

Enhancing coevolution-based contact prediction by imposing structural self-consistency of the contacts
- PMID: 30042380
- PMCID: PMC6057941
- DOI: 10.1038/s41598-018-29357-y
Enhancing coevolution-based contact prediction by imposing structural self-consistency of the contacts
Abstract
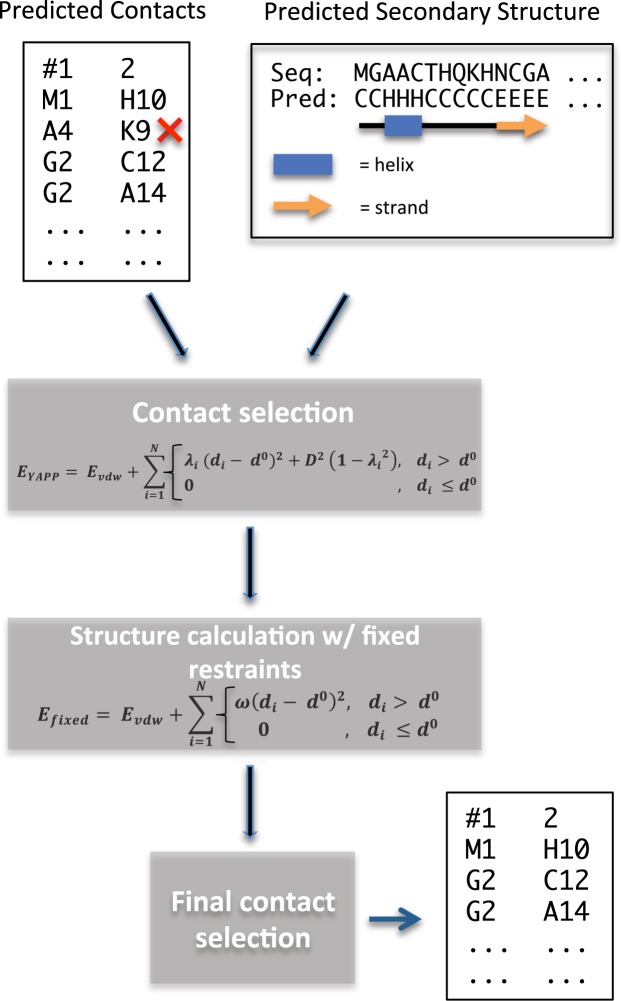
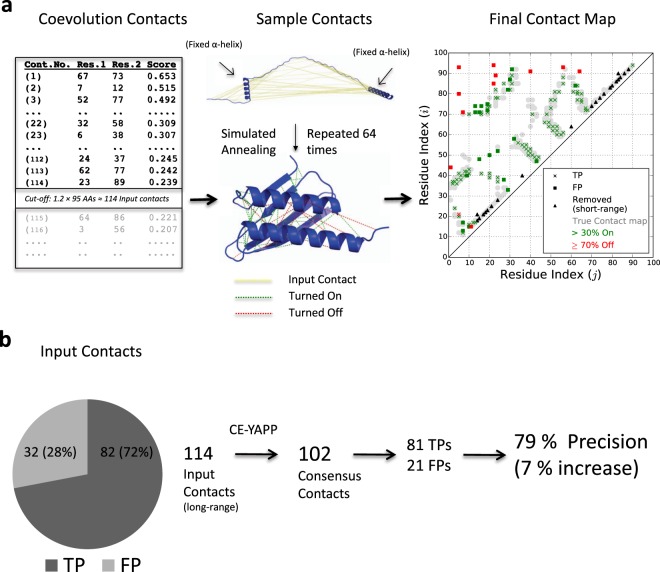
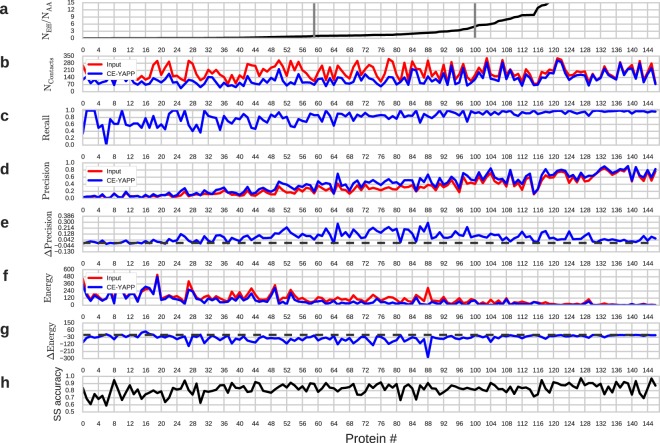
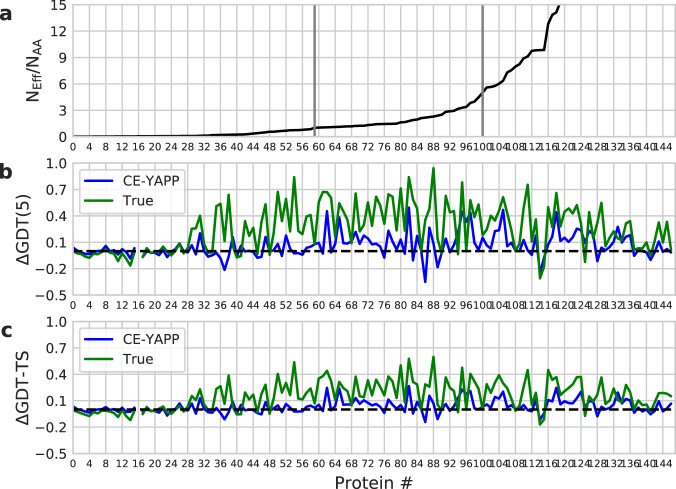
Based on the development of new algorithms and growth of sequence databases, it has recently become possible to build robust higher-order sequence models based on sets of aligned protein sequences. Such models have proven useful in de novo structure prediction, where the sequence models are used to find pairs of residues that co-vary during evolution, and hence are likely to be in spatial proximity in the native protein. The accuracy of these algorithms, however, drop dramatically when the number of sequences in the alignment is small. We have developed a method that we termed CE-YAPP (CoEvolution-YAPP), that is based on YAPP (Yet Another Peak Processor), which has been shown to solve a similar problem in NMR spectroscopy. By simultaneously performing structure prediction and contact assignment, CE-YAPP uses structural self-consistency as a filter to remove false positive contacts. Furthermore, CE-YAPP solves another problem, namely how many contacts to choose from the ordered list of covarying amino acid pairs. We show that CE-YAPP consistently improves contact prediction from multiple sequence alignments, in particular for proteins that are difficult targets. We further show that the structures determined from CE-YAPP are also in better agreement with those determined using traditional methods in structural biology.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
