

A pan-genome-based machine learning approach for predicting antimicrobial resistance activities of the Escherichia coli strains
- PMID: 29949970
- PMCID: PMC6022653
- DOI: 10.1093/bioinformatics/bty276
A pan-genome-based machine learning approach for predicting antimicrobial resistance activities of the Escherichia coli strains
Abstract
Motivation: Antimicrobial resistance (AMR) is becoming a huge problem in both developed and developing countries, and identifying strains resistant or susceptible to certain antibiotics is essential in fighting against antibiotic-resistant pathogens. Whole-genome sequences have been collected for different microbial strains in order to identify crucial characteristics that allow certain strains to become resistant to antibiotics; however, a global inspection of the gene content responsible for AMR activities remains to be done.
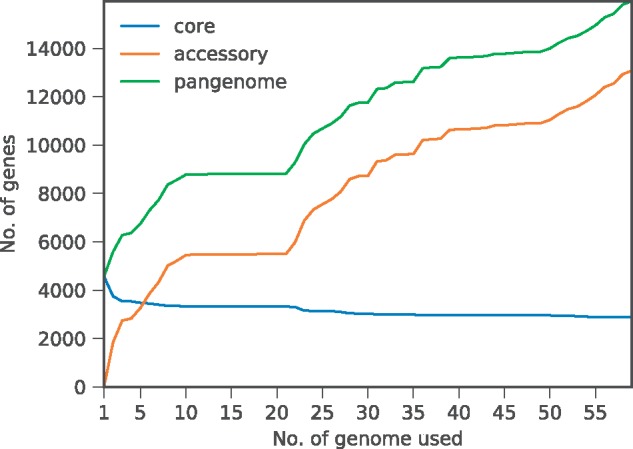
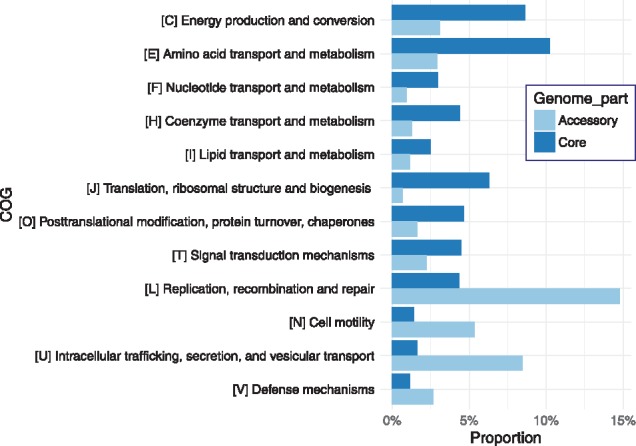
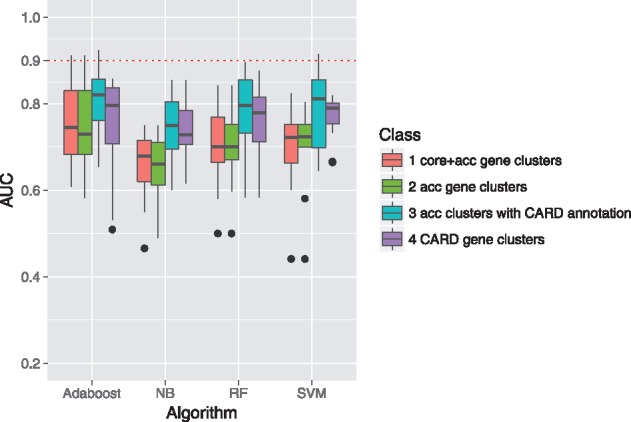
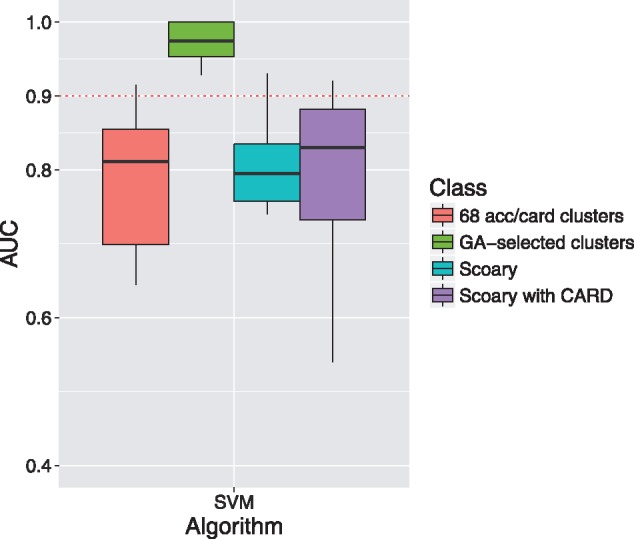
Results: We propose a pan-genome-based approach to characterize antibiotic-resistant microbial strains and test this approach on the bacterial model organism Escherichia coli. By identifying core and accessory gene clusters and predicting AMR genes for the E. coli pan-genome, we not only showed that certain classes of genes are unevenly distributed between the core and accessory parts of the pan-genome but also demonstrated that only a portion of the identified AMR genes belong to the accessory genome. Application of machine learning algorithms to predict whether specific strains were resistant to antibiotic drugs yielded the best prediction accuracy for the set of AMR genes within the accessory part of the pan-genome, suggesting that these gene clusters were most crucial to AMR activities in E. coli. Selecting subsets of AMR genes for different antibiotic drugs based on a genetic algorithm (GA) achieved better prediction performances than the gene sets established in the literature, hinting that the gene sets selected by the GA may warrant further analysis in investigating more details about how E. coli fight against antibiotics.
