

Identifying High-Priority Proteins Across the Human Diseasome Using Semantic Similarity
- PMID: 30256117
- PMCID: PMC6606054
- DOI: 10.1021/acs.jproteome.8b00393
Identifying High-Priority Proteins Across the Human Diseasome Using Semantic Similarity
Abstract
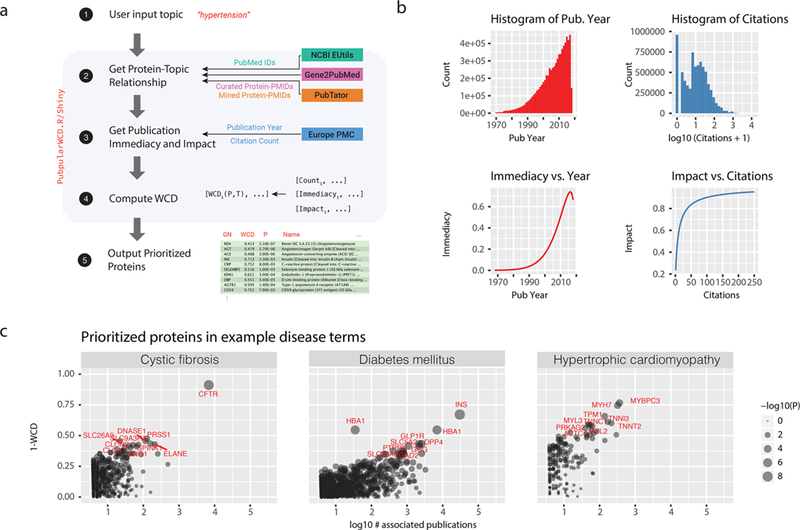
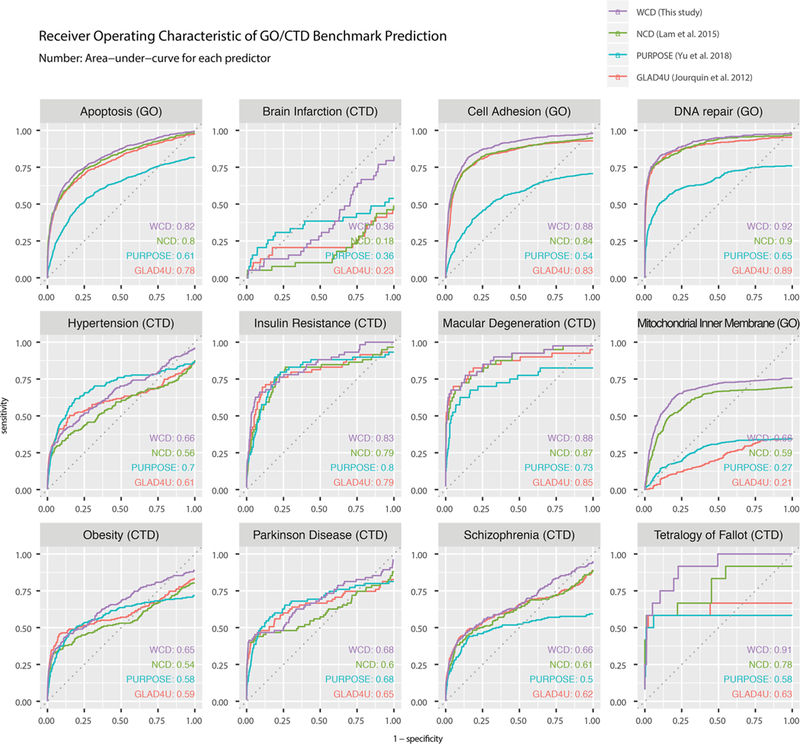
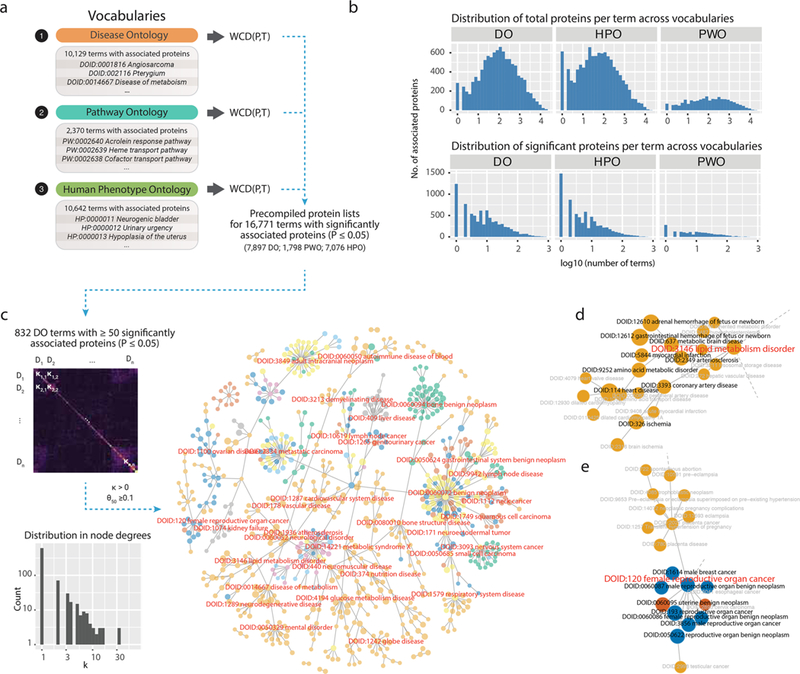
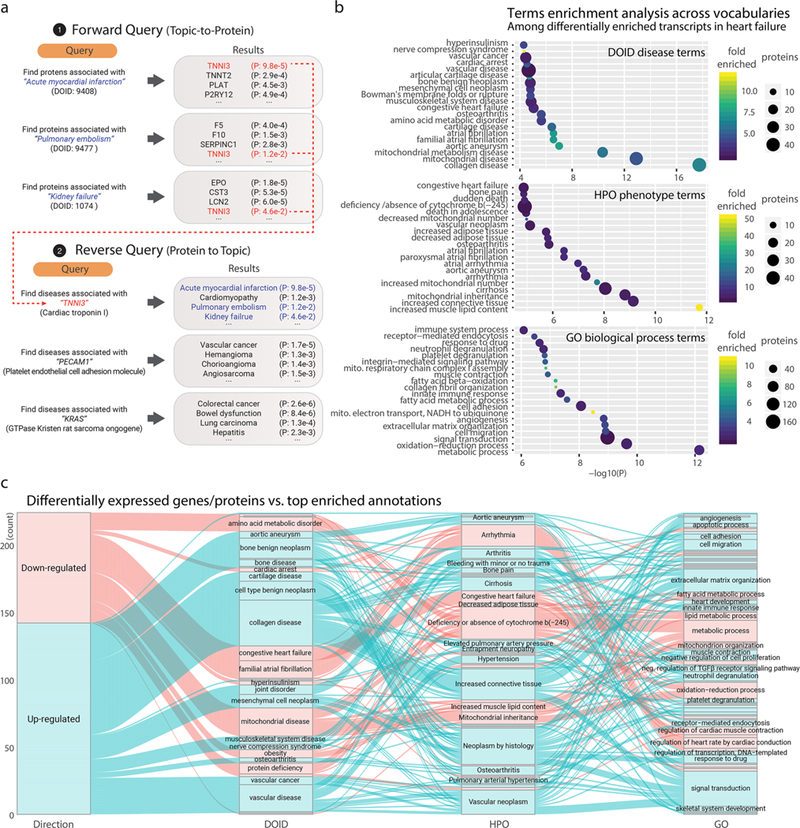
Identifying the genes and proteins associated with a biological process or disease is a central goal of the biomedical research enterprise. However, relatively few systematic approaches are available that provide objective evaluation of the genes or proteins known to be important to a research topic, and hence researchers often rely on subjective evaluation of domain experts and laborious manual literature review. Computational bibliometric analysis, in conjunction with text mining and data curation, attempts to automate this process and return prioritized proteins in any given research topic. We describe here a method to identify and rank protein-topic relationships by calculating the semantic similarity between a protein and a query term in the biomerical literature while adjusting for the impact and immediacy of associated research articles. We term the calculated metric the weighted copublication distance (WCD) and show that it compares well to related approaches in predicting benchmark protein lists in multiple biological processes. We used WCD to extract prioritized "popular proteins" across