

Large-Scale, High-Resolution Comparison of the Core Visual Object Recognition Behavior of Humans, Monkeys, and State-of-the-Art Deep Artificial Neural Networks
- PMID: 30006365
- PMCID: PMC6096043
- DOI: 10.1523/JNEUROSCI.0388-18.2018
Large-Scale, High-Resolution Comparison of the Core Visual Object Recognition Behavior of Humans, Monkeys, and State-of-the-Art Deep Artificial Neural Networks
Abstract
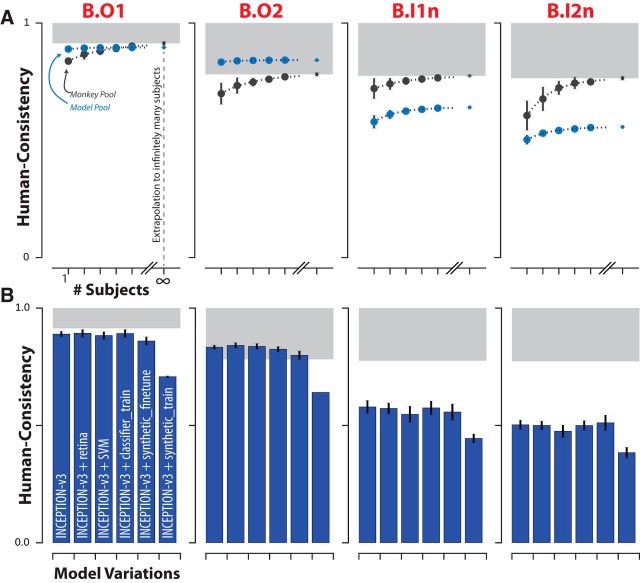
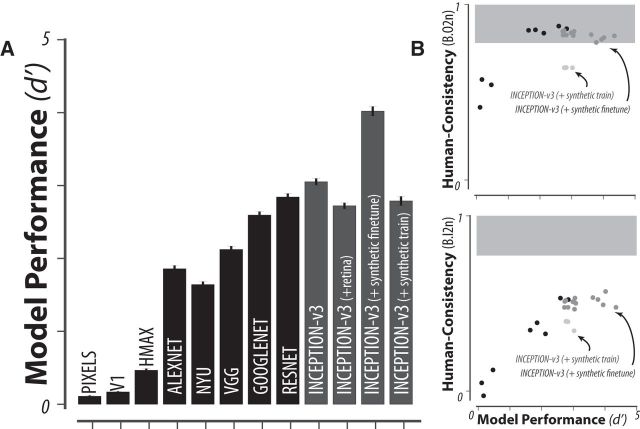
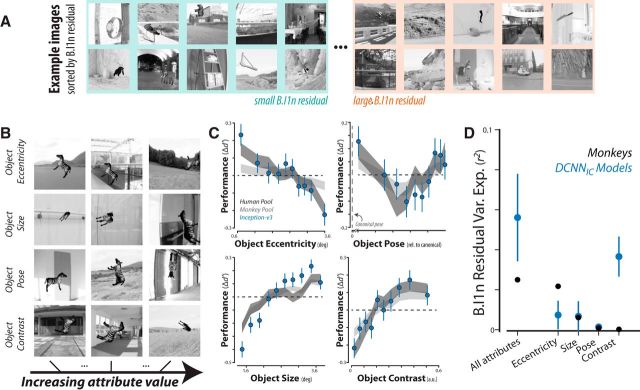
Primates, including humans, can typically recognize objects in visual images at a glance despite naturally occurring identity-preserving image transformations (e.g., changes in viewpoint). A primary neuroscience goal is to uncover neuron-level mechanistic models that quantitatively explain this behavior by predicting primate performance for each and every image. Here, we applied this stringent behavioral prediction test to the leading mechanistic models of primate vision (specifically, deep, convolutional, artificial neural networks; ANNs) by directly comparing their behavioral signatures against those of humans and rhesus macaque monkeys. Using high-throughput data collection systems for human and monkey psychophysics, we collected more than one million behavioral trials from 1472 anonymous humans and five male macaque monkeys for 2400 images over 276 binary object discrimination tasks. Consistent with previous work, we observed that state-of-the-art deep, feedforward convolutional ANNs trained for visual categorization (termed DCNNIC models) accurately predicted primate patterns of object-level confusion. However, when we examined behavioral performance for individual images within each object discrimination task, we found that all tested DCNNIC models were significantly nonpredictive of primate performance and that this prediction failure was not accounted for by simple image attributes nor rescued by simple model modifications. These results show that current DCNNIC models cannot account for the image-level behavioral patterns of primates and that new ANN models are needed to more precisely capture the neural mechanisms underlying primate object vision. To this end, large-scale, high-resolution primate behavioral benchmarks such as those obtained here could serve as direct guides for discovering such models.SIGNIFICANCE STATEMENT Recently, specific feedforward deep convolutional artificial neural networks (ANNs) models have dramatically advanced our quantitative understanding of the neural mechanisms underlying primate core object recognition. In this work, we tested the limits of those ANNs by systematically comparing the behavioral responses of these models with the behavioral responses of humans and monkeys at the resolution of individual images. Using these high-resolution metrics, we found that all tested ANN models significantly diverged from primate behavior. Going forward, these high-resolution, large-scale primate behavioral benchmarks could serve as direct guides for discovering better ANN models of the primate visual system.
Keywords: deep neural network; human; monkey; object recognition; vision.
Copyright © 2018 the authors 0270-6474/18/387255-15$15.00/0.
Figures




References
-
- Battleday RM, Peterson JC, Griffiths TL (2017) Modeling human categorization of natural images using deep feature representations. arXiv preprint arXiv:171104855. Advance online publication. Retrieved Nov 13, 2017. Available at https://arxiv.org/abs/1711.04855.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources