

Attractor-like Dynamics in Belief Updating in Schizophrenia
- PMID: 30185463
- PMCID: PMC6705994
- DOI: 10.1523/JNEUROSCI.3163-17.2018
Attractor-like Dynamics in Belief Updating in Schizophrenia
Abstract
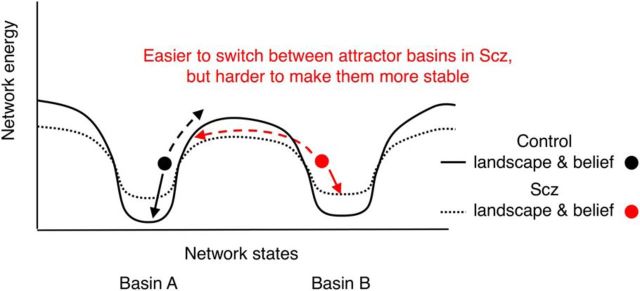
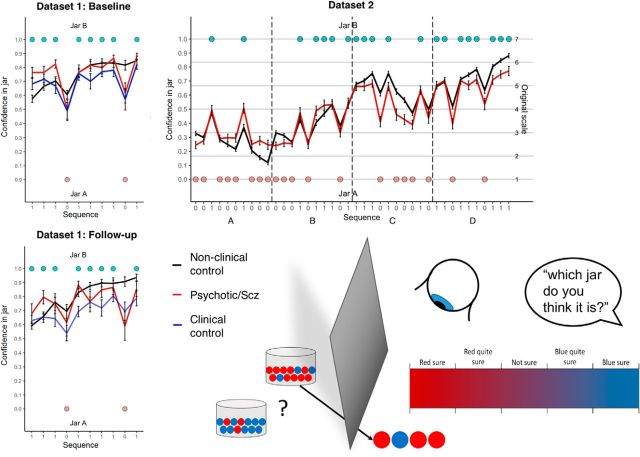
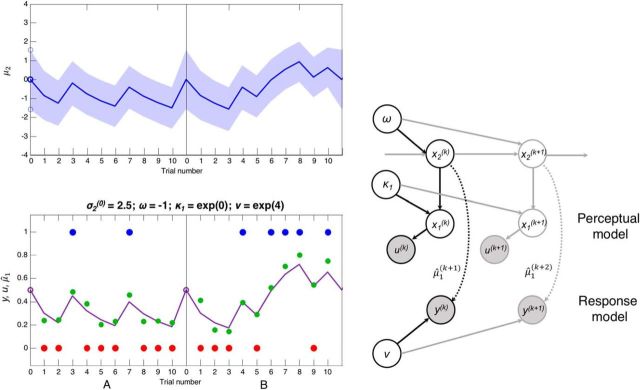
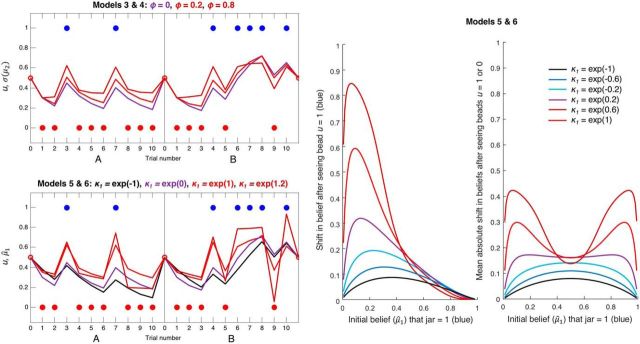
Subjects with a diagnosis of schizophrenia (Scz) overweight unexpected evidence in probabilistic inference: such evidence becomes "aberrantly salient." A neurobiological explanation for this effect is that diminished synaptic gain (e.g., hypofunction of cortical NMDARs) in Scz destabilizes quasi-stable neuronal network states (or "attractors"). This attractor instability account predicts that (1) Scz would overweight unexpected evidence but underweight consistent evidence, (2) belief updating would be more vulnerable to stochastic fluctuations in neural activity, and (3) these effects would correlate. Hierarchical Bayesian belief updating models were tested in two independent datasets (n = 80 male and n = 167 female) comprising human subjects with Scz, and both clinical and nonclinical controls (some tested when unwell and on recovery) performing the "probability estimates" version of the beads task (a probabilistic inference task). Models with a standard learning rate, or including a parameter increasing updating to "disconfirmatory evidence," or a parameter encoding belief instability were formally compared. The "belief instability" model (based on the principles of attractor dynamics) had most evidence in all groups in both datasets. Two of four parameters differed between Scz and nonclinical controls in each dataset: belief instability and response stochasticity. These parameters correlated in both datasets. Furthermore, the clinical controls showed similar parameter distributions to Scz when unwell, but were no different from controls once recovered. These findings are consistent with the hypothesis that attractor network instability contributes to belief updating abnormalities in Scz, and suggest that similar changes may exist during acute illness in other psychiatric conditions.SIGNIFICANCE STATEMENT Subjects with a diagnosis of schizophrenia (Scz) make large adjustments to their beliefs following unexpected evidence, but also smaller adjustments than controls following consistent evidence. This has previously been construed as a bias toward "disconfirmatory" information, but a more mechanistic explanation may be that in Scz, neural firing patterns ("attractor states") are less stable and hence easily altered in response to both new evidence and stochastic neural firing. We model belief updating in Scz and controls in two independent datasets using a hierarchical Bayesian model, and show that all subjects are best fit by a model containing a belief instability parameter. Both this and a response stochasticity parameter are consistently altered in Scz, as the unstable attractor hypothesis predicts.
Keywords: Bayesian; attractor model; beads task; disconfirmatory bias; psychosis; schizophrenia.
