

MoDL: Model-Based Deep Learning Architecture for Inverse Problems
- PMID: 30106719
- PMCID: PMC6760673
- DOI: 10.1109/TMI.2018.2865356
MoDL: Model-Based Deep Learning Architecture for Inverse Problems
Abstract
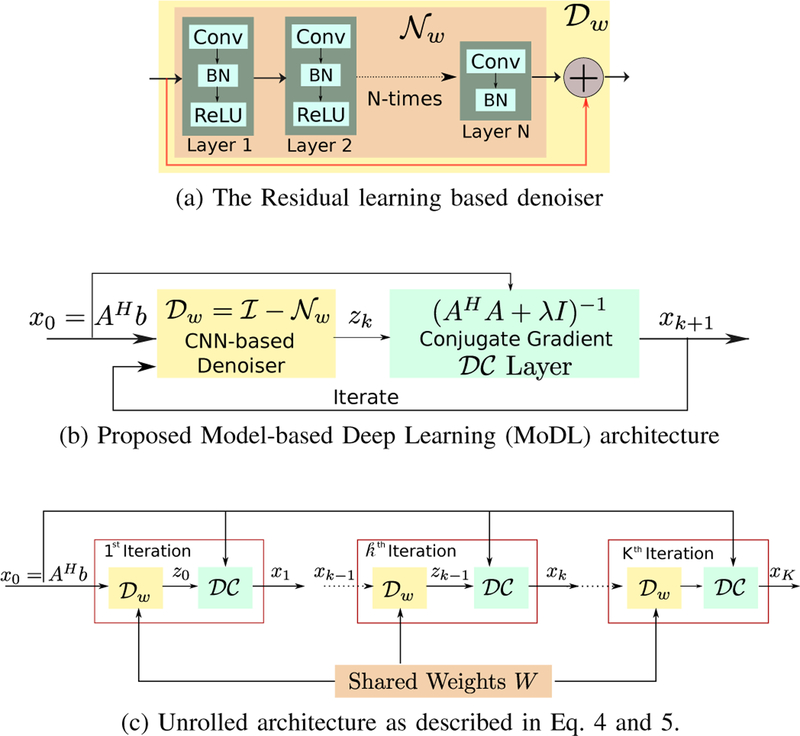
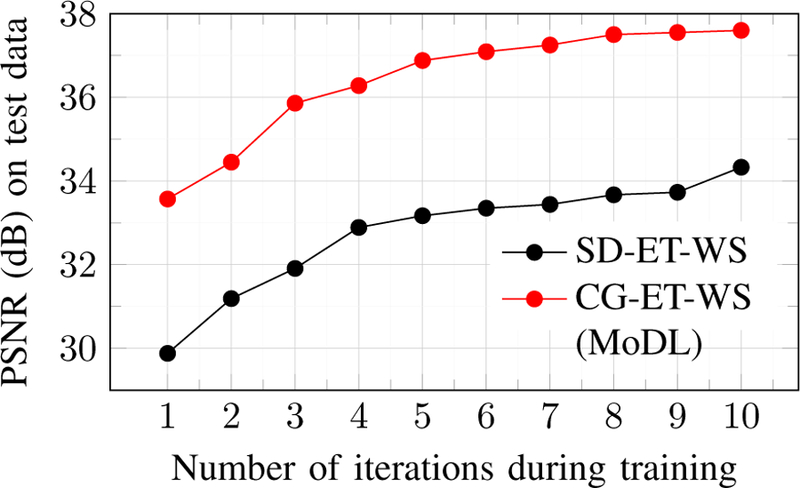
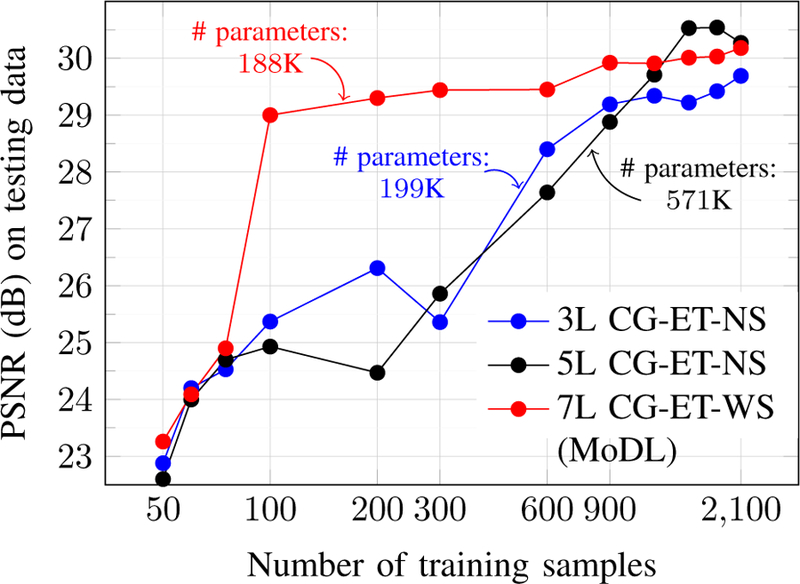
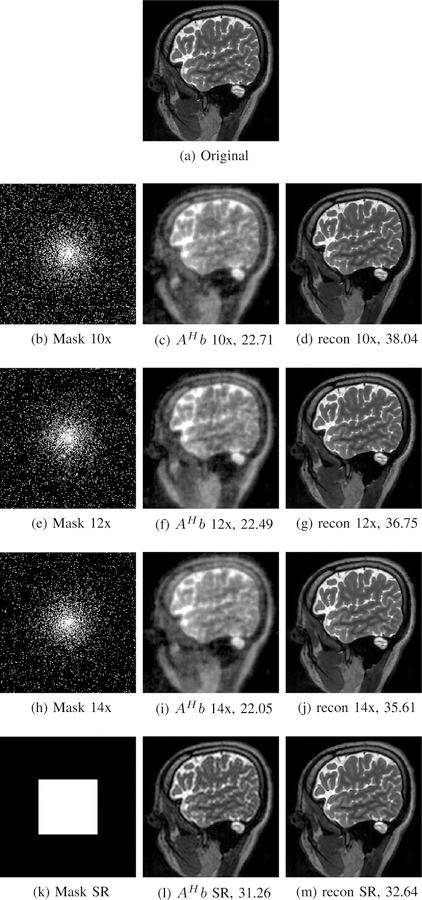
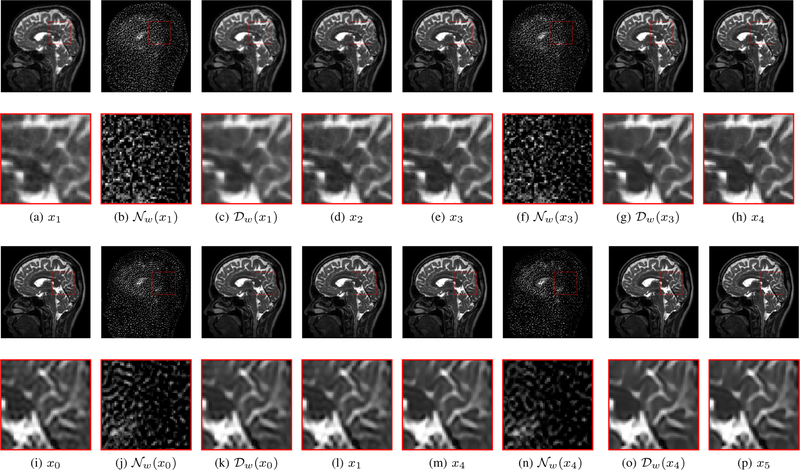
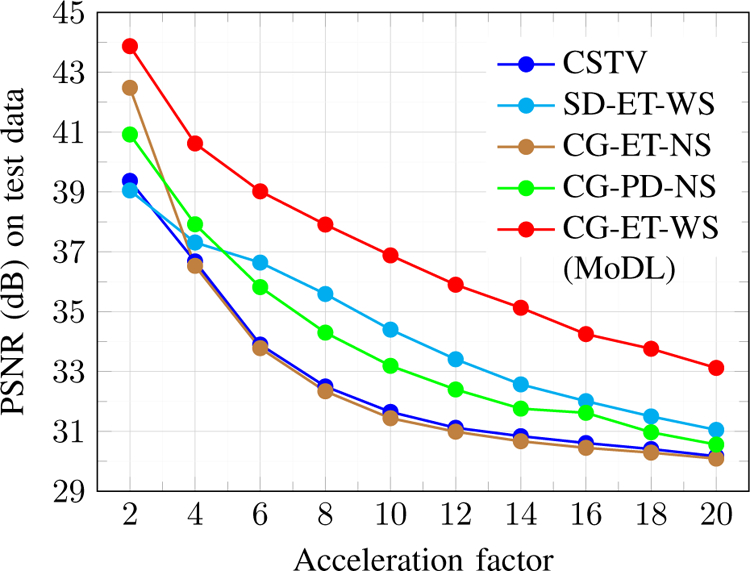
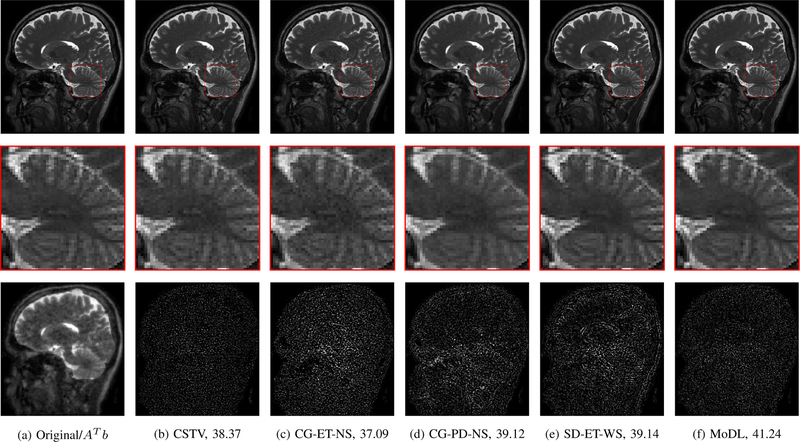
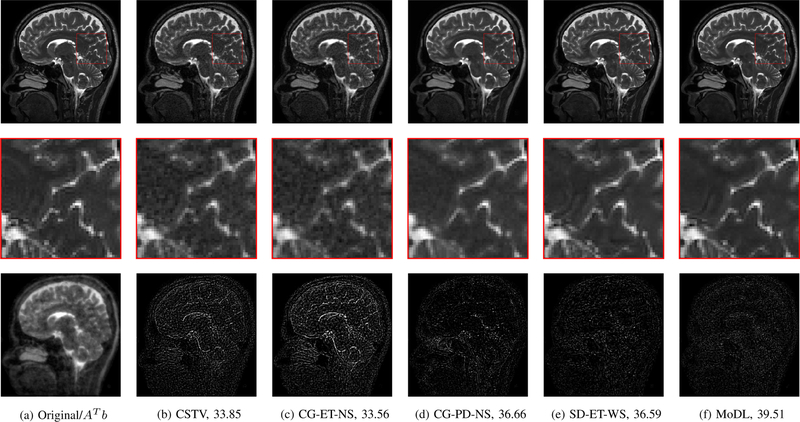
We introduce a model-based image reconstruction framework with a convolution neural network (CNN)-based regularization prior. The proposed formulation provides a systematic approach for deriving deep architectures for inverse problems with the arbitrary structure. Since the forward model is explicitly accounted for, a smaller network with fewer parameters is sufficient to capture the image information compared to