

Neural Classifiers with Limited Connectivity and Recurrent Readouts
- PMID: 30249794
- PMCID: PMC6596245
- DOI: 10.1523/JNEUROSCI.3506-17.2018
Neural Classifiers with Limited Connectivity and Recurrent Readouts
Abstract
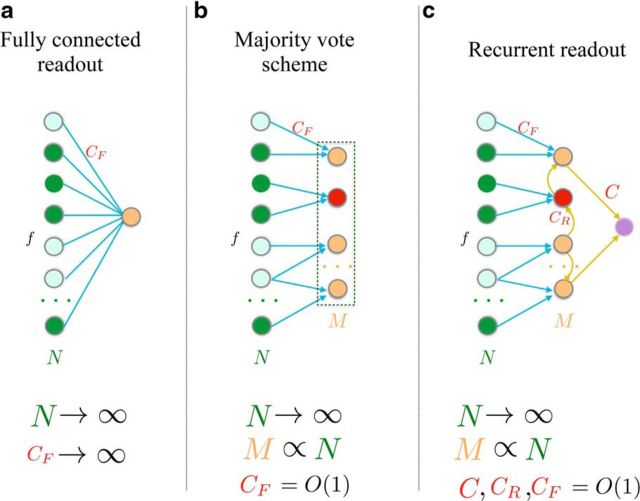
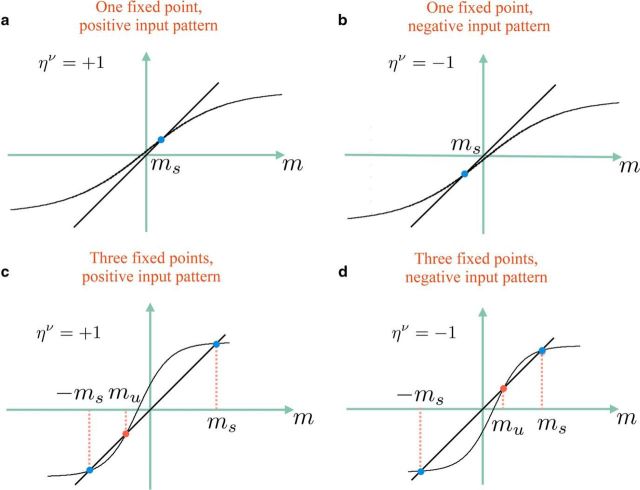
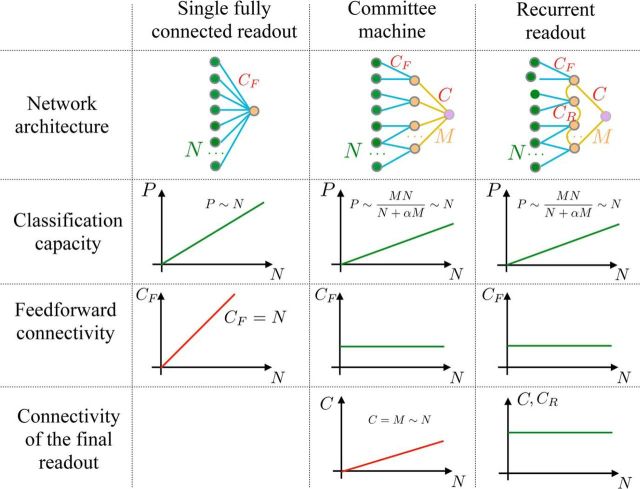
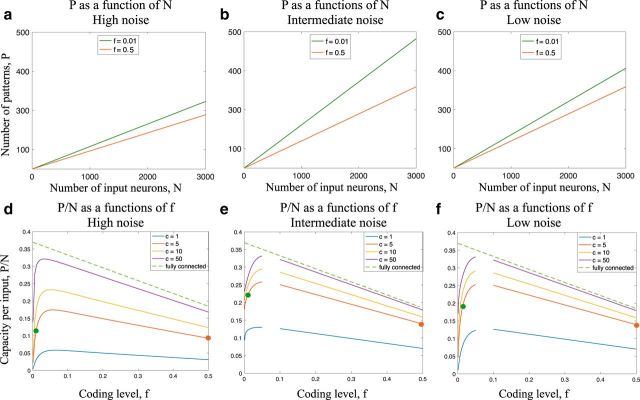
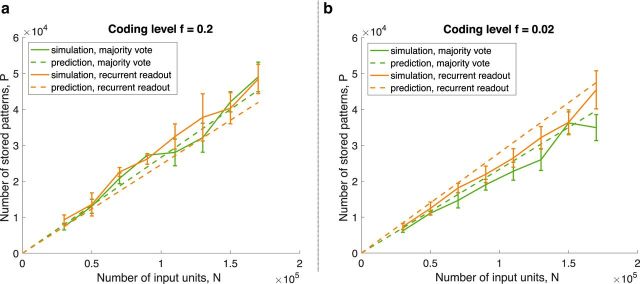
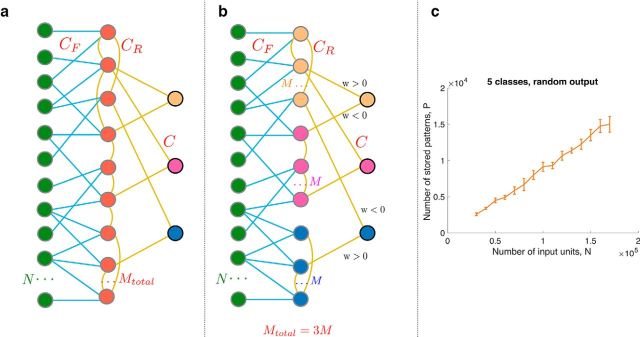
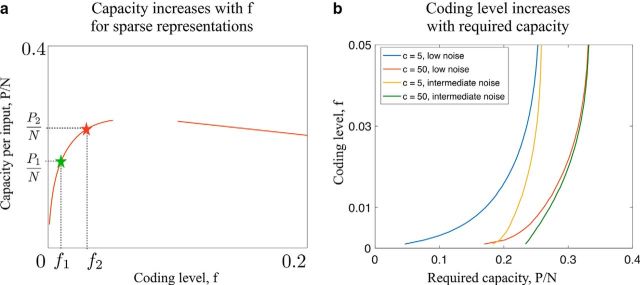
For many neural network models in which neurons are trained to classify inputs like perceptrons, the number of inputs that can be classified is limited by the connectivity of each neuron, even when the total number of neurons is very large. This poses the problem of how the biological brain can take advantage of its huge number of neurons given that the connectivity is sparse. One solution is to combine multiple perceptrons together, as in committee machines. The number of classifiable random patterns would then grow linearly with the number of perceptrons, even when each perceptron has limited connectivity. However, the problem is moved to the downstream readout neurons, which would need a number of connections as large as the number of perceptrons. Here we propose a different approach in which the readout is implemented by connecting multiple perceptrons in a recurrent attractor neural network. We prove analytically that the number of classifiable random patterns can grow unboundedly with the number of perceptrons, even when the connectivity of each perceptron remains finite. Most importantly, both the recurrent connectivity and the connectivity of downstream readouts also remain finite. Our study shows that feedforward neural classifiers with numerous long-range afferent connections can be replaced by recurrent networks with sparse long-range connectivity without sacrificing the classification performance. Our strategy could be used to design more general scalable network architectures with limited connectivity, which resemble more closely the brain neural circuits that are dominated by recurrent connectivity.SIGNIFICANCE STATEMENT The mammalian brain has a huge number of neurons, but the connectivity is rather sparse. This observation seems to contrast with the theoretical studies showing that for many neural network models the performance scales with the number of connections per neuron and not with the total number of neurons. To solve this dilemma, we propose a model in which a recurrent network reads out multiple neural classifiers. Its performance scales with the total number of neurons even when each neuron of the network has limited connectivity. Our study reveals an important role of recurrent connections in neural systems like the hippocampus, in which the computational limitations due to sparse long-range feedforward connectivity might be compensated by local recurrent connections.
