

Group A Rotavirus VP1 Polymerase and VP2 Core Shell Proteins: Intergenotypic Sequence Variation and In Vitro Functional Compatibility
- PMID: 30355692
- PMCID: PMC6321916
- DOI: 10.1128/JVI.01642-18
Group A Rotavirus VP1 Polymerase and VP2 Core Shell Proteins: Intergenotypic Sequence Variation and In Vitro Functional Compatibility
Abstract
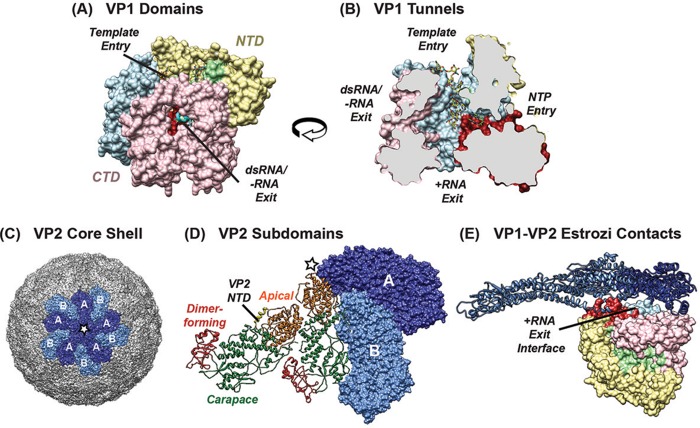
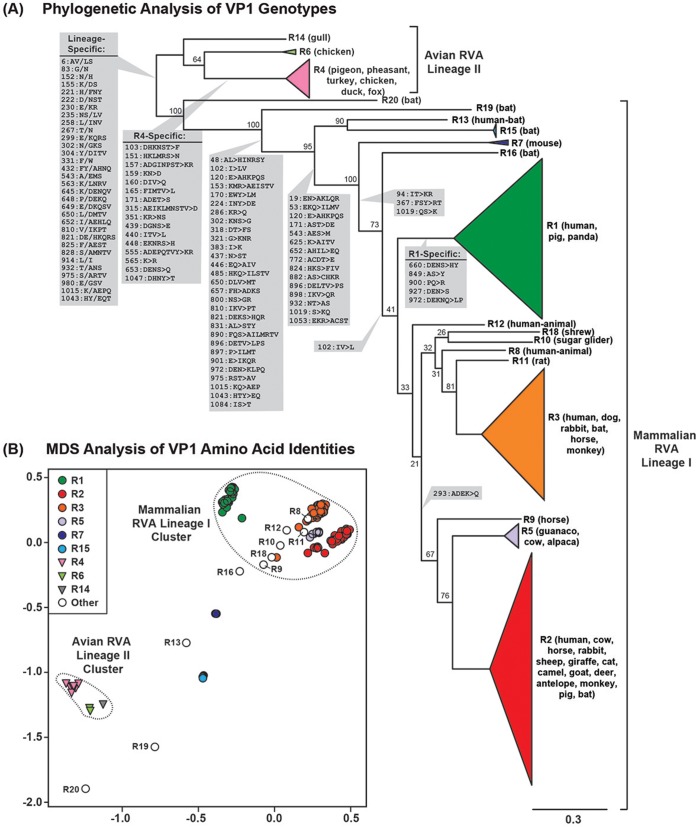
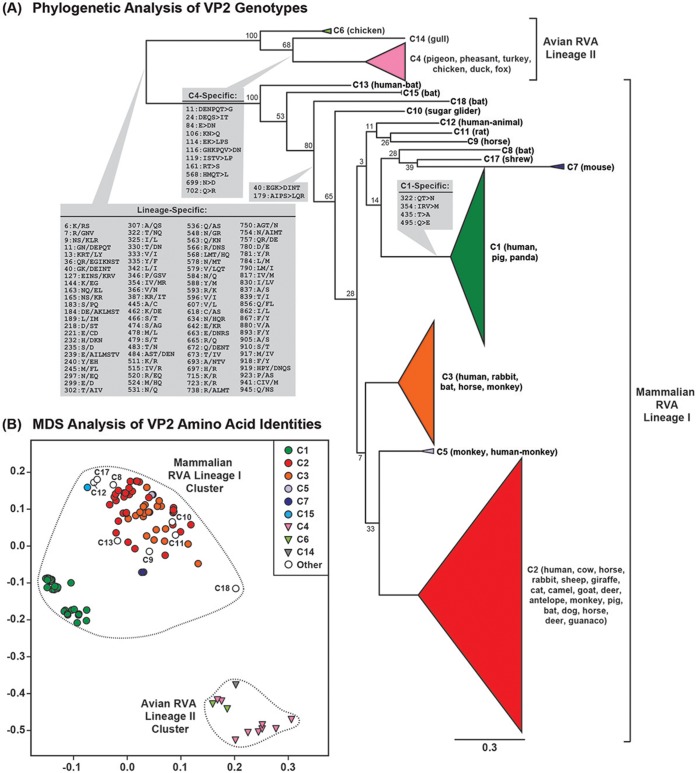
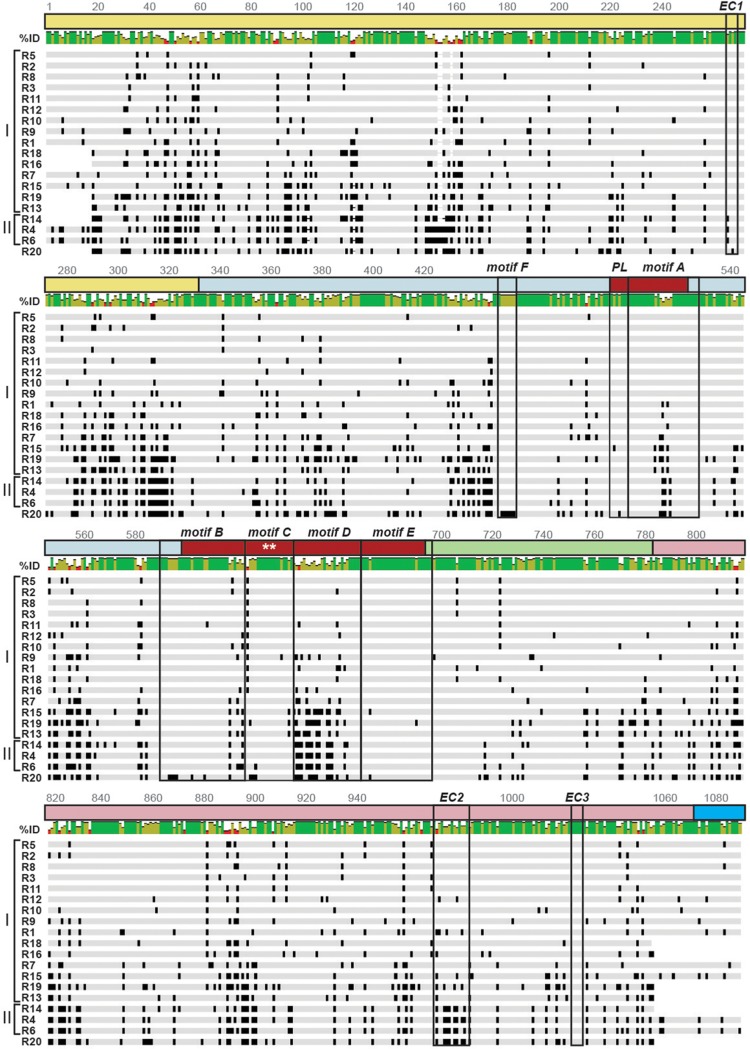
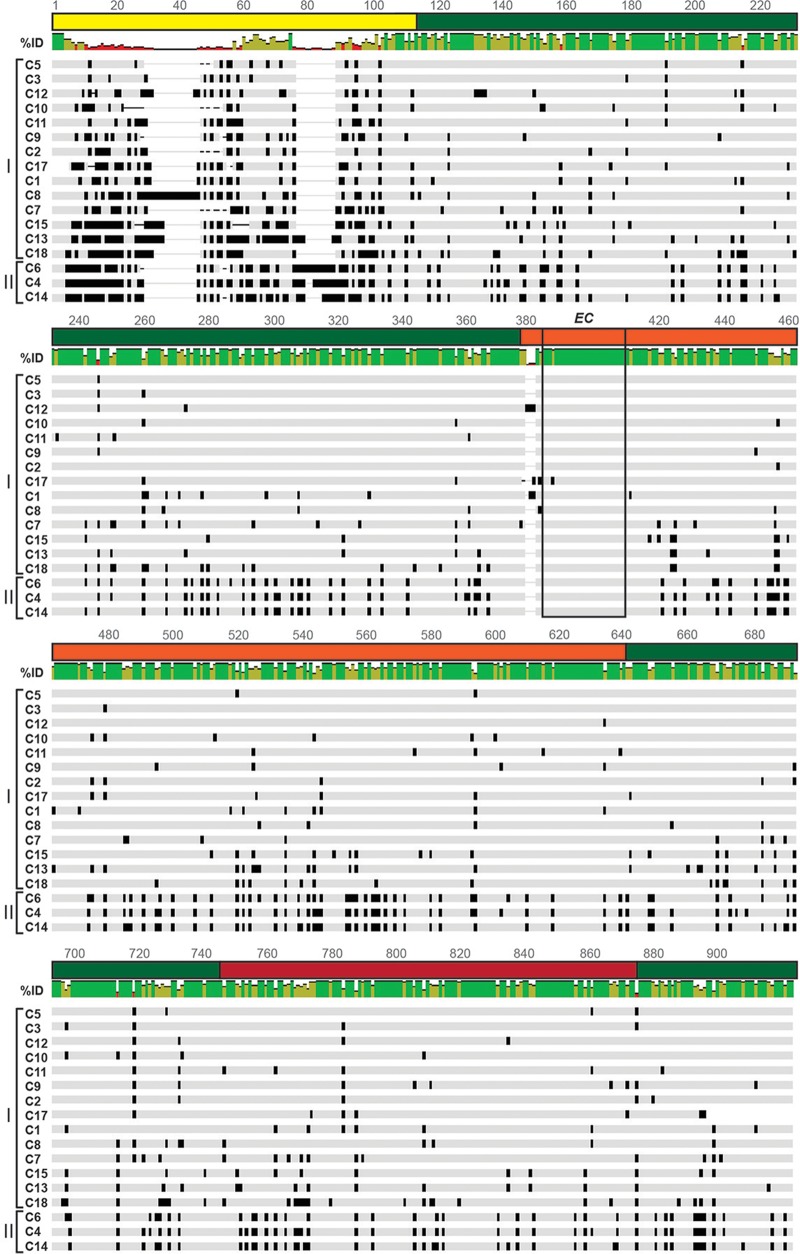
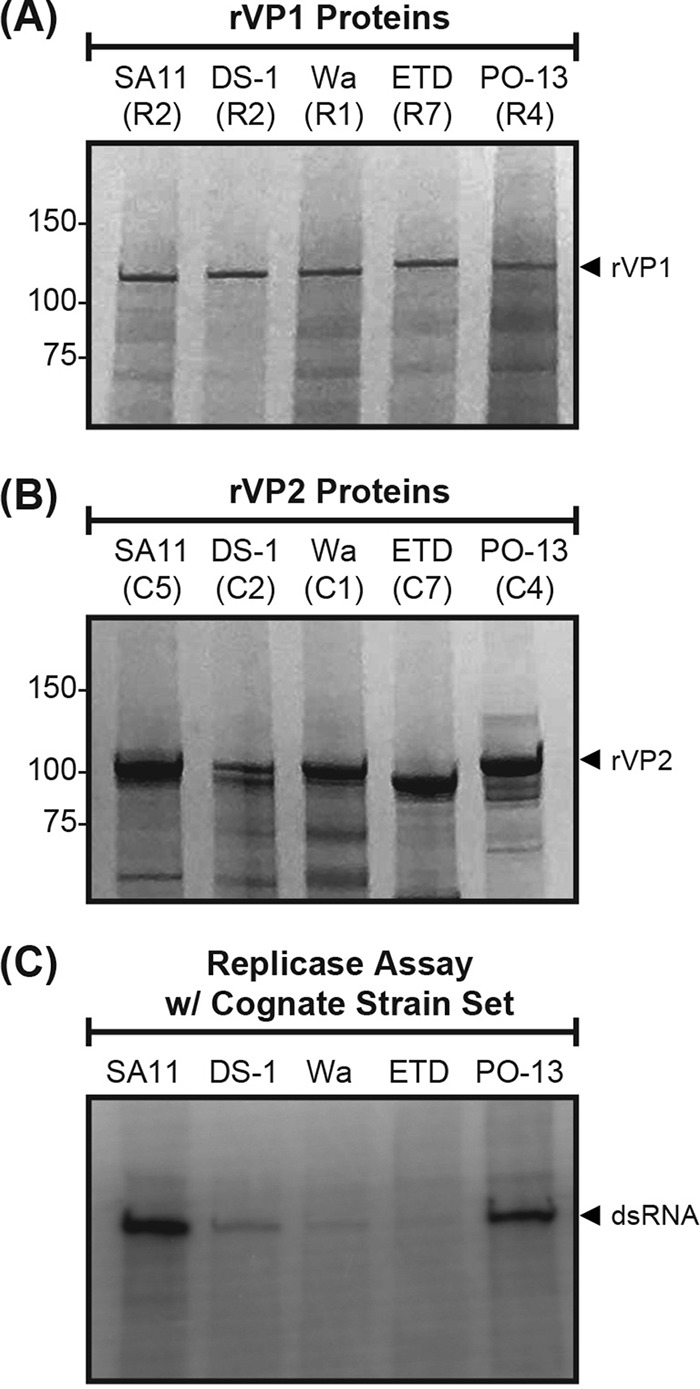
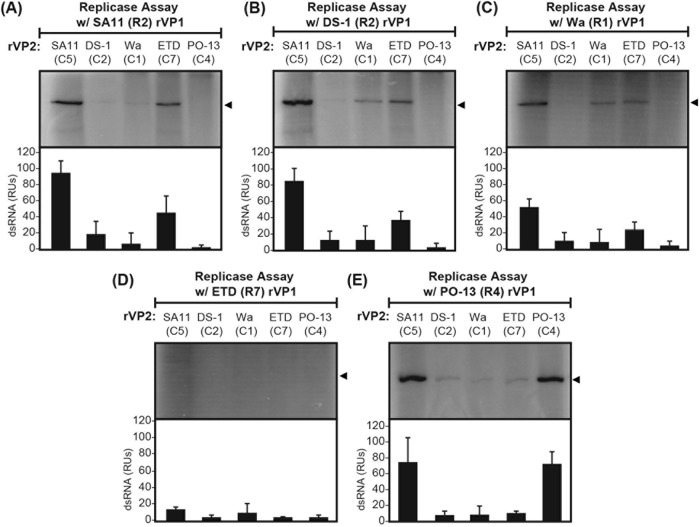
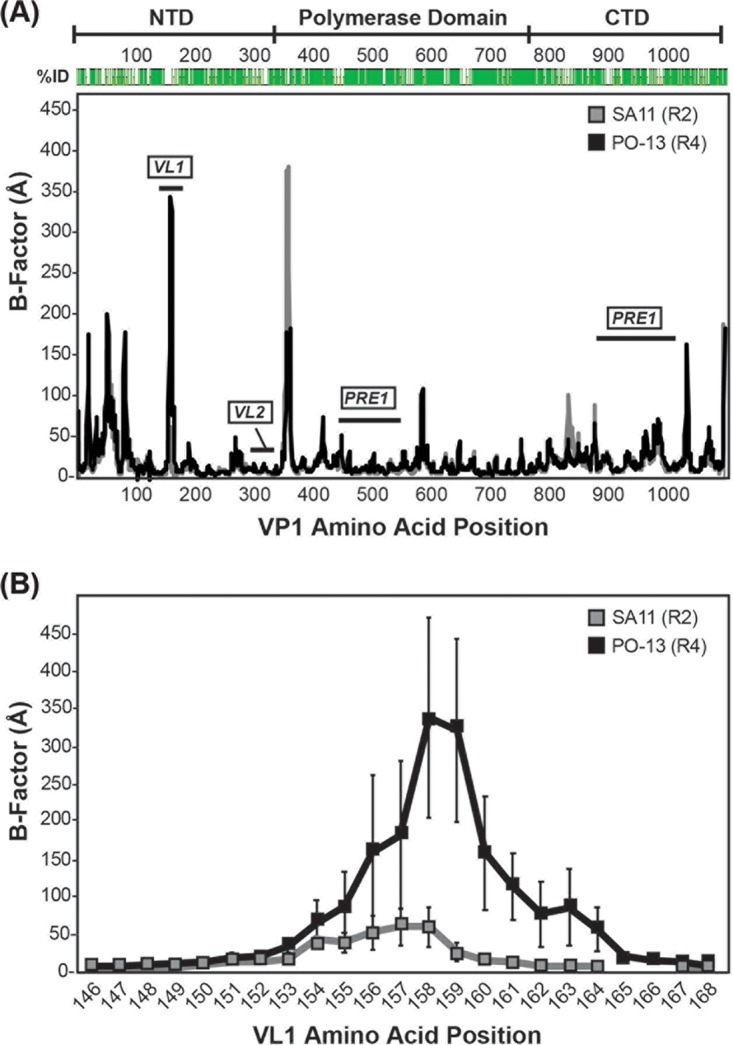
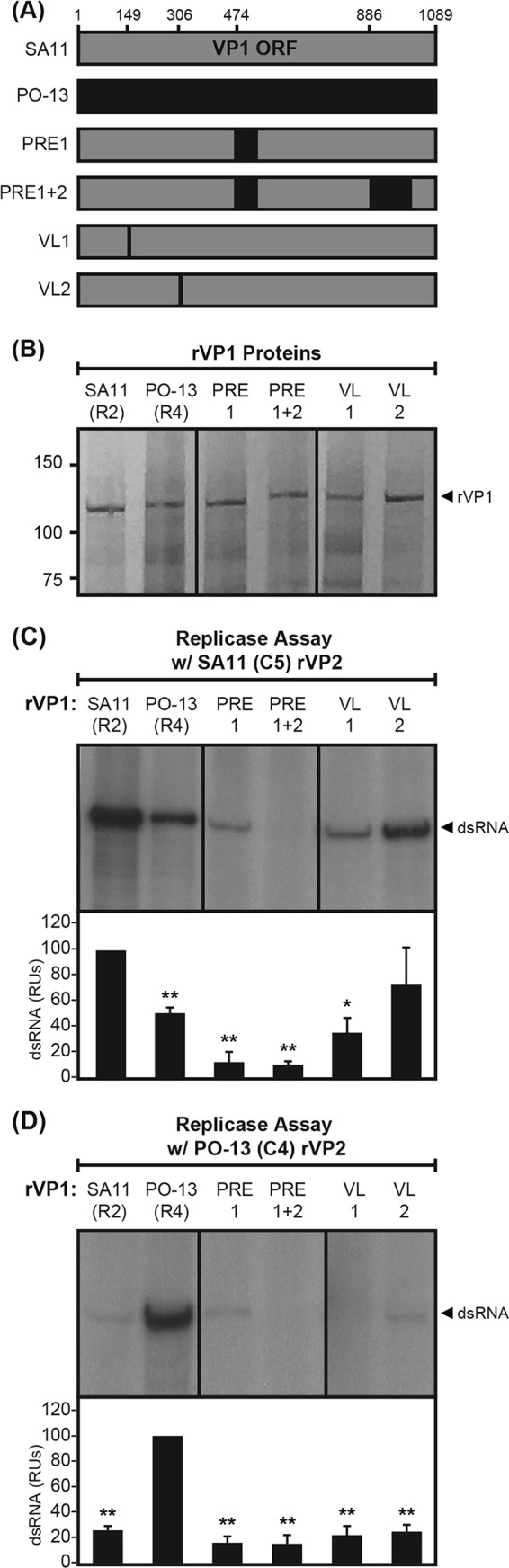
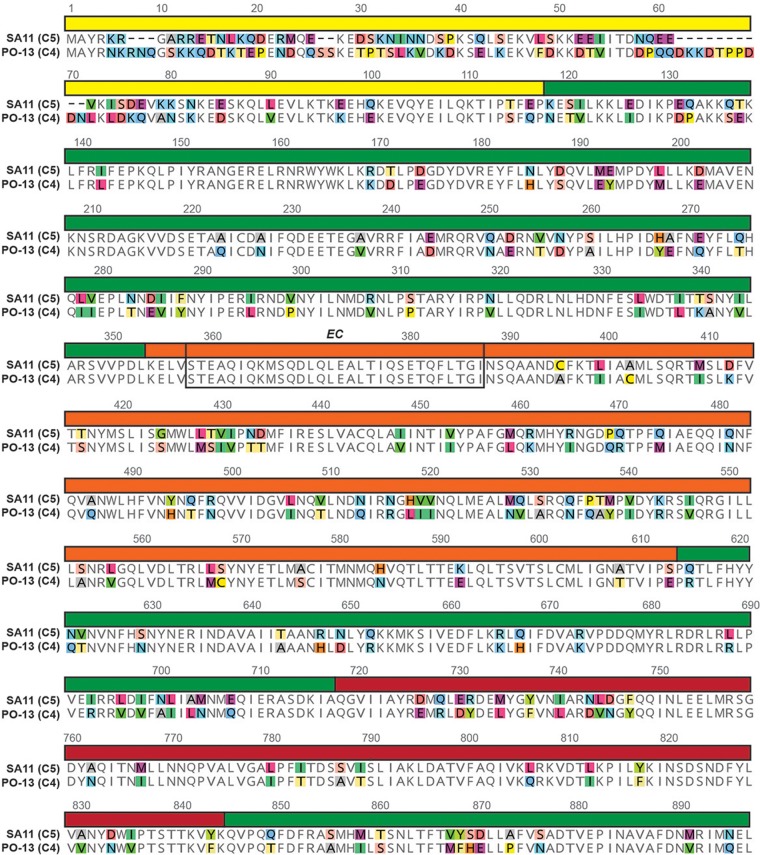
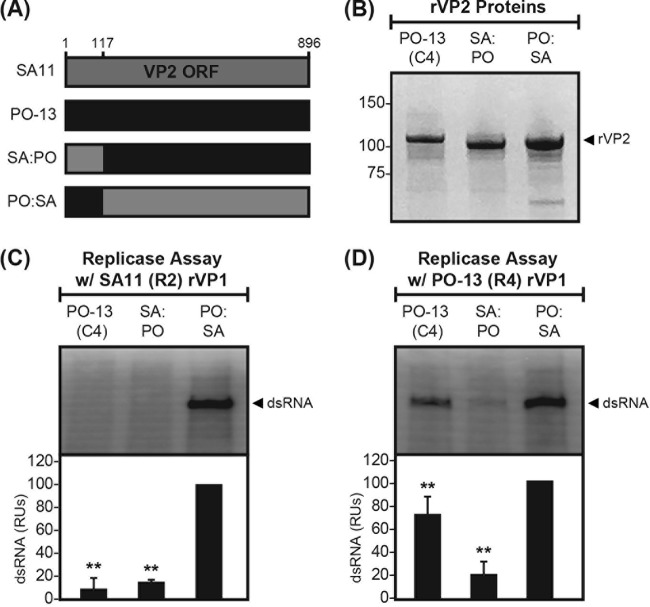
Group A rotaviruses (RVAs) are classified according to a nucleotide sequence-based system that assigns a genotype to each of the 11 double-stranded RNA (dsRNA) genome segments. For the segment encoding the VP1 polymerase, 22 genotypes (R1 to R22) are defined with an 83% nucleotide identity cutoff value. For the segment encoding the VP2 core shell protein, which is a functional VP1-binding partner, 20 genotypes (C1 to C20) are defined with an 84% nucleotide identity cutoff value. However, the extent to which the VP1 and VP2 proteins encoded by these genotypes differ in their sequences or interactions has not been described. Here, we sought to (i) delineate the relationships and sites of variation for VP1 and VP2 proteins belonging to the known RVA genotypes and (ii) correlate intergenotypic sequence diversity with functional VP1-VP2 interaction(s) during dsRNA synthesis. Using bioinformatic approaches, we revealed which VP1 and VP2 genotypes encode divergent proteins and identified the positional locations of amino acid changes in the context of known structural domains/subdomains. We then employed an in vitro dsRNA synthesis assay to test whether genotype R1, R2, R4, and R7 VP1 polymerases could be enzymatically activated by genotype C1, C2, C4, C5, and C7 VP2 core shell proteins. Genotype combinations that were incompatible informed the rational design and in vitro testing of chimeric mutant VP1 and VP2 proteins. The results of this study connect VP1 and VP2 nucleotide-level diversity to protein-level diversity for the first time, and they provide new insights into regions/residues critical for VP1-VP2 interaction(s) during viral genome replication.IMPORTANCE Group A rotaviruses (RVAs) are widespread in nature, infecting numerous mammalian and avian hosts and causing severe gastroenteritis in human children. RVAs are classified using a system that assigns a genotype to each viral gene according to its nucleotide sequence. To date, 22 genotypes have been described for the gene encoding the viral polymerase (VP1), and 20 genotypes have been described for the gene encoding the core shell protein (VP2). Here, we analyzed if/how the VP1 and VP2 proteins encoded by the known RVA genotypes differ from each other in their sequences. We also used a biochemical approach to test whether the intergenotypic sequence differences influenced how VP1 and VP2 functionally engage each other to mediate RNA synthesis in a test tube. This work is important because it increases our understanding of RVA protein-level diversity and raises new ideas about the VP1-VP2 binding interface(s) that is important for viral replication.
Keywords: RNA synthesis; RNA-dependent RNA polymerase; core shell protein; diversity; genome replication; genotypes; rotavirus.
Copyright © 2019 American Society for Microbiology.
Figures

References
-
- Estes MK, Kapikian AZ. 2006. Rotaviruses and their replication, p 1917–1974 In Knipe DM, Howley PM, Griffin DE, Lamb RA, Martin MA, Roizman B, Straus SE (ed), Fields virology, 5th ed Lippincott Williams & Wilkins, Philadelphia, PA.
-
- Tate JE, Burton AH, Boschi-Pinto C, Parashar UD, World Health Organization-Coordinated Global Rotavirus Surveillance Network . 2016. Global, regional, and national estimates of rotavirus mortality in children <5 years of age, 2000-2013. Clin Infect Dis 62:S96–S105. doi: 10.1093/cid/civ1013. - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
