

Dorsal anterior cingulate-brainstem ensemble as a reinforcement meta-learner
- PMID: 30142152
- PMCID: PMC6126878
- DOI: 10.1371/journal.pcbi.1006370
Dorsal anterior cingulate-brainstem ensemble as a reinforcement meta-learner
Abstract
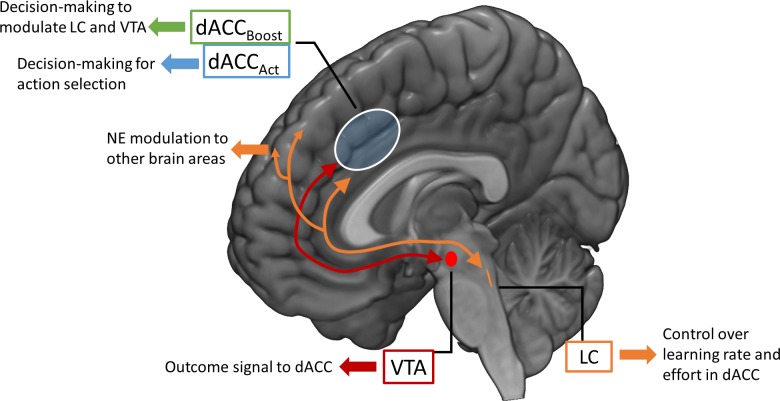
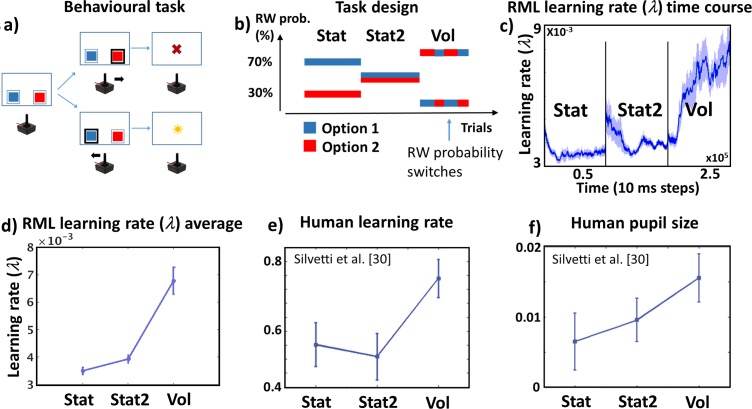
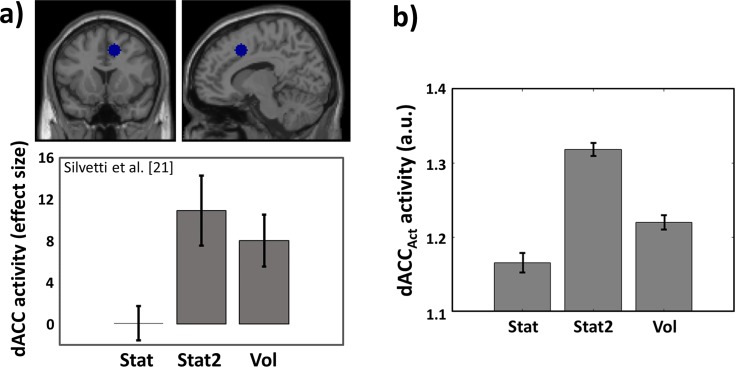
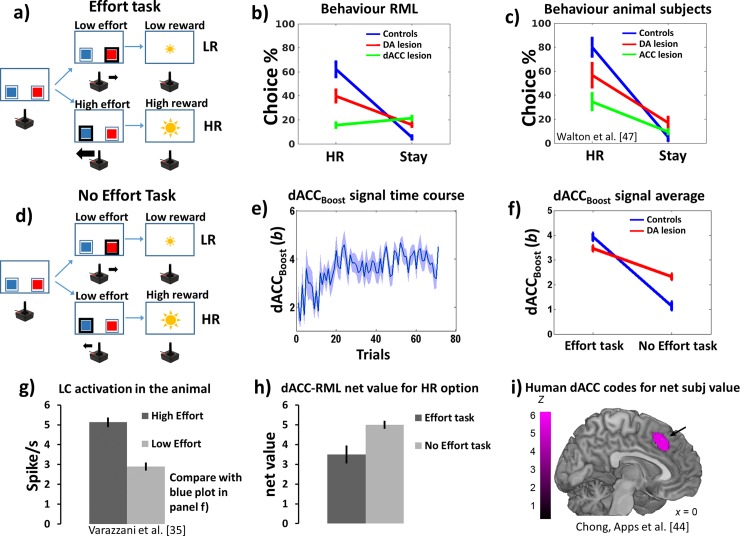
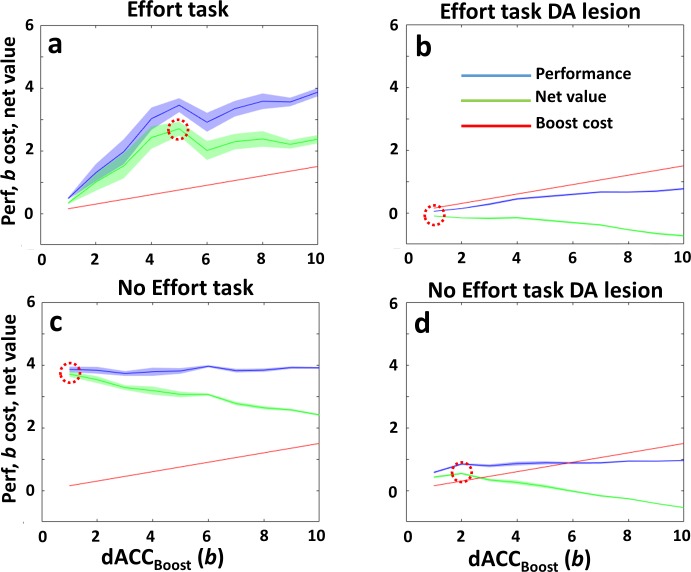
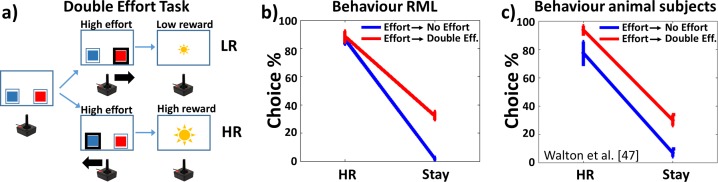
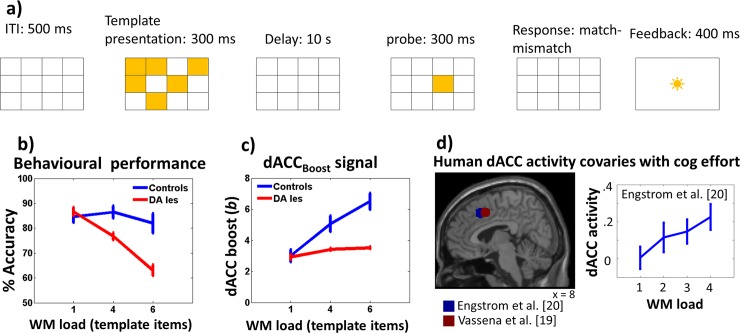
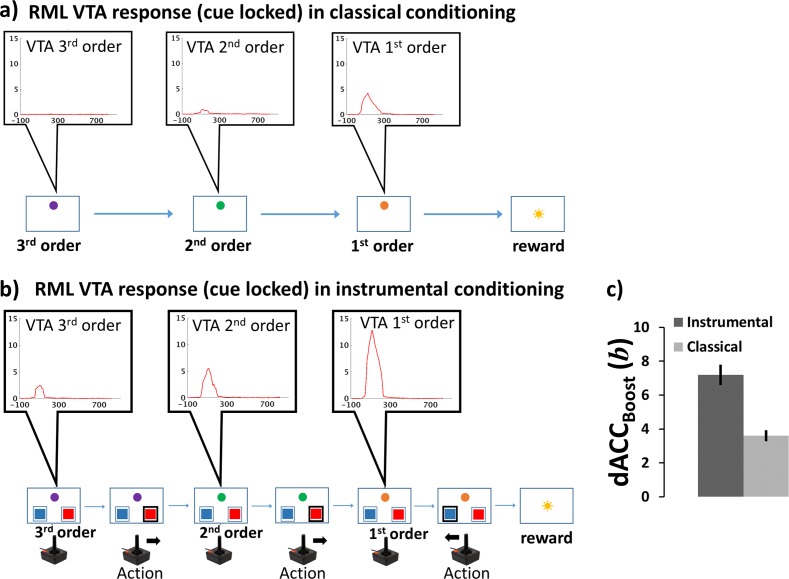
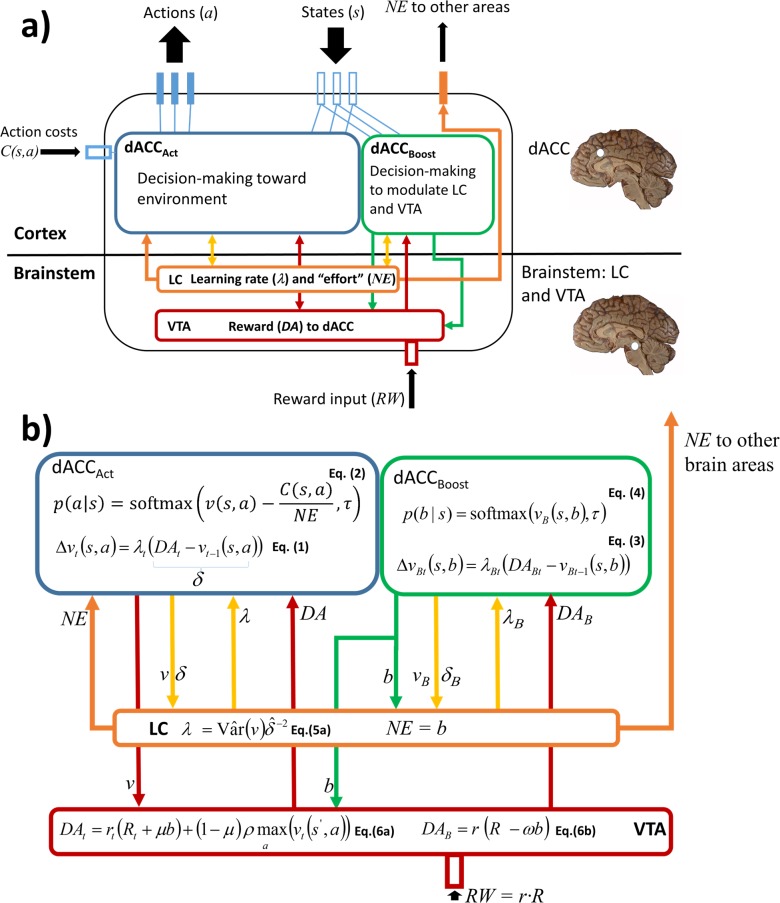
Optimal decision-making is based on integrating information from several dimensions of decisional space (e.g., reward expectation, cost estimation, effort exertion). Despite considerable empirical and theoretical efforts, the computational and neural bases of such multidimensional integration have remained largely elusive. Here we propose that the current theoretical stalemate may be broken by considering the computational properties of a cortical-subcortical circuit involving the dorsal anterior cingulate cortex (dACC) and the brainstem neuromodulatory nuclei: ventral tegmental area (VTA) and locus coeruleus (LC). From this perspective, the dACC optimizes decisions about stimuli and actions, and using the same computational machinery, it also modulates cortical functions (meta-learning), via neuromodulatory control (VTA and LC). We implemented this theory in a novel neuro-computational model-the Reinforcement Meta Learner (RML). We outline how the RML captures critical empirical findings from an unprecedented range of theoretical domains, and parsimoniously integrates various previous proposals on dACC functioning.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Frank MJ, Seeberger LC, O’Reilly R C. By carrot or by stick: cognitive reinforcement learning in parkinsonism. Science (80-). 2004;306: 1940–1943. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