Keywords: attractor networks; classifier; committee machines; perceptron; sparse connectivity.
Copyright © 2018 the authors 0270-6474/18/389900-25$15.00/0.
Figures

Similar articles
-
Structural network measures reveal the emergence of heavy-tailed degree distributions in lottery ticket multilayer perceptrons.Neural Netw. 2025 Jul;187:107308. doi: 10.1016/j.neunet.2025.107308. Epub 2025 Mar 12. Neural Netw. 2025. PMID: 40120548
-
A learning rule for very simple universal approximators consisting of a single layer of perceptrons.Neural Netw. 2008 Jun;21(5):786-95. doi: 10.1016/j.neunet.2007.12.036. Epub 2007 Dec 31. Neural Netw. 2008. PMID: 18249524
-
Cortical attractor network dynamics with diluted connectivity.Brain Res. 2012 Jan 24;1434:212-25. doi: 10.1016/j.brainres.2011.08.002. Epub 2011 Aug 7. Brain Res. 2012. PMID: 21875702
-
Input prediction and autonomous movement analysis in recurrent circuits of spiking neurons.Rev Neurosci. 2003;14(1-2):5-19. doi: 10.1515/revneuro.2003.14.1-2.5. Rev Neurosci. 2003. PMID: 12929914 Review.
-
Dynamics of Continuous Attractor Neural Networks With Spike Frequency Adaptation.Neural Comput. 2025 May 14;37(6):1057-1101. doi: 10.1162/neco_a_01757. Neural Comput. 2025. PMID: 40262747 Review.
Cited by
-
Towards a more general understanding of the algorithmic utility of recurrent connections.PLoS Comput Biol. 2022 Jun 21;18(6):e1010227. doi: 10.1371/journal.pcbi.1010227. eCollection 2022 Jun. PLoS Comput Biol. 2022. PMID: 35727818 Free PMC article.
-
The topology and geometry of neural representations.Proc Natl Acad Sci U S A. 2024 Oct 15;121(42):e2317881121. doi: 10.1073/pnas.2317881121. Epub 2024 Oct 7. Proc Natl Acad Sci U S A. 2024. PMID: 39374397 Free PMC article.
-
Sparse RNNs can support high-capacity classification.PLoS Comput Biol. 2022 Dec 14;18(12):e1010759. doi: 10.1371/journal.pcbi.1010759. eCollection 2022 Dec. PLoS Comput Biol. 2022. PMID: 36516226 Free PMC article.
References
-
- Amit DJ. (1992) Modeling brain function: the world of attractor neural networks. Cambridge, UK: Cambridge UP.
-
- Amit DJ, Fusi S (1994) Learning in neural networks with material synapses. Neural Comput 6:957–982. 10.1162/neco.1994.6.5.957 - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources