

EPA-ng: Massively Parallel Evolutionary Placement of Genetic Sequences
- PMID: 30165689
- PMCID: PMC6368480
- DOI: 10.1093/sysbio/syy054
EPA-ng: Massively Parallel Evolutionary Placement of Genetic Sequences
Abstract
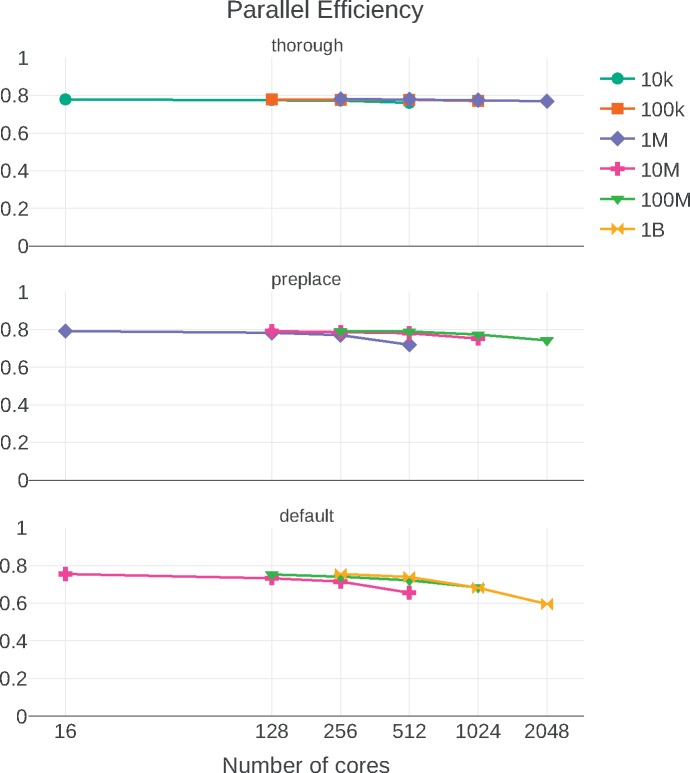
Next generation sequencing (NGS) technologies have led to a ubiquity of molecular sequence data. This data avalanche is particularly challenging in metagenetics, which focuses on taxonomic identification of sequences obtained from diverse microbial environments. Phylogenetic placement methods determine how these sequences fit into an evolutionary context. Previous implementations of phylogenetic placement algorithms, such as the evolutionary placement algorithm (EPA) included in RAxML, or PPLACER, are being increasingly used for this purpose. However, due to the steady progress in NGS technologies, the current implementations face substantial scalability limitations. Herein, we present EPA-NG, a complete reimplementation of the EPA that is substantially faster, offers a distributed memory parallelization, and integrates concepts from both, RAxML-EPA and PPLACER. EPA-NG can be executed on standard shared memory, as well as on distributed memory systems (e.g., computing clusters). To demonstrate the scalability of EPA-NG, we placed $1$ billion metagenetic reads from the Tara Oceans Project onto a reference tree with 3748 taxa in just under $7$ h, using 2048 cores. Our performance assessment shows that EPA-NG outperforms RAxML-EPA and PPLACER by up to a factor of $30$ in sequential execution mode, while attaining comparable parallel efficiency on shared memory systems. We further show that the distributed memory parallelization of EPA-NG scales well up to 2048 cores. EPA-NG is available under the AGPLv3 license: https://github.com/Pbdas/epa-ng.
Figures
References
-
- Berger S.A., Stamatakis A.. 2011. Aligning short reads to reference alignments and trees. Bioinformatics 27:2068–2075. - PubMed
-
- Czech L. and Stamatakis A.. 2017. genesis—A toolkit for working with phylogenetic data. http://genesis-lib.org.
Publication types
MeSH terms
Associated data
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
