

Recent advances and prospects of computational methods for metabolite identification: a review with emphasis on machine learning approaches
- PMID: 30099485
- PMCID: PMC6954430
- DOI: 10.1093/bib/bby066
Recent advances and prospects of computational methods for metabolite identification: a review with emphasis on machine learning approaches
Abstract
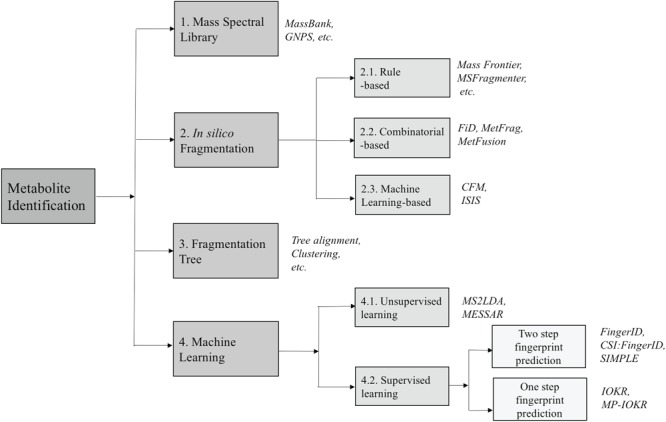
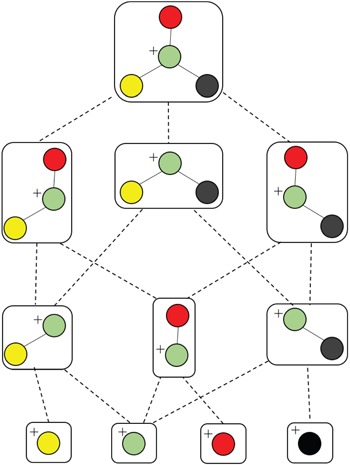
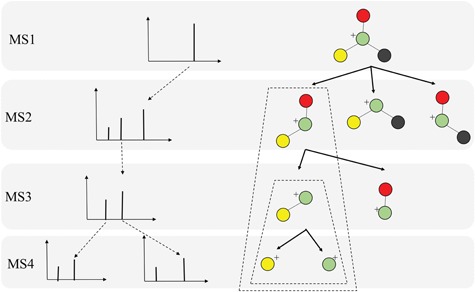
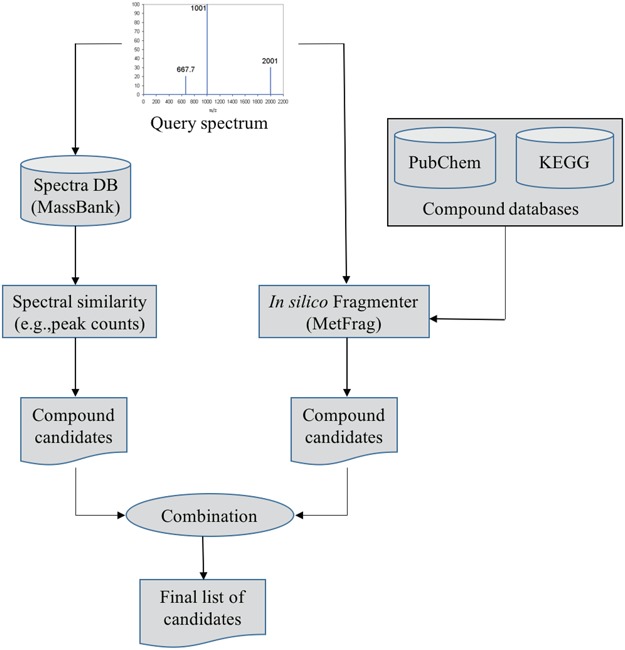
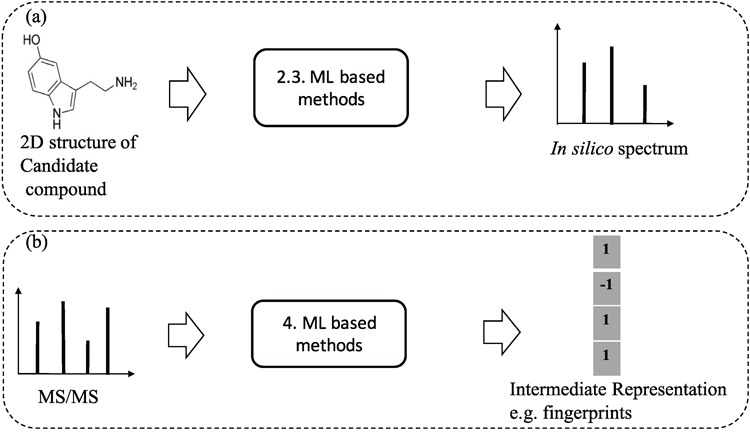
Metabolomics involves studies of a great number of metabolites, which are small molecules present in biological systems. They play a lot of important functions such as energy transport, signaling, building block of cells and inhibition/catalysis. Understanding biochemical characteristics of the metabolites is an essential and significant part of metabolomics to enlarge the knowledge of biological systems. It is also the key to the development of many applications and areas such as biotechnology, biomedicine or pharmaceuticals. However, the identification of the metabolites remains a challenging task in metabolomics with a huge number of potentially interesting but unknown metabolites. The standard method for identifying metabolites is based on the mass spectrometry (MS) preceded by a separation technique. Over many decades, many techniques with different approaches have been proposed for MS-based metabolite identification task, which can be divided into the following four groups: mass spectra database, in silico fragmentation, fragmentation tree and machine learning. In this review paper, we thoroughly survey currently available tools for metabolite identification with the focus on in silico fragmentation, and machine learning-based approaches. We also give an intensive discussion on advanced machine learning methods, which can lead to further improvement on this task.
Keywords: machine learning; mass spectrometry; substructure annotation; substructure prediction.
© The Author(s) 2018. Published by Oxford University Press.
Figures
References
-
- Allen F, Greiner R, Wishart D. Competitive fragmentation modeling of ESI-MS/MS spectra for putative metabolite identification. Metabolomics 2015;11(1):98–110.
-
- Blei DM, Ng AY, Jordan MI. Latent dirichlet allocation. J Mach Learn Res 2003;3(Jan):993–1022.
-
- Böcker S, Rasche F. Towards de novo identification of metabolites by analyzing tandem mass spectra. Bioinformatics 2008;24(16):i49–55. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
