

Using predicate and provenance information from a knowledge graph for drug efficacy screening
- PMID: 30189889
- PMCID: PMC6127943
- DOI: 10.1186/s13326-018-0189-6
Using predicate and provenance information from a knowledge graph for drug efficacy screening
Abstract
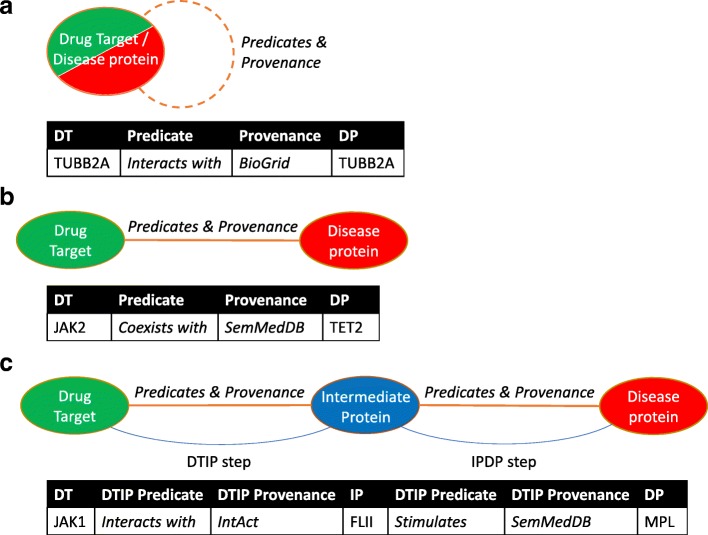
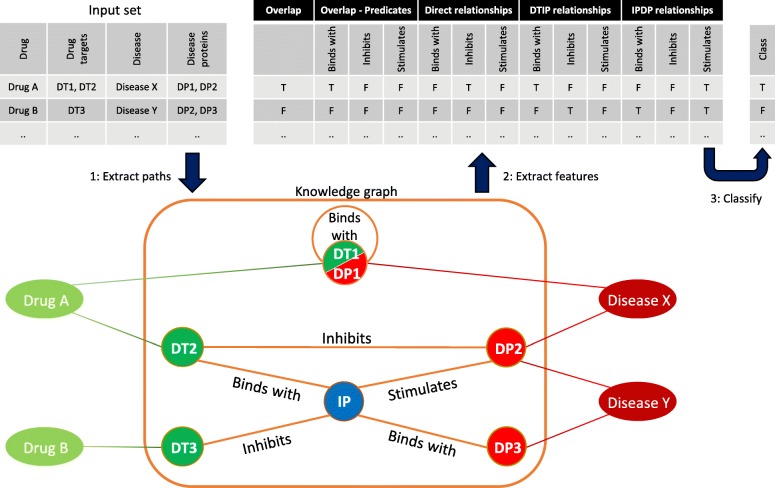
Background: Biomedical knowledge graphs have become important tools to computationally analyse the comprehensive body of biomedical knowledge. They represent knowledge as subject-predicate-object triples, in which the predicate indicates the relationship between subject and object. A triple can also contain provenance information, which consists of references to the sources of the triple (e.g. scientific publications or database entries). Knowledge graphs have been used to classify drug-disease pairs for drug efficacy screening, but existing computational methods have often ignored predicate and provenance information. Using this information, we aimed to develop a supervised machine learning classifier and determine the added value of predicate and provenance information for drug efficacy screening. To ensure the biological plausibility of our method we performed our research on the protein level, where drugs are represented by their drug target proteins, and diseases by their disease proteins.
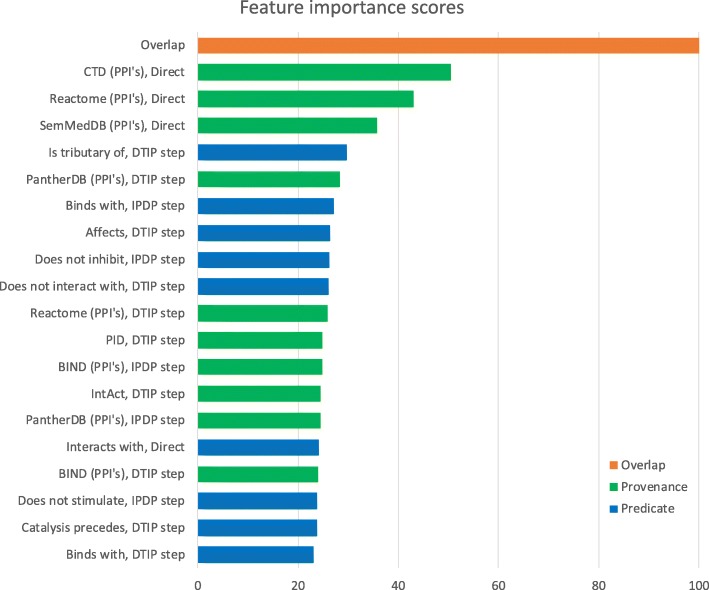
Results: Using random forests with repeated 10-fold cross-validation, our method achieved an area under the ROC curve (AUC) of 78.1% and 74.3% for two reference sets. We benchmarked against a state-of-the-art knowledge-graph technique that does not use predicate and provenance information, obtaining AUCs of 65.6% and 64.6%, respectively. Classifiers that only used predicate information performed superior to classifiers that only used provenance information, but using both performed best.
Conclusion: We conclude that both predicate and provenance information provide added value for drug efficacy screening.
Keywords: Computational pharmacology; Drug efficacy screening; Drug repurposing; Knowledge graph; Machine learning; Predicate; Provenance; Systems pharmacology.
Conflict of interest statement
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Figures
References
-
- Ehrlinger L, Wöß W. Towards a definition of knowledge graphs. CEUR Workshop Proc. 2016;1695
-
- Manola F, Miller E. W3C.org Triple specification. [cited 2018 Jun 4]. Available from: https://www.w3.org/TR/rdf-concepts/#dfn-rdf-triple
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
