

Evolving Robust Policy Coverage Sets in Multi-Objective Markov Decision Processes Through Intrinsically Motivated Self-Play
- PMID: 30356836
- PMCID: PMC6189603
- DOI: 10.3389/fnbot.2018.00065
Evolving Robust Policy Coverage Sets in Multi-Objective Markov Decision Processes Through Intrinsically Motivated Self-Play
Abstract
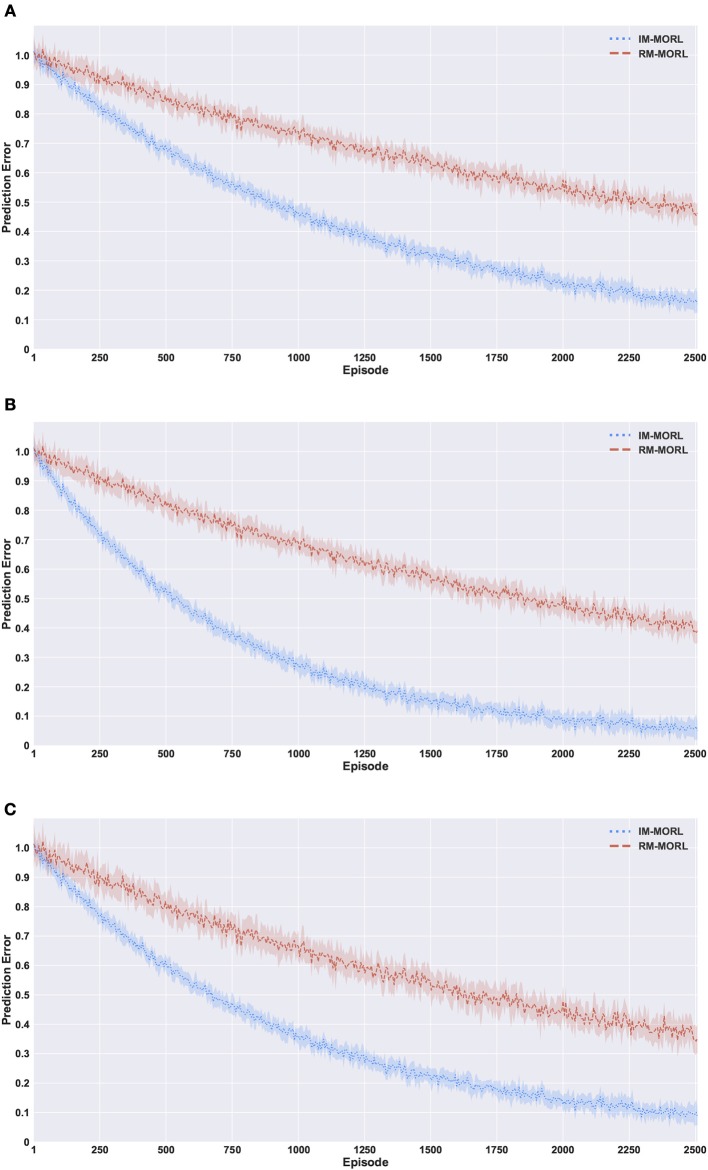
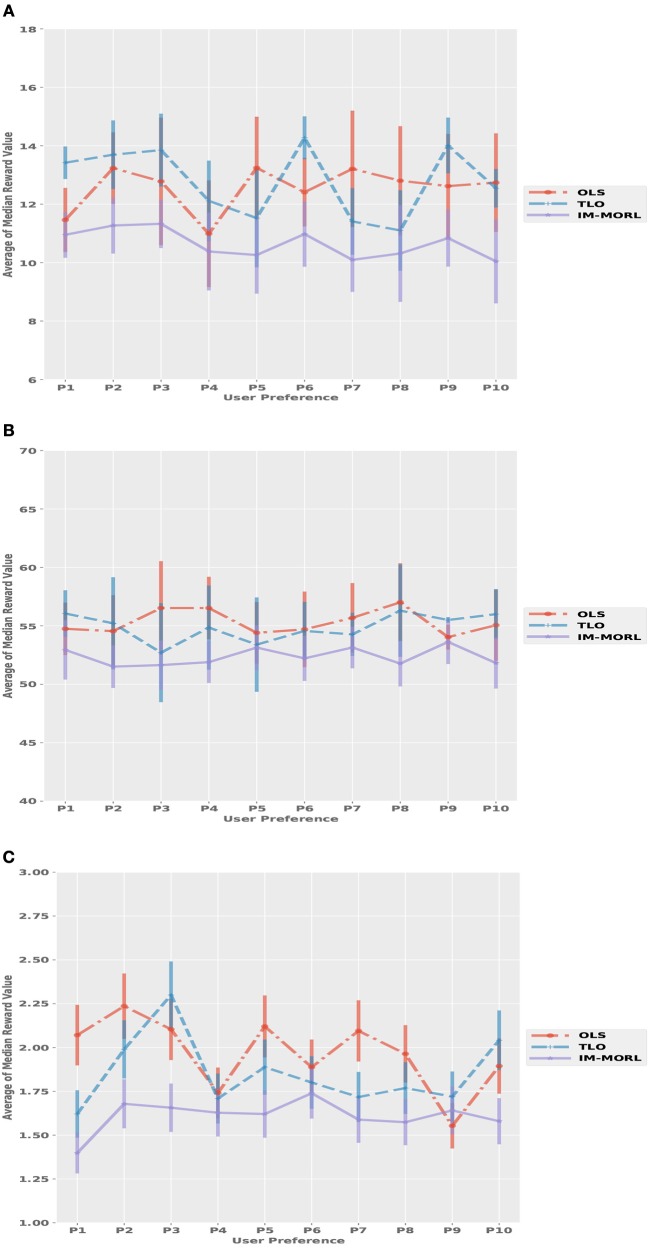
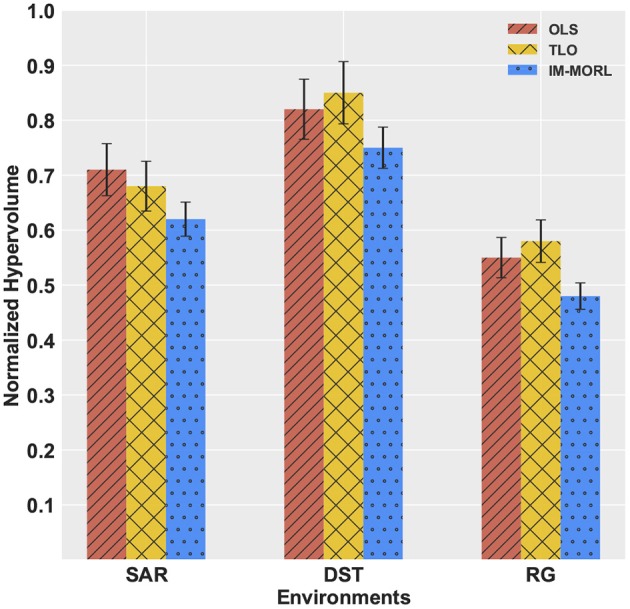
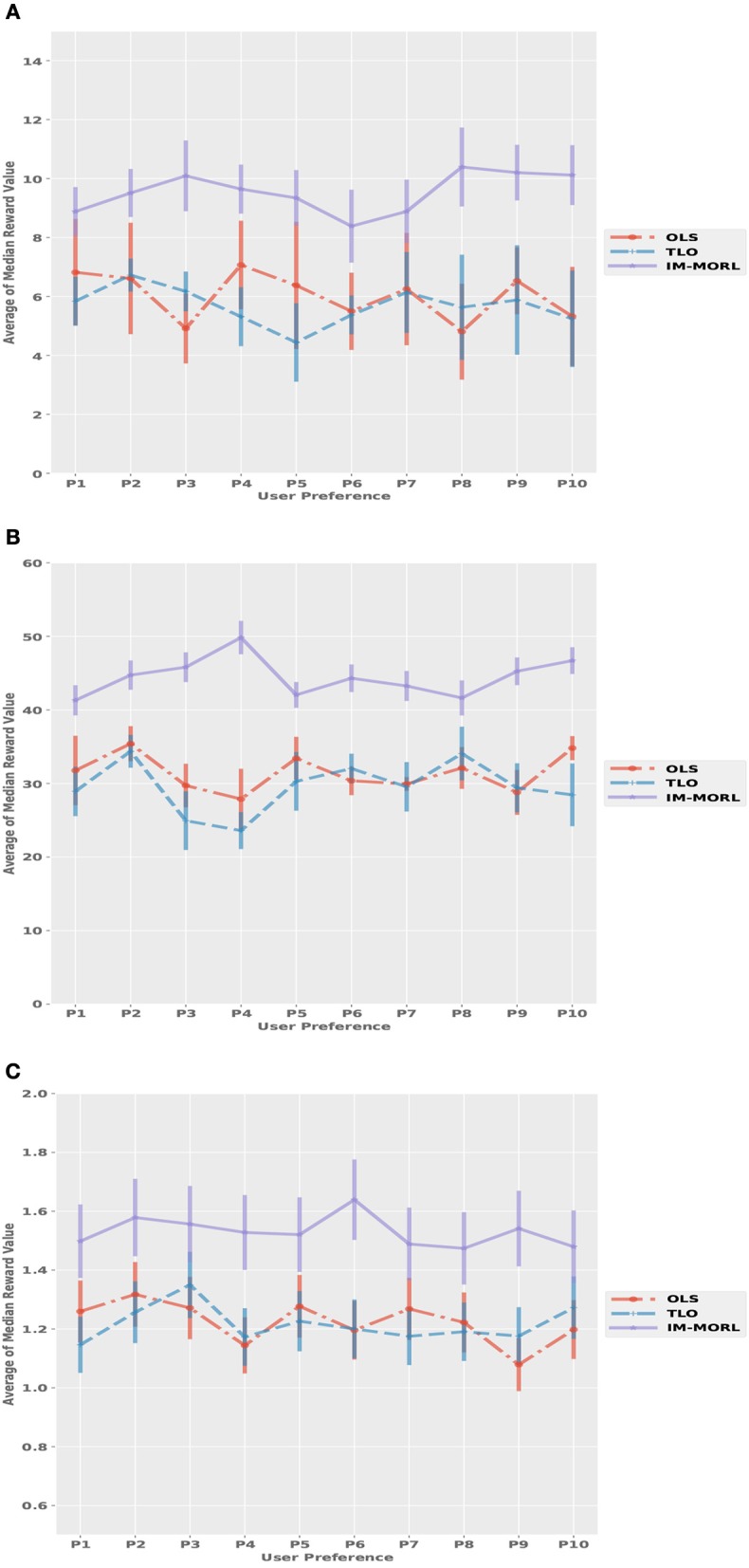
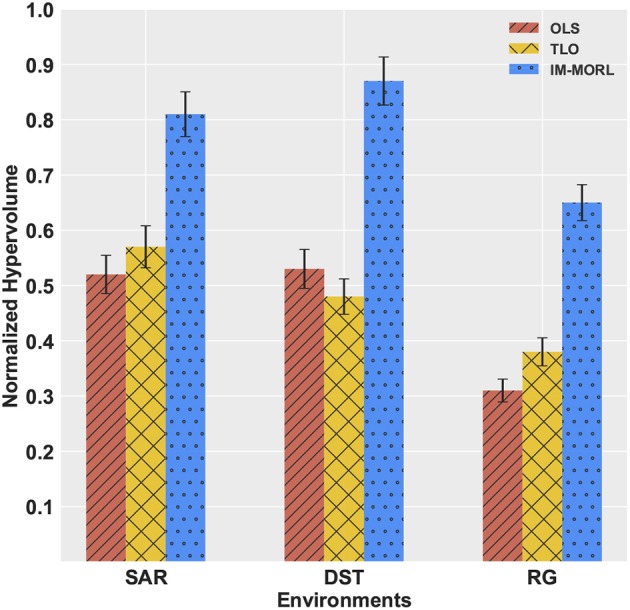
Many real-world decision-making problems involve multiple conflicting objectives that can not be optimized simultaneously without a compromise. Such problems are known as multi-objective Markov decision processes and they constitute a significant challenge for conventional single-objective reinforcement learning methods, especially when an optimal compromise cannot be determined beforehand. Multi-objective reinforcement learning methods address this challenge by finding an optimal coverage set of non-dominated policies that can satisfy any user's preference in solving the problem. However, this is achieved with costs of computational complexity, time consumption, and lack of adaptability to non-stationary environment dynamics. In order to address these limitations, there is a need for adaptive methods that can solve the problem in an online and robust manner. In this paper, we propose a novel developmental method that utilizes the adversarial self-play between an intrinsically motivated preference exploration component, and a policy coverage set optimization component that robustly evolves a convex coverage set of policies to solve the problem using preferences proposed by the former component. We show experimentally the effectiveness of the proposed method in comparison to state-of-the-art multi-objective reinforcement learning methods in stationary and non-stationary environments.
