeated-measures data requires specific statistical techniques. This tutorial reviews 3 classes of commonly used approaches for the analysis of longitudinal data. The first class uses summary statistics to condense the repeatedly measured information to a single number per subject, thus basically eliminating within-subject repeated measurements and allowing for a straightforward comparison of groups using standard statistical hypothesis tests. The second class is historically popular and comprises the repeated-measures analysis of variance type of analyses. However, strong assumptions that are seldom met in practice and low flexibility limit the usefulness of this approach. The third class comprises modern and flexible regression-based techniques that can be generalized to accommodate a wide range of outcome data including continuous, categorical, and count data. Such methods can be further divided into so-called "population-average statistical models" that focus on the specification of the mean response of the outcome estimated by generalized estimating equations, and "subject-specific models" that allow a full specification of the distribution of the outcome by using random effects to capture within-subject correlations. The choice as to which approach to choose partly depends on the aim of the research and the desired interpretation of the estimated effects (population-average versus subject-specific interpretation). This tutorial discusses aspects of the theoretical background for each technique, and with specific examples of studies published in Anesthesia & Analgesia, demonstrates how these techniques are used in practice.
Conflict of interest statement
The authors declare no conflicts of interest.
Figures



References
-
- Albert PS. Longitudinal data analysis (repeated measures) in clinical trials. Stat Med. 1999;18:1707–1732.. - PubMed
-
- Mascha EJ, Sessler DI. Equivalence and noninferiority testing in regression models and repeated-measures designs. Anesth Analg. 2011;112:678–687.. - PubMed
-
- Zeger SL, Liang KY. An overview of methods for the analysis of longitudinal data. Stat Med. 1992;11:1825–1839.. - PubMed
-
- Vetter TR, Schober P. Regression: the apple does not fall far from the tree. Anesth Analg. 2018;127:277–283.. - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