direct inversion approaches. Thus, reducing the demand for training data and training time. Since we rely on end-to-end training with weight sharing across iterations, the CNN weights are customized to the forward model, thus offering improved performance over approaches that rely on pre-trained denoisers. Our experiments show that the decoupling of the number of iterations from the network complexity offered by this approach provides benefits, including lower demand for training data, reduced risk of overfitting, and implementations with significantly reduced memory footprint. We propose to enforce data-consistency by using numerical optimization blocks, such as conjugate gradients algorithm within the network. This approach offers faster convergence per iteration, compared to methods that rely on proximal gradients steps to enforce data consistency. Our experiments show that the faster convergence translates to improved performance, primarily when the available GPU memory restricts the number of iterations.
Figures
References
-
- Elbakri IA and Fessler JA, “Statistical image reconstruction for polyenergetic x-ray computed tomography,” IEEE Trans. Med. Imag, vol. 21, no. 2, pp. 89–99, 2002. - PubMed
-
- Verhaeghe J, Van De Ville D, Khalidov I, D’Asseler Y, Lemahieu I, and Unser M, “Dynamic PET reconstruction using wavelet regularization with adapted basis functions,” IEEE Trans. Med. Imag, vol. 27, no. 7, pp. 943–959, July 2008. - PubMed
-
- Aguet F, Van De Ville D, and Unser M, “Model-based 2.5-D deconvolution for extended depth of field in brightfield microscopy,” IEEE Trans. Image Process, vol. 17, no. 7, pp. 1144–1153, July 2008. - PubMed
-
- Ma S, Yin W, Zhang Y, and Chakraborty A, “An Efficient Algorithm for Compressed MR Imaging using Total Variation and Wavelets,” in Computer Vision and Pattern Recognition, 2008, pp. 1–8.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