Keywords: Markov process; adversarial; decision making; intrinsic motivation; multi-objective optimization; reinforcement learning; self-play.
Figures

Similar articles
-
MO-MIX: Multi-Objective Multi-Agent Cooperative Decision-Making With Deep Reinforcement Learning.IEEE Trans Pattern Anal Mach Intell. 2023 Oct;45(10):12098-12112. doi: 10.1109/TPAMI.2023.3283537. Epub 2023 Sep 5. IEEE Trans Pattern Anal Mach Intell. 2023. PMID: 37285257
-
Robust Multiobjective Reinforcement Learning Considering Environmental Uncertainties.IEEE Trans Neural Netw Learn Syst. 2025 Apr;36(4):6368-6382. doi: 10.1109/TNNLS.2024.3397393. Epub 2025 Apr 4. IEEE Trans Neural Netw Learn Syst. 2025. PMID: 38781066
-
An Improved Approach towards Multi-Agent Pursuit-Evasion Game Decision-Making Using Deep Reinforcement Learning.Entropy (Basel). 2021 Oct 29;23(11):1433. doi: 10.3390/e23111433. Entropy (Basel). 2021. PMID: 34828131 Free PMC article.
-
Risk management frameworks for human health and environmental risks.J Toxicol Environ Health B Crit Rev. 2003 Nov-Dec;6(6):569-720. doi: 10.1080/10937400390208608. J Toxicol Environ Health B Crit Rev. 2003. PMID: 14698953 Review.
-
Enriching behavioral ecology with reinforcement learning methods.Behav Processes. 2019 Apr;161:94-100. doi: 10.1016/j.beproc.2018.01.008. Epub 2018 Feb 13. Behav Processes. 2019. PMID: 29412143 Review.
References
-
- Akrour R., Schoenauer M., Sebag M. (2011). Preference-Based Policy Learning. Berlin; Heidelberg: Springer Berlin Heidelberg.
-
- Altman E. (1999). Constrained Markov Decision Processes, Vol. 7. London: CRC Press.
-
- Barto A. G. (2013). Intrinsic motivation and reinforcement learning, in Intrinsically Motivated Learning in Natural and Artificial Systems, eds Baldassarre G., Mirolli M. (Berlin; Heidelberg: Springer; ), 17–47.
-
- Beume N., Fonseca C. M., Lopez-Ibanez M., Paquete L., Vahrenhold J. (2009). On the complexity of computing the hypervolume indicator. IEEE Trans. Evol. Comput. 13, 1075–1082. 10.1109/TEVC.2009.2015575 - DOI
-
- Busa-Fekete R., Szörényi B., Weng P., Cheng W., Hüllermeier E. (2014). Preference-based reinforcement learning: evolutionary direct policy search using a preference-based racing algorithm. Mach. Learn. 97, 327–351. 10.1007/s10994-014-5458-8 - DOI
LinkOut - more resources
Full Text Sources