

Variable selection and validation in multivariate modelling
- PMID: 30165467
- PMCID: PMC6419897
- DOI: 10.1093/bioinformatics/bty710
Variable selection and validation in multivariate modelling
Abstract
Motivation: Validation of variable selection and predictive performance is crucial in construction of robust multivariate models that generalize well, minimize overfitting and facilitate interpretation of results. Inappropriate variable selection leads instead to selection bias, thereby increasing the risk of model overfitting and false positive discoveries. Although several algorithms exist to identify a minimal set of most informative variables (i.e. the minimal-optimal problem), few can select all variables related to the research question (i.e. the all-relevant problem). Robust algorithms combining identification of both minimal-optimal and all-relevant variables with proper cross-validation are urgently needed.
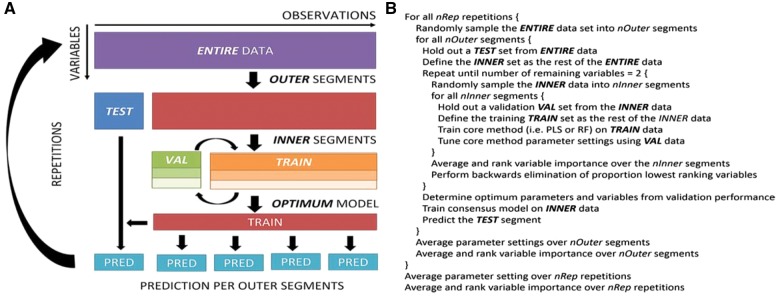
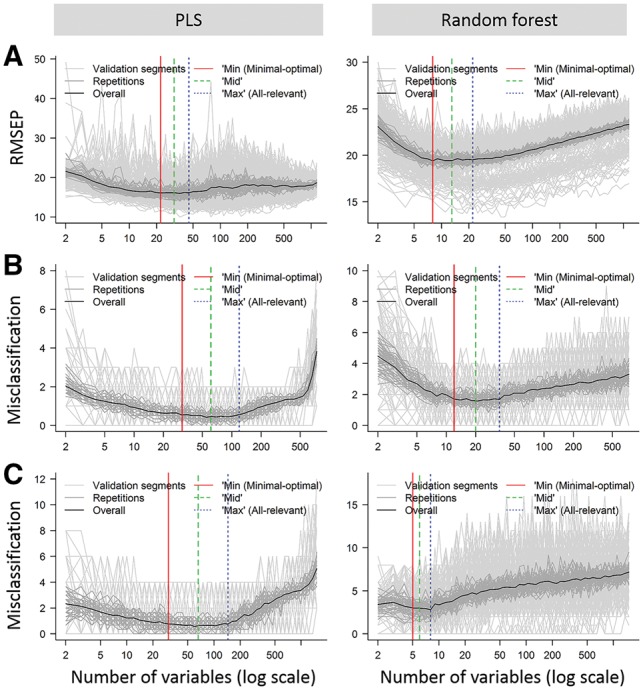
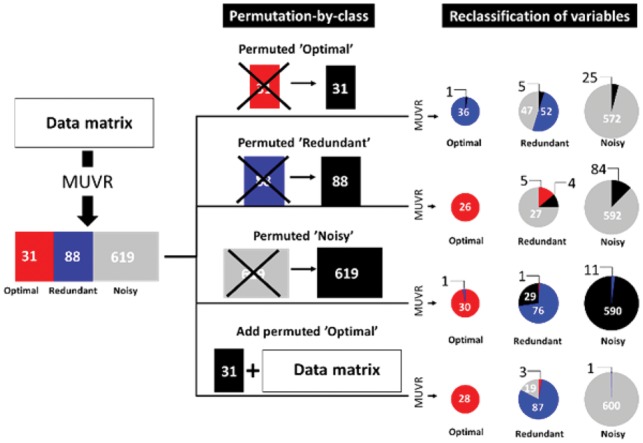
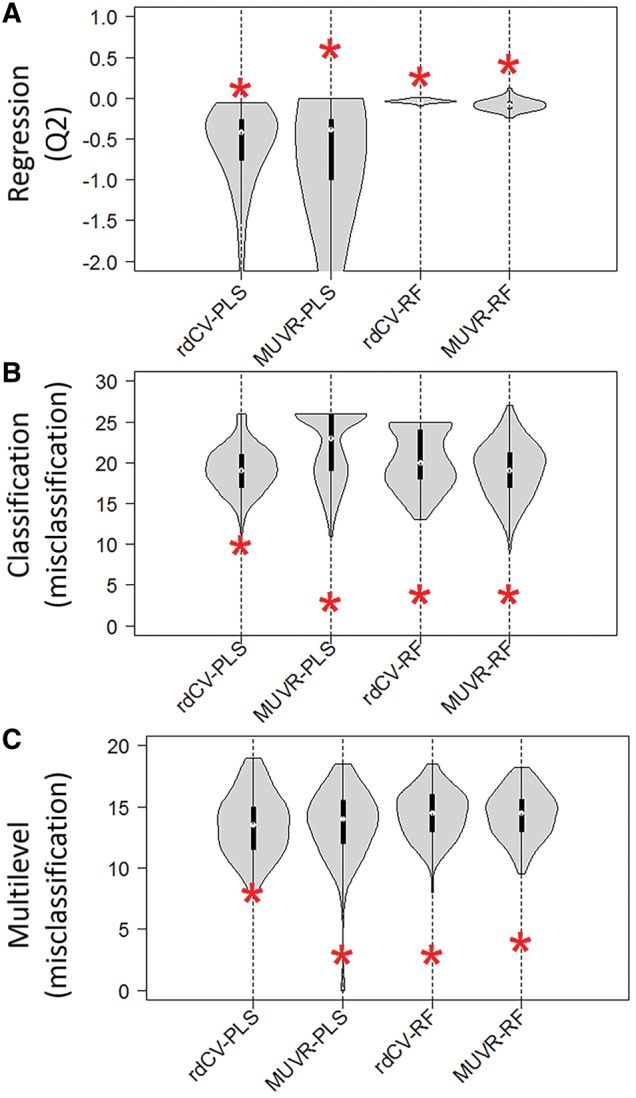
Results: We developed the MUVR algorithm to improve predictive performance and minimize overfitting and false positives in multivariate analysis. In the MUVR algorithm, minimal variable selection is achieved by performing recursive variable elimination in a repeated double cross-validation (rdCV) procedure. The algorithm supports partial least squares and random forest modelling, and simultaneously identifies minimal-optimal and all-relevant variable sets for regression, classification and multilevel analyses. Using three authentic omics datasets, MUVR yielded parsimonious models with minimal overfitting and improved model performance compared with state-of-the-art rdCV. Moreover, MUVR showed advantages over other variable selection algorithms, i.e. Boruta and VSURF, including simultaneous variable selection and validation scheme and wider applicability.
Availability and implementation: Algorithms, data, scripts and tutorial are open source and available as an R package ('MUVR') at https://gitlab.com/CarlBrunius/MUVR.git.
Supplementary information: Supplementary data are available at Bioinformatics online.
© The Author(s) 2018. Published by Oxford University Press.
Figures
References
-
- Afanador N.L. (2016) Unsupervised random forest: a tutorial with case studies. J. Chemom., 30, 231–241.
-
- Boulesteix A.L. (2007) WilcoxCV: an R package for fast variable selection in cross-validation. Bioinformatics, 23, 1702–1704. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
