Identification of cell types in a mouse brain single-cell atlas using low sampling coverage
- PMID: 30309354
- PMCID: PMC6180488
- DOI: 10.1186/s12915-018-0580-x
Identification of cell types in a mouse brain single-cell atlas using low sampling coverage
Abstract
Background: High throughput methods for profiling the transcriptomes of single cells have recently emerged as transformative approaches for large-scale population surveys of cellular diversity in heterogeneous primary tissues. However, the efficient generation of such atlases will depend on sufficient sampling of diverse cell types while remaining cost-effective to enable a comprehensive examination of organs, developmental stages, and individuals.
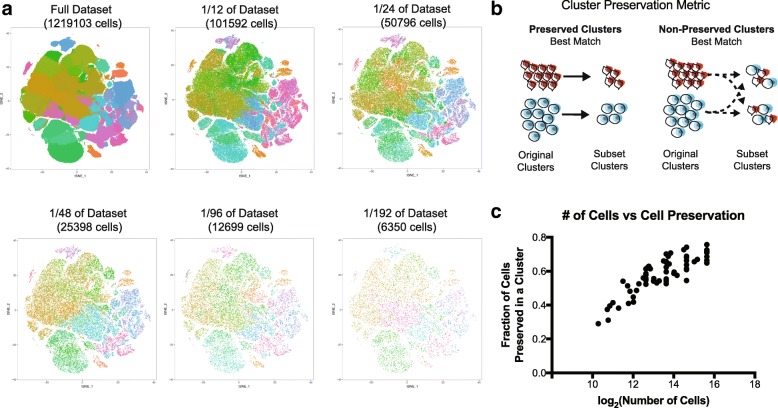
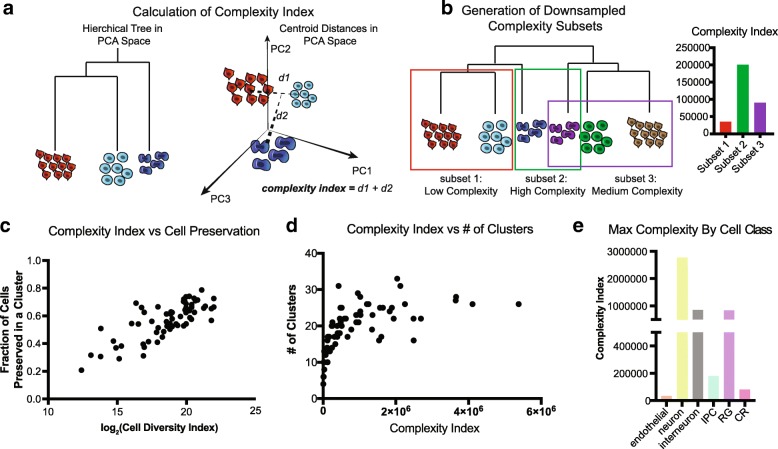
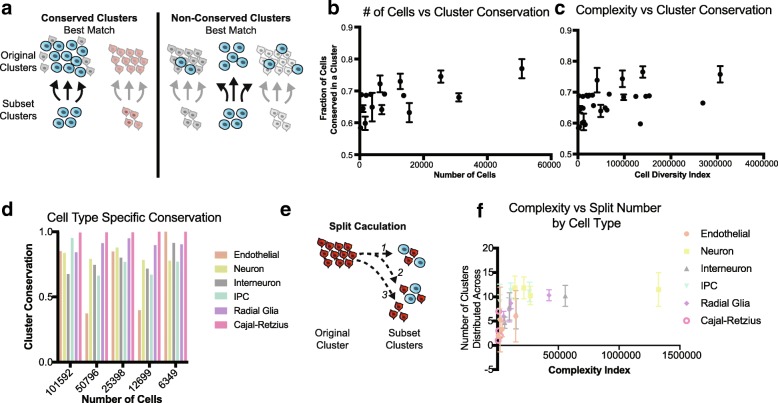
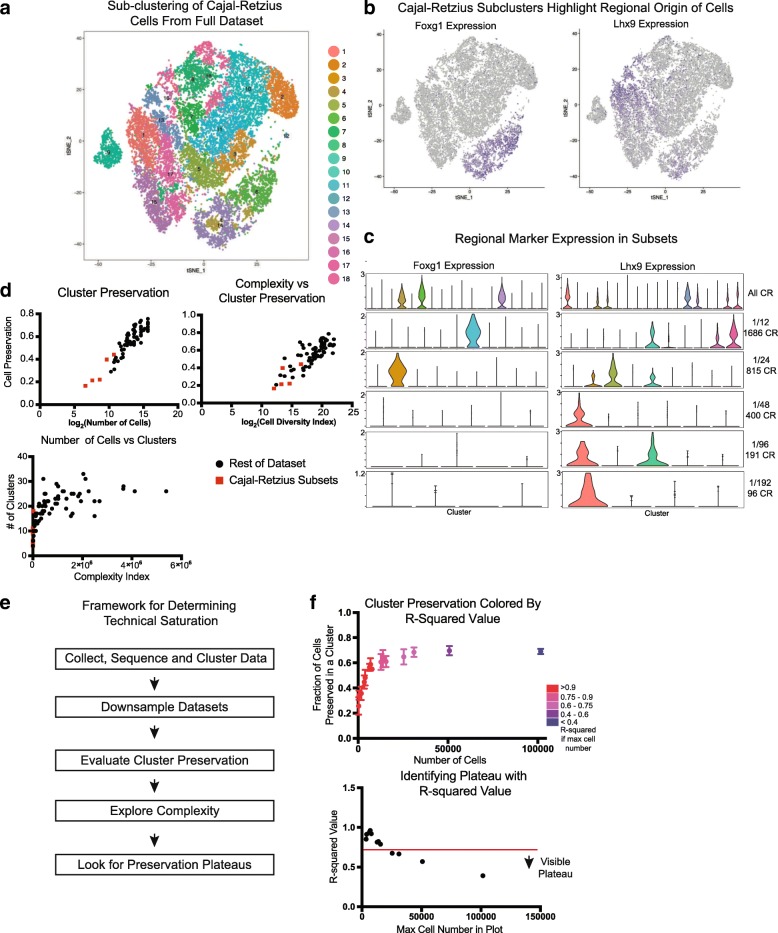
Results: To examine the relationship between sampled cell numbers and transcriptional heterogeneity in the context of unbiased cell type classification, we explored the population structure of a publicly available 1.3 million cell dataset from E18.5 mouse brain and validated our findings in published data from adult mice. We propose a computational framework for inferring the saturation point of cluster discovery in a single-cell mRNA-seq experiment, centered around cluster preservation in downsampled datasets. In addition, we introduce a "complexity index," which characterizes the heterogeneity of cells in a given dataset. Using Cajal-Retzius cells as an example of a limited complexity dataset, we explored whether the detected biological distinctions relate to technical clustering. Surprisingly, we found that clustering distinctions carrying biologically interpretable meaning are achieved with far fewer cells than the originally sampled, though technical saturation of rare populations such as Cajal-Retzius cells is not achieved. We additionally validated these findings with a recently published atlas of cell types across mouse organs and again find using subsampling that a much smaller number of cells recapitulates the cluster distinctions of the complete dataset.
Conclusions: Together, these findings suggest that most of the biologically interpretable cell types from the 1.3 million cell database can be recapitulated by analyzing 50,000 randomly selected cells, indicating that instead of profiling few individuals at high "cellular coverage," cell atlas studies may instead benefit from profiling more individuals, or many time points at lower cellular coverage and then further enriching for populations of interest. This strategy is ideal for scenarios where cost and time are limited, though extremely rare populations of interest (< 1%) may be identifiable only with much higher cell numbers.
Keywords: Bioinformatics; Cell atlas studies; Downsampling; Single-cell analysis.
Conflict of interest statement
Ethics approval and consent to participate
Not applicable
Consent for publication
Not applicable
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Figures