multiple cell types, subanatomical regions, and standardized vocabularies containing over 20 000 human disease terms. The collection of protein-disease associations across the resulting human "diseasome" supports data analytical workflows to perform reverse protein-to-disease queries and functional annotation of experimental protein lists. We envision that the described improvement to the popular proteins strategy will be useful for annotating protein lists and guiding method development efforts as well as generating new hypotheses on understudied disease proteins using bibliometric information.
Keywords: bibliometric analysis; diseasome; high-priority proteins; normalized copublication distance; popular proteins; semantic similarity; targeted proteomics; weighted copublication distance.
Figures
References
-
- Yu KH; Lee TM; Wang CS; Chen YJ; Re C; Kou SC; Chiang JH; Kohane IS; Snyder M Systematic Protein Prioritization for Targeted Proteomics Studies through Literature Mining. J. Proteome Res. 2018, 17, 1383–1396. - PubMed
-
- Lam MP; Venkatraman V; Cao Q; Wang D; Dincer TU; Lau E; Su AI; Xing Y; Ge J; Ping P; Van Eyk JE Prioritizing Proteomics Assay Development for Clinical Translation. J. Am. Coll. Cardiol. 2015, 66, 202–204. - PubMed
-
- Mora MI; Molina M; Odriozola L; Elortza F; Mato JM; Sitek B; Zhang P; He F; Latasa MU; Avila MA; Corrales FJ Prioritizing Popular Proteins in Liver Cancer: Remodelling One-Carbon Metabolism. J. Proteome Res. 2017, 16, 4506–4514. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