Supplementary information: Supplementary data are available at Bioinformatics online.
Figures
Similar articles
-
Enhancing predictions of antimicrobial resistance of pathogens by expanding the potential resistance gene repertoire using a pan-genome-based feature selection approach.BMC Bioinformatics. 2022 Apr 15;23(Suppl 4):131. doi: 10.1186/s12859-022-04666-2. BMC Bioinformatics. 2022. PMID: 35428201 Free PMC article.
-
Machine learning with random subspace ensembles identifies antimicrobial resistance determinants from pan-genomes of three pathogens.PLoS Comput Biol. 2020 Mar 2;16(3):e1007608. doi: 10.1371/journal.pcbi.1007608. eCollection 2020 Mar. PLoS Comput Biol. 2020. PMID: 32119670 Free PMC article.
-
VAMPr: VAriant Mapping and Prediction of antibiotic resistance via explainable features and machine learning.PLoS Comput Biol. 2020 Jan 13;16(1):e1007511. doi: 10.1371/journal.pcbi.1007511. eCollection 2020 Jan. PLoS Comput Biol. 2020. PMID: 31929521 Free PMC article.
-
Machine learning: novel bioinformatics approaches for combating antimicrobial resistance.Curr Opin Infect Dis. 2017 Dec;30(6):511-517. doi: 10.1097/QCO.0000000000000406. Curr Opin Infect Dis. 2017. PMID: 28914640 Review.
-
Innovations in genomic antimicrobial resistance surveillance.Lancet Microbe. 2023 Dec;4(12):e1063-e1070. doi: 10.1016/S2666-5247(23)00285-9. Epub 2023 Nov 14. Lancet Microbe. 2023. PMID: 37977163 Review.
Cited by
-
Silicon versus Superbug: Assessing Machine Learning's Role in the Fight against Antimicrobial Resistance.Antibiotics (Basel). 2023 Nov 8;12(11):1604. doi: 10.3390/antibiotics12111604. Antibiotics (Basel). 2023. PMID: 37998806 Free PMC article. Review.
-
Artificial Intelligence for Antimicrobial Resistance Prediction: Challenges and Opportunities towards Practical Implementation.Antibiotics (Basel). 2023 Mar 6;12(3):523. doi: 10.3390/antibiotics12030523. Antibiotics (Basel). 2023. PMID: 36978390 Free PMC article. Review.
-
Assessing computational predictions of antimicrobial resistance phenotypes from microbial genomes.Brief Bioinform. 2024 Mar 27;25(3):bbae206. doi: 10.1093/bib/bbae206. Brief Bioinform. 2024. PMID: 38706320 Free PMC article.
-
A genomic data resource for predicting antimicrobial resistance from laboratory-derived antimicrobial susceptibility phenotypes.Brief Bioinform. 2021 Nov 5;22(6):bbab313. doi: 10.1093/bib/bbab313. Brief Bioinform. 2021. PMID: 34379107 Free PMC article.
-
Artificial intelligence in drug resistance management.3 Biotech. 2025 May;15(5):126. doi: 10.1007/s13205-025-04282-w. Epub 2025 Apr 14. 3 Biotech. 2025. PMID: 40235844 Free PMC article. Review.
References
-
- Angelova M. et al. (2010) Computational methods for gene finding in prokaryotes In: Gusev M. (ed.) ICT Innovations 2010. Ohrid, Macedonia, Springer, pp. 11–20.
-
- Cormican M., Vellinga A. (2012) Existing classes of antibiotics are probably the best we will ever have. Brit. Med. J., 344, e3369.. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
