

Combining Similarity Searching and Network Analysis for the Identification of Active Compounds
- PMID: 30023879
- PMCID: PMC6044633
- DOI: 10.1021/acsomega.8b00344
Combining Similarity Searching and Network Analysis for the Identification of Active Compounds
Abstract
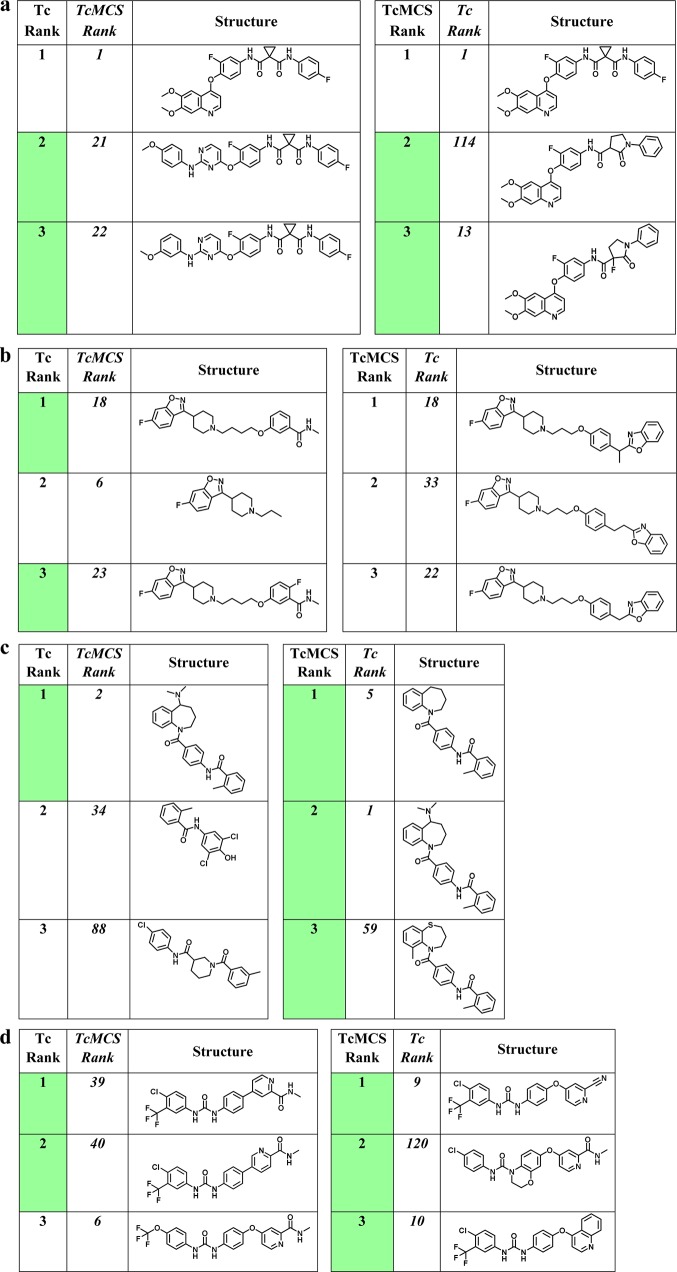
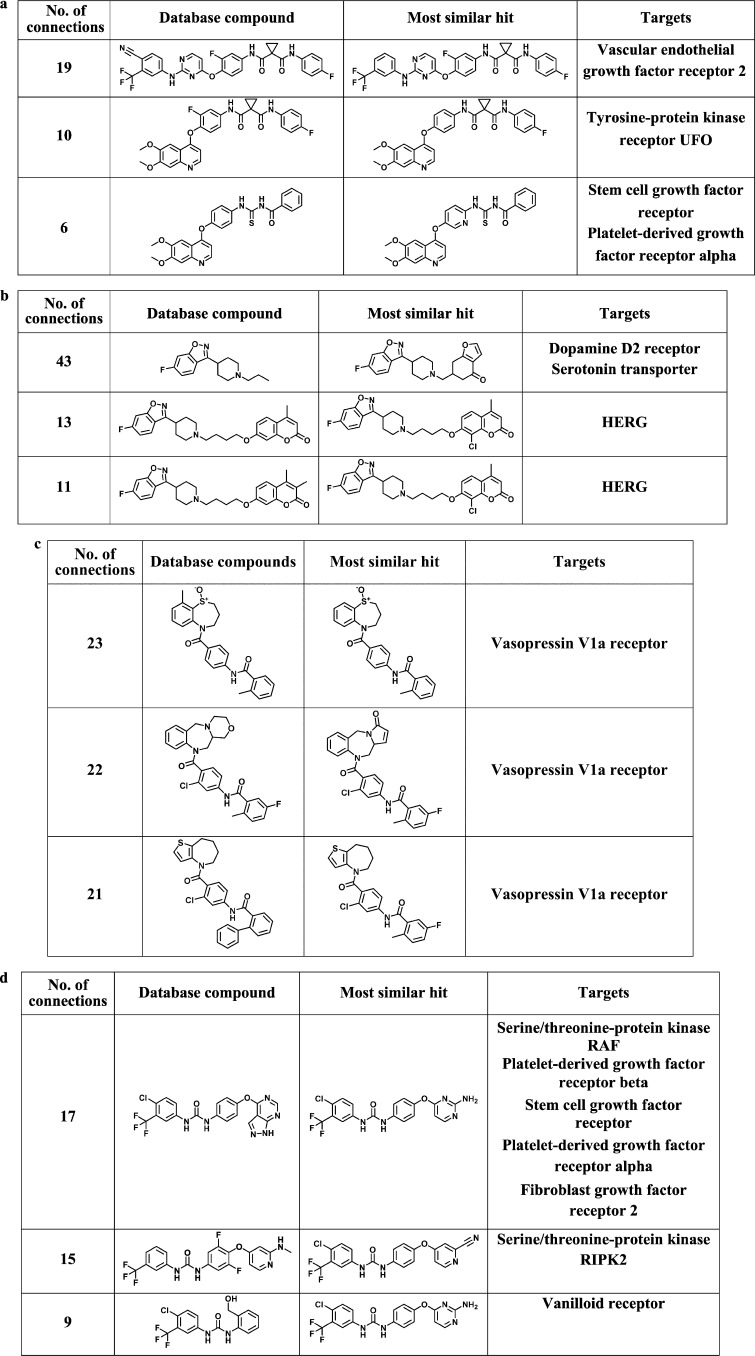
A variety of computational screening methods generate similarity-based compound rankings for hit identification. However, these rankings are difficult to interpret. It is essentially impossible to determine where novel active compounds might be found in database rankings. Thus, compound selection largely depends on intuition and guesswork. Herein, we show that molecular networks can substantially aid in the analysis of similarity-based compound rankings. A series of networks generated for rankings provides visual access to search results and adds chemical neighborhood and context information for reference compounds that are not available in rankings. Network structure is shown to serve as a diagnostic criterion for the likelihood to successfully select active compounds from rankings. In addition, comparison of different networks makes it possible to prioritize alternative similarity measures for search calculations and optimize the enrichment of active compounds in rankings.
Conflict of interest statement
The authors declare no competing financial interest.
Figures
References
LinkOut - more resources
Full Text Sources
Other Literature Sources
