

Prioritizing network communities
- PMID: 29959323
- PMCID: PMC6026212
- DOI: 10.1038/s41467-018-04948-5
Prioritizing network communities
Abstract
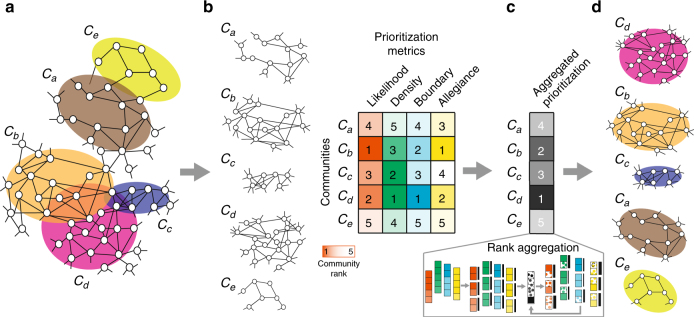
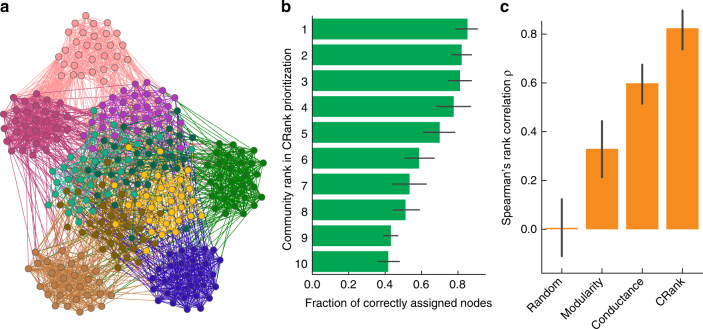
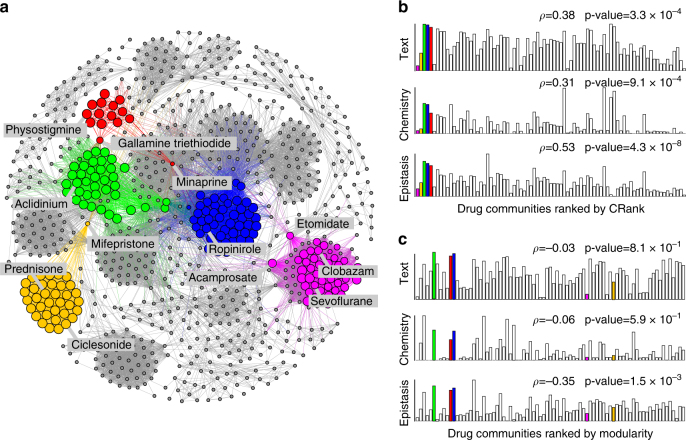
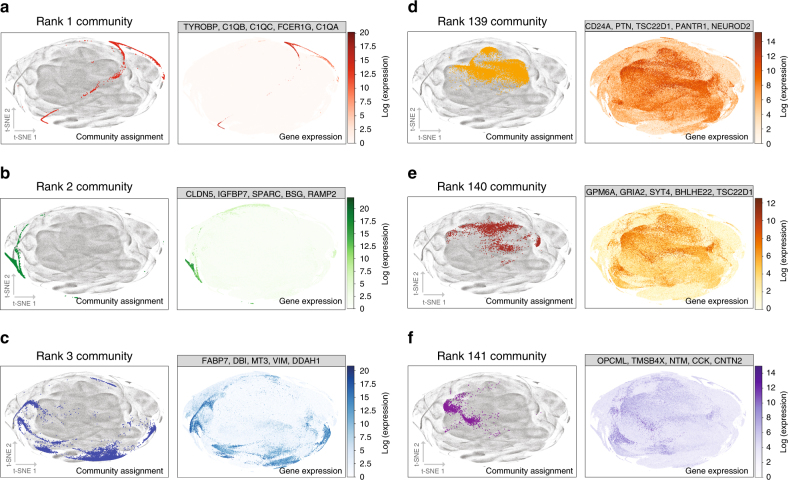
Uncovering modular structure in networks is fundamental for systems in biology, physics, and engineering. Community detection identifies candidate modules as hypotheses, which then need to be validated through experiments, such as mutagenesis in a biological laboratory. Only a few communities can typically be validated, and it is thus important to prioritize which communities to select for downstream experimentation. Here we develop CRANK, a mathematically principled approach for prioritizing network communities. CRANK efficiently evaluates robustness and magnitude of structural features of each community and then combines these features into the community prioritization. CRANK can be used with any community detection method. It needs only information provided by the network structure and does not require any additional metadata or labels. However, when available, CRANK can incorporate domain-specific information to further boost performance. Experiments on many large networks show that CRANK effectively prioritizes communities, yielding a nearly 50-fold improvement in community prioritization.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Fortunato S. Community detection in graphs. Phys. Rep. 2010;486:75–174. doi: 10.1016/j.physrep.2009.11.002. - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
