

Neural signatures of reinforcement learning correlate with strategy adoption during spatial navigation
- PMID: 29973606
- PMCID: PMC6031619
- DOI: 10.1038/s41598-018-28241-z
Neural signatures of reinforcement learning correlate with strategy adoption during spatial navigation
Abstract
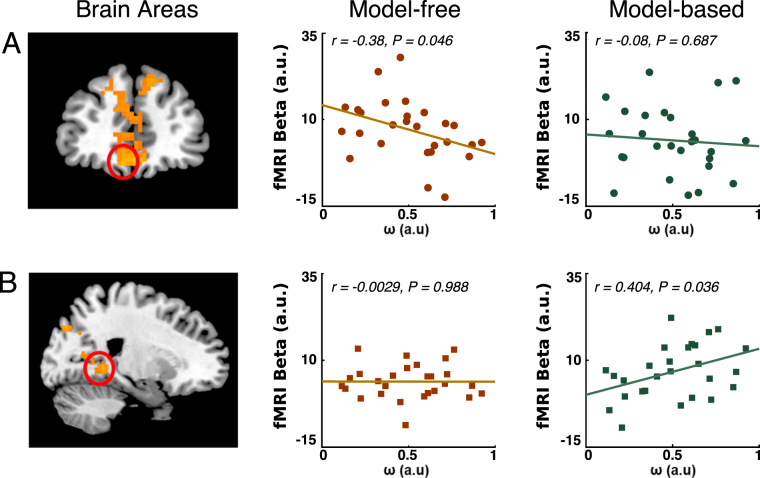
Human navigation is generally believed to rely on two types of strategy adoption, route-based and map-based strategies. Both types of navigation require making spatial decisions along the traversed way although formal computational and neural links between navigational strategies and mechanisms of value-based decision making have so far been underexplored in humans. Here we employed functional magnetic resonance imaging (fMRI) while subjects located different objects in a virtual environment. We then modelled their paths using reinforcement learning (RL) algorithms, which successfully explained decision behavior and its neural correlates. Our results show that subjects used a mixture of route and map-based navigation and their paths could be well explained by the model-free and model-based RL algorithms. Furthermore, the value signals of model-free choices during route-based navigation modulated the BOLD signals in the ventro-medial prefrontal cortex (vmPFC), whereas the BOLD signals in parahippocampal and hippocampal regions pertained to model-based value signals during map-based navigation. Our findings suggest that the brain might share computational mechanisms and neural substrates for navigation and value-based decisions such that model-free choice guides route-based navigation and model-based choice directs map-based navigation. These findings open new avenues for computational modelling of wayfinding by directing attention to value-based decision, differing from common direction and distances approaches.
Conflict of interest statement
The authors declare no competing interests.
Figures
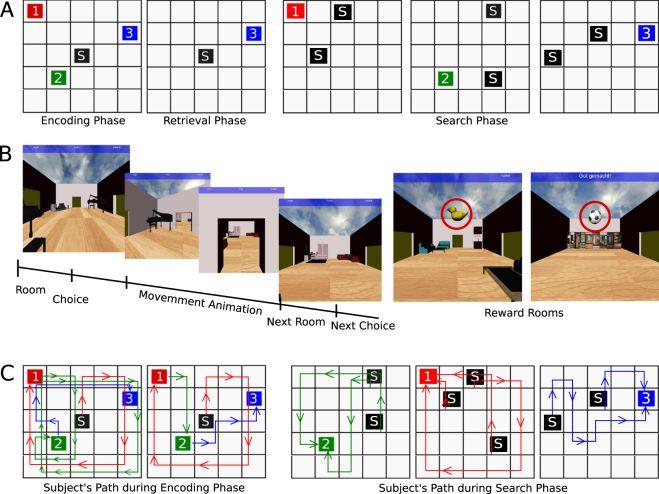
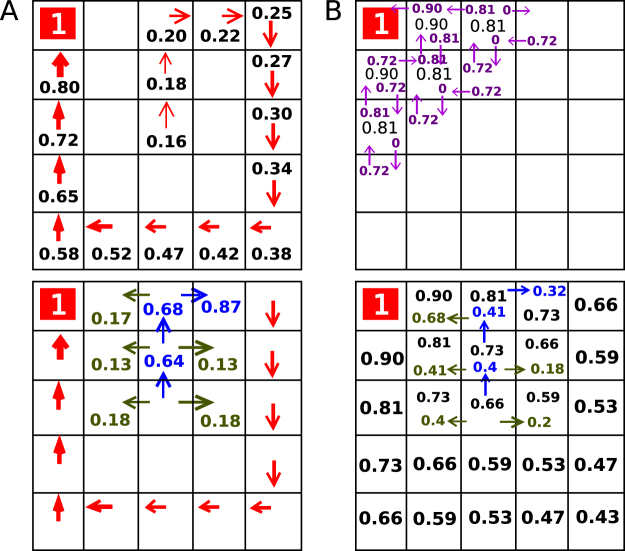
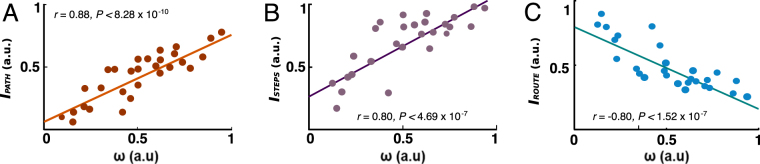
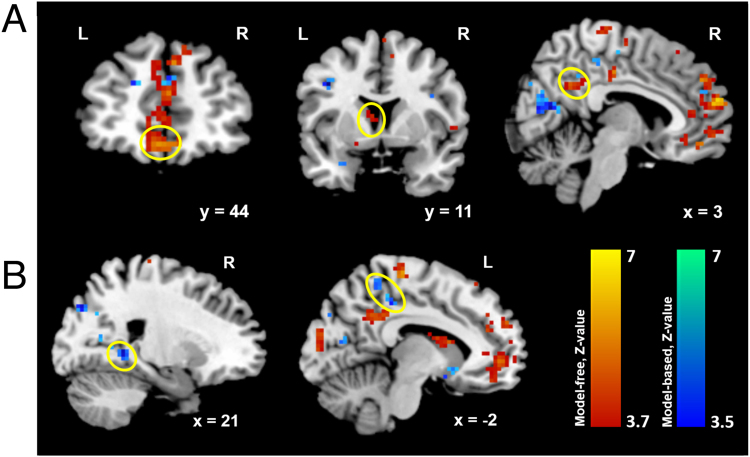
References
-
- Iaria G, Petrides M, Dagher A, Pike B, Bohbot VD. Cognitive strategies dependent on the hippocampus and caudate nucleus in human navigation: variability and change with practice. The Journal of neuroscience: the official journal of the Society for Neuroscience. 2003;23:5945–5952. doi: 10.1523/JNEUROSCI.23-13-05945.2003. - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
