

Machine learning models in electronic health records can outperform conventional survival models for predicting patient mortality in coronary artery disease
- PMID: 30169498
- PMCID: PMC6118376
- DOI: 10.1371/journal.pone.0202344
Machine learning models in electronic health records can outperform conventional survival models for predicting patient mortality in coronary artery disease
Abstract
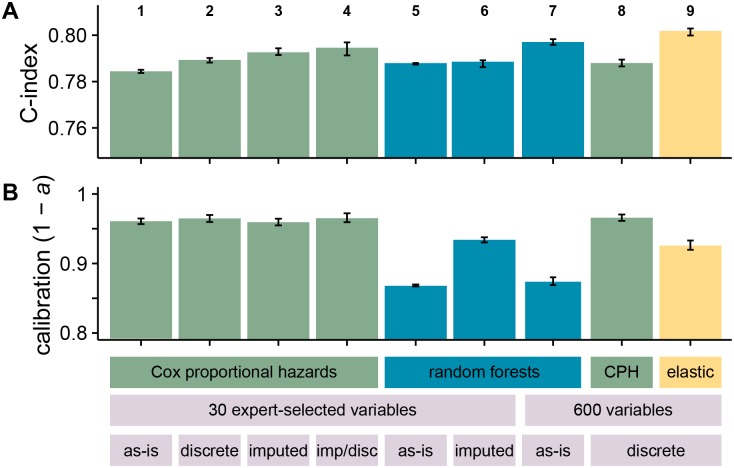
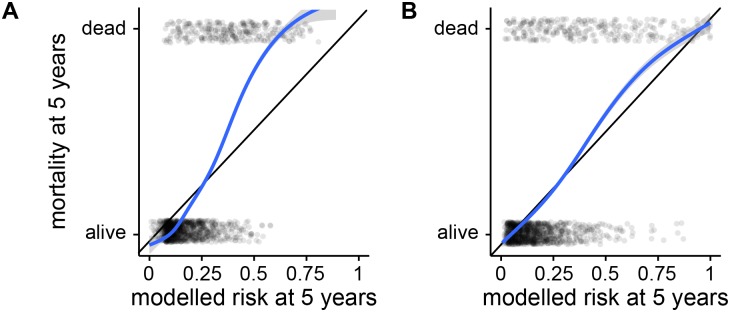
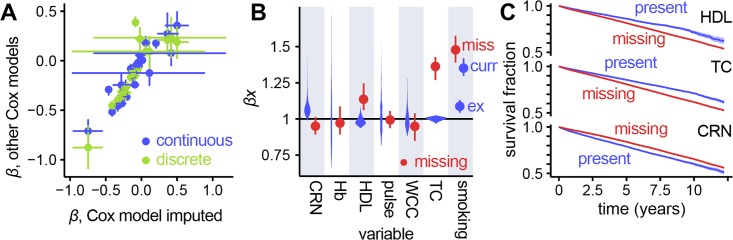
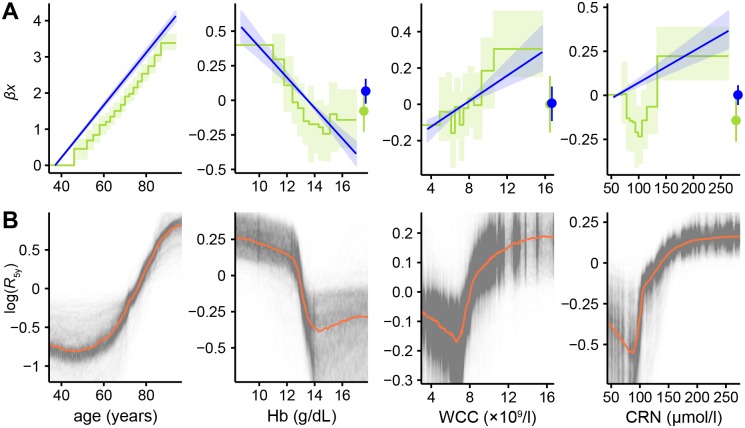
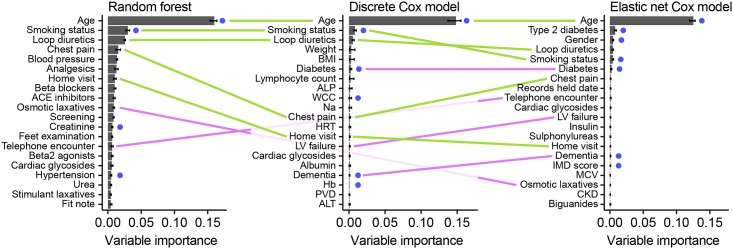
Prognostic modelling is important in clinical practice and epidemiology for patient management and research. Electronic health records (EHR) provide large quantities of data for such models, but conventional epidemiological approaches require significant researcher time to implement. Expert selection of variables, fine-tuning of variable transformations and interactions, and imputing missing values are time-consuming and could bias subsequent analysis, particularly given that missingness in EHR is both high, and may carry meaning. Using a cohort of 80,000 patients from the CALIBER programme, we compared traditional modelling and machine-learning approaches in EHR. First, we used Cox models and random survival forests with and without imputation on 27 expert-selected, preprocessed variables to predict all-cause mortality. We then used Cox models, random forests and elastic net regression on an extended dataset with 586 variables to build prognostic models and identify novel prognostic factors without prior expert input. We observed that data-driven models used on an extended dataset can outperform conventional models for prognosis, without data preprocessing or imputing missing values. An elastic net Cox regression based with 586 unimputed variables with continuous values discretised achieved a C-index of 0.801 (bootstrapped 95% CI 0.799 to 0.802), compared to 0.793 (0.791 to 0.794) for a traditional Cox model comprising 27 expert-selected variables with imputation for missing values. We also found that data-driven models allow identification of novel prognostic variables; that the absence of values for particular variables carries meaning, and can have significant implications for prognosis; and that variables often have a nonlinear association with mortality, which discretised Cox models and random forests can elucidate. This demonstrates that machine-learning approaches applied to raw EHR data can be used to build models for use in research and clinical practice, and identify novel predictive variables and their effects to inform future research.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Denaxas S, Kunz H, Smeeth L, Gonzalez-Izquierdo A, Boutselakis H, Pikoula M, et al. Methods for enhancing the reproducibility of clinical epidemiology research in linked electronic health records: results and lessons learned from the CALIBER platform. IJPDS. 2017;1(1). doi: 10.23889/ijpds.v1i1.84 - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