Copyright © 2018 the authors 0270-6474/18/389471-15$15.00/0.
Figures
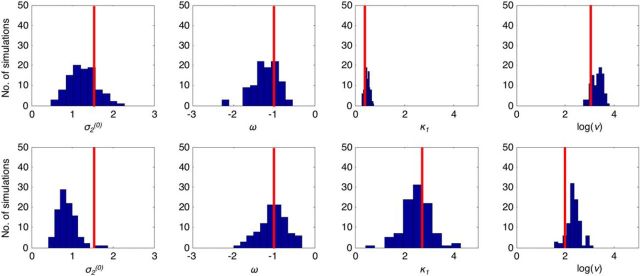
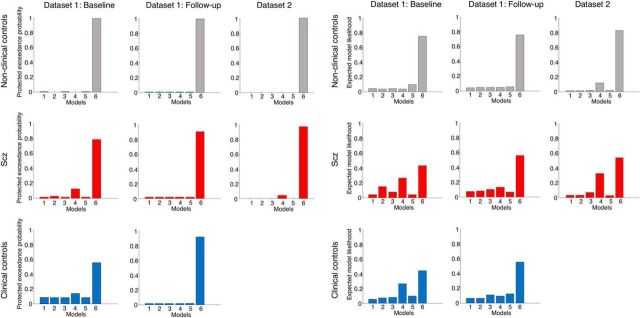
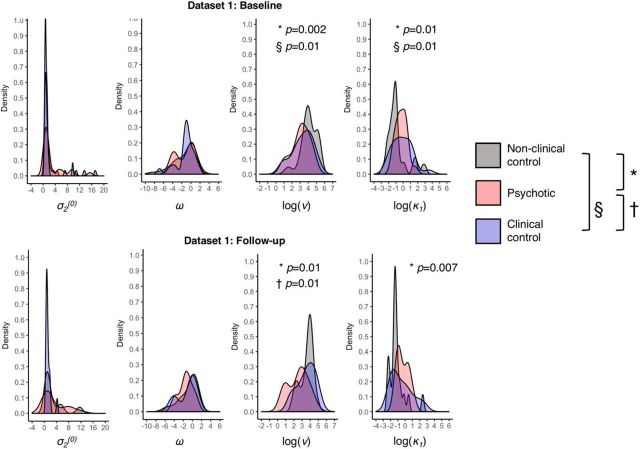
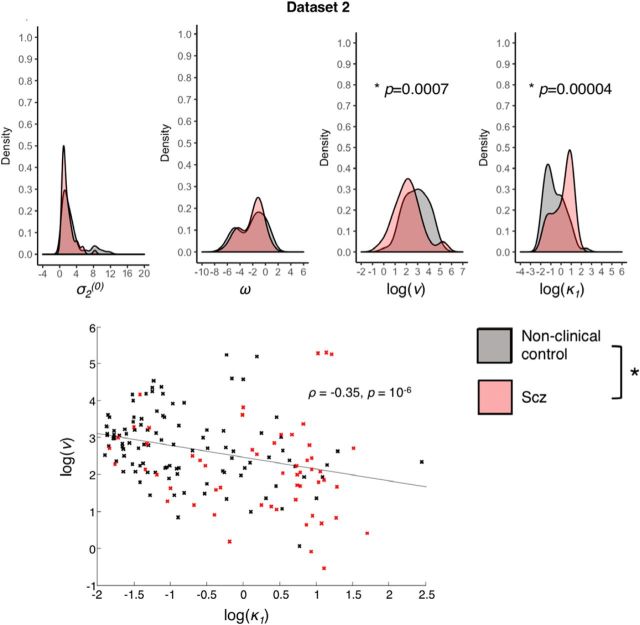
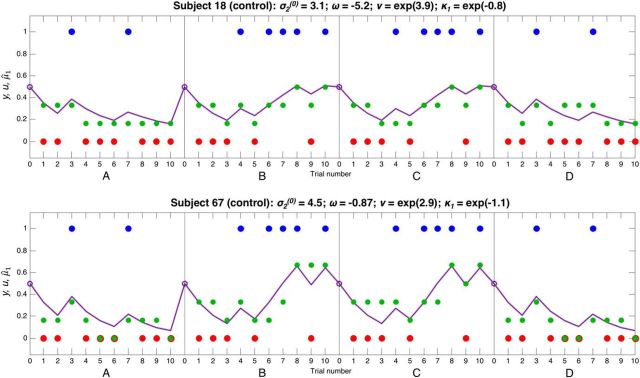
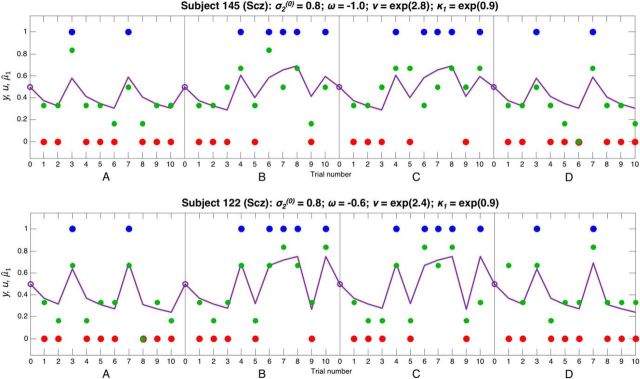
Comment in
-
An Integrative and Mechanistic Model of Impaired Belief Updating in Schizophrenia.J Neurosci. 2019 Jul 17;39(29):5630-5633. doi: 10.1523/JNEUROSCI.0002-19.2019. J Neurosci. 2019. PMID: 31315964 Free PMC article. No abstract available.
References
-
- Ammons RB, Ammons CH (1962) The quick test (QT): provisional manual. Psychol Rep 11:111–161.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical