

An evaluation of clinical order patterns machine-learned from clinician cohorts stratified by patient mortality outcomes
- PMID: 30195660
- PMCID: PMC6250126
- DOI: 10.1016/j.jbi.2018.09.005
An evaluation of clinical order patterns machine-learned from clinician cohorts stratified by patient mortality outcomes
Abstract
Objective: Evaluate the quality of clinical order practice patterns machine-learned from clinician cohorts stratified by patient mortality outcomes.
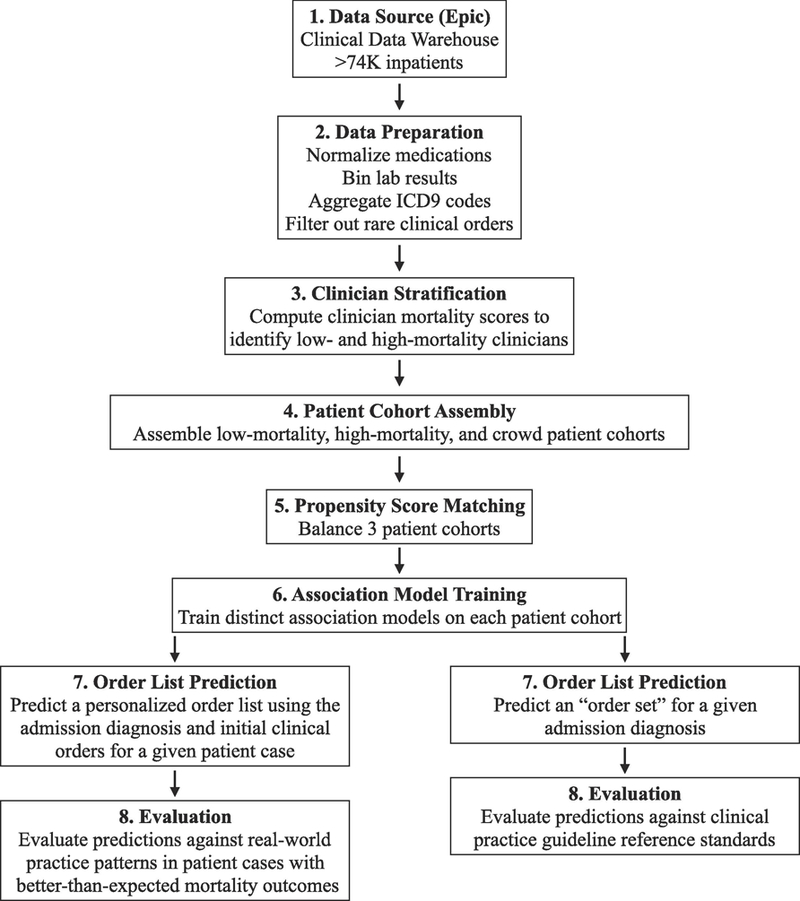
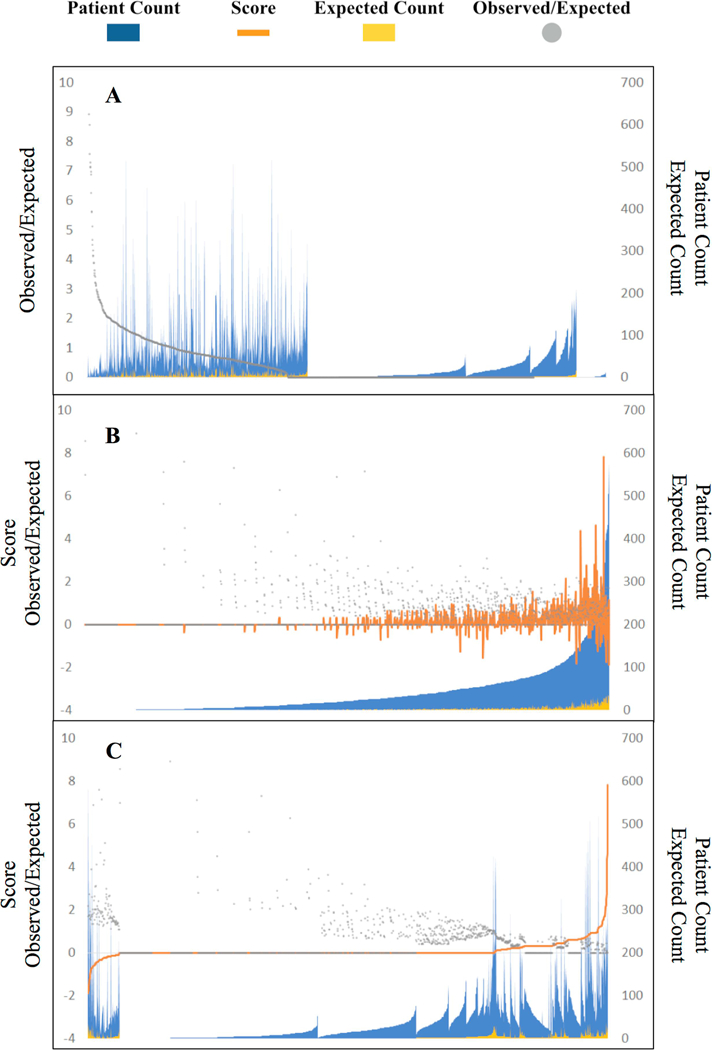
Materials and methods: Inpatient electronic health records from 2010 to 2013 were extracted from a tertiary academic hospital. Clinicians (n = 1822) were stratified into low-mortality (21.8%, n = 397) and high-mortality (6.0%, n = 110) extremes using a two-sided P-value score quantifying deviation of observed vs. expected 30-day patient mortality rates. Three patient cohorts were assembled: patients seen by low-mortality clinicians, high-mortality clinicians, and an unfiltered crowd of all clinicians (n = 1046, 1046, and 5230 post-propensity score matching, respectively). Predicted order lists were automatically generated from recommender system algorithms trained on each patient cohort and evaluated against (i) real-world practice patterns reflected in patient cases with better-than-expected mortality outcomes and (ii) reference standards derived from clinical practice guidelines.
