

PhIP-Seq characterization of serum antibodies using oligonucleotide-encoded peptidomes
- PMID: 30190553
- PMCID: PMC6568263
- DOI: 10.1038/s41596-018-0025-6
PhIP-Seq characterization of serum antibodies using oligonucleotide-encoded peptidomes
Erratum in
-
Publisher Correction: PhIP-Seq characterization of serum antibodies using oligonucleotide-encoded peptidomes.Nat Protoc. 2019 Aug;14(8):2596. doi: 10.1038/s41596-018-0088-4. Nat Protoc. 2019. PMID: 30361618
Abstract
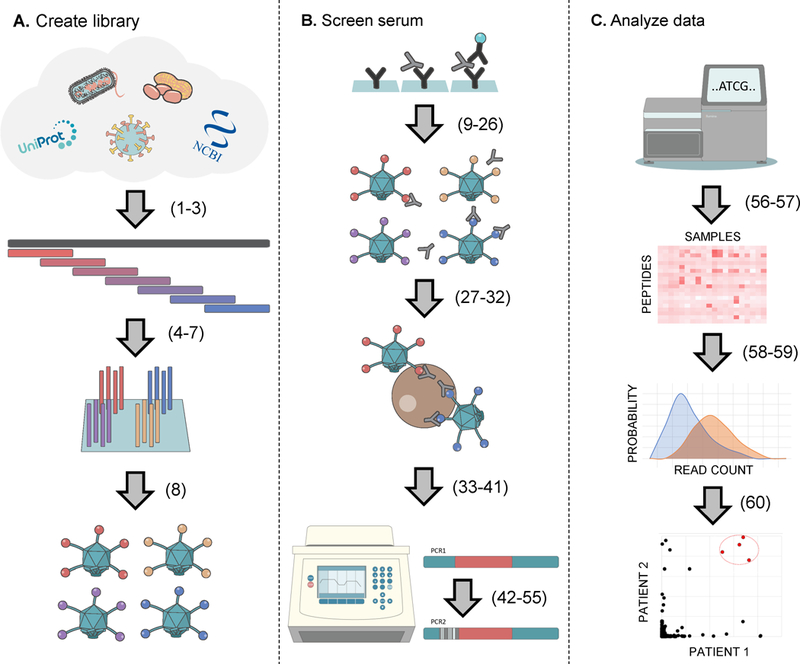
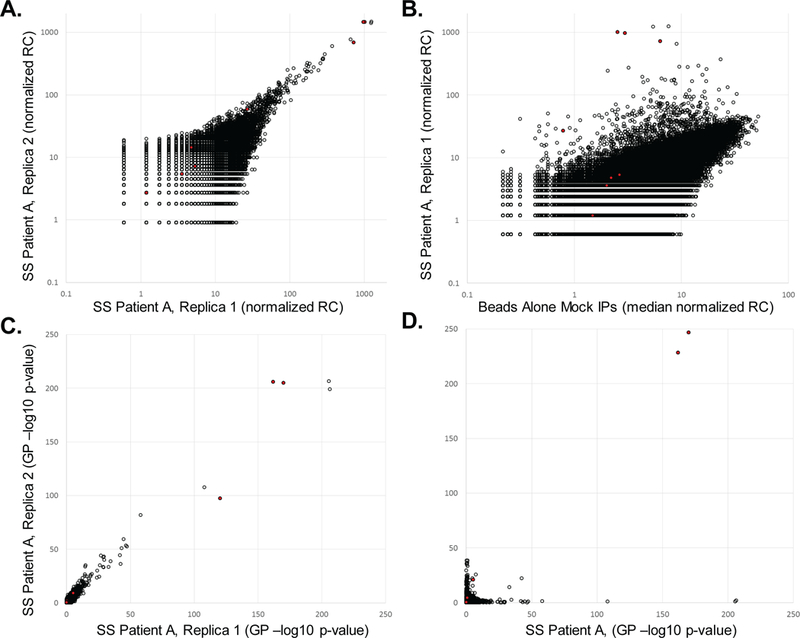
The binding specificities of an individual's antibody repertoire contain a wealth of biological information. They harbor evidence of environmental exposures, allergies, ongoing or emerging autoimmune disease processes, and responses to immunomodulatory therapies, for example. Highly multiplexed methods to comprehensively interrogate antibody-binding specificities have therefore emerged in recent years as important molecular tools. Here, we provide a detailed protocol for performing 'phage immunoprecipitation sequencing' (PhIP-Seq), which is a powerful method for analyzing antibody-repertoire binding specificities with high throughput and at low cost. The methodology uses oligonucleotide library synthesis (OLS) to encode proteomic-scale peptide libraries for display on bacteriophage. These libraries are then immunoprecipitated, using an individual's antibodies, for subsequent analysis by high-throughput DNA sequencing. We have used PhIP-Seq to identify novel self-antigens associated with autoimmune disease, to characterize the self-reactivity of broadly neutralizing HIV antibodies, and in a large international cross-sectional study of exposure to hundreds of human viruses. Compared with alternative array-based techniques, PhIP-Seq is far more scalable in terms of sample throughput and cost per analysis. Cloning and expression of recombinant proteins are not required (versus protein microarrays), and peptide lengths are limited only by DNA synthesis chemistry (up to 90-aa (amino acid) peptides versus the typical 8- to 12-aa length limit of synthetic peptide arrays). Compared with protein microarrays, however, PhIP-Seq libraries lack discontinuous epitopes and post-translational modifications. To increase the accessibility of PhIP-Seq, we provide detailed instructions for the design of phage-displayed peptidome libraries, their immunoprecipitation using serum antibodies, deep sequencing-based measurement of peptide abundances, and statistical determination of peptide enrichments that reflect antibody-peptide interactions. Once a library has been constructed, PhIP-Seq data can be obtained for analysis within a week.
Figures



References
-
- Larman HB et al. Cytosolic 5’-nucleotidase 1A autoimmunity in sporadic inclusion body myositis. Annals of neurology 73, 408–418 (2013). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