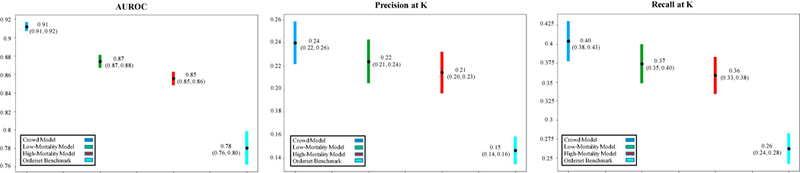
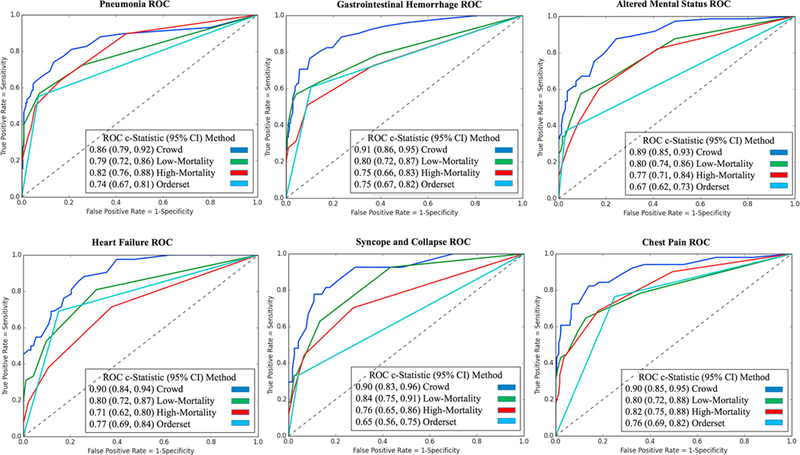
Results: Across six common admission diagnoses, order lists learned from the crowd demonstrated the greatest alignment with guideline references (AUROC range = 0.86-0.91), performing on par or better than those learned from low-mortality clinicians (0.79-0.84, P < 10-5) or manually-authored hospital order sets (0.65-0.77, P < 10-3). The same trend was observed in evaluating model predictions against better-than-expected patient cases, with the crowd model (AUROC mean = 0.91) outperforming the low-mortality model (0.87, P < 10-16) and order set benchmarks (0.78, P < 10-35).
Discussion: Whether machine-learning models are trained on all clinicians or a subset of experts illustrates a bias-variance tradeoff in data usage. Defining robust metrics to assess quality based on internal (e.g. practice patterns from better-than-expected patient cases) or external reference standards (e.g. clinical practice guidelines) is critical to assess decision support content.
Conclusion: Learning relevant decision support content from all clinicians is as, if not more, robust than learning from a select subgroup of clinicians favored by patient outcomes.
Keywords: Clinical decision support; Data mining; Electronic health records; Machine learning; Mortality.
Copyright © 2018 The Authors. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
COMPETING INTERESTS
The authors have no competing interests to declare.
Figures
References
-
- Richardson WC, Berwick DM, Bisgard JC. et al. Crossing the Quality Chasm: A New Health System for the 21st Century Washington DC: Natl Acad Press, Institute of Medicine, Committee on Quality of Health Care in America Committee on Quality of Health Care in America; 2001.
-
- Lauer MS, Bonds D. Eliminating the ‘expensive’ adjective for clinical trials. Am Heart J 2014;167:419–20. - PubMed
-
- Tricoci P, Allen JM, Kramer JM. et al. Scientific evidence underlying the ACC/AHA clinical practice guidelines. JAMA 2009;301:831–41. - PubMed
-
- Durack DT. The weight of medical knowledge. N Engl J Med 1978;298:773–5. - PubMed
-
- Kaushal R, Shojania KG, Bates DW. Effects of computerized physician order entry and clinical decision support systems on medication safety: a systematic review. Arch Intern Med 2003;163:1409–16. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
