

CATH: expanding the horizons of structure-based functional annotations for genome sequences
- PMID: 30398663
- PMCID: PMC6323983
- DOI: 10.1093/nar/gky1097
CATH: expanding the horizons of structure-based functional annotations for genome sequences
Abstract
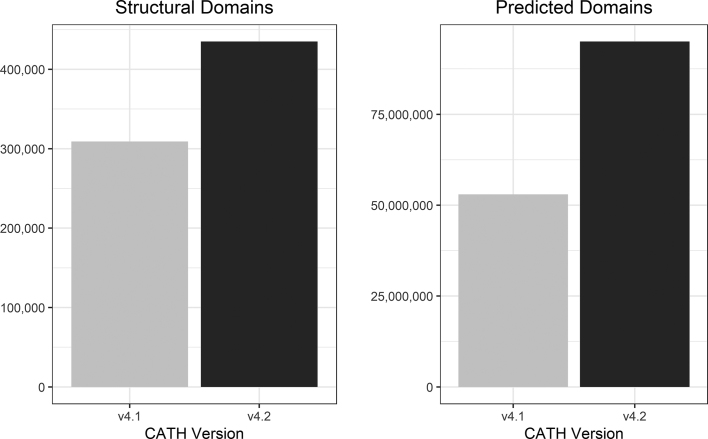
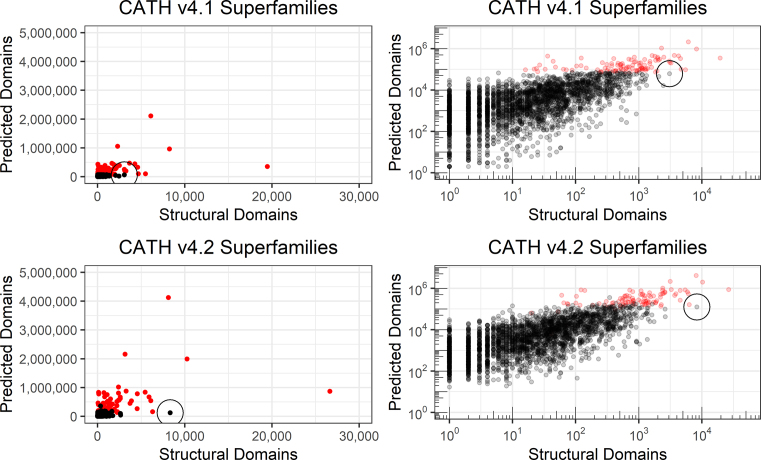
This article provides an update of the latest data and developments within the CATH protein structure classification database (http://www.cathdb.info). The resource provides two levels of release: CATH-B, a daily snapshot of the latest structural domain boundaries and superfamily assignments, and CATH+, which adds layers of derived data, such as predicted sequence domains, functional annotations and functional clustering (known as Functional Families or FunFams). The most recent CATH+ release (version 4.2) provides a huge update in the coverage of structural data. This release increases the number of fully- classified domains by over 40% (from 308 999 to 434 857 structural domains), corresponding to an almost two- fold increase in sequence data (from 53 million to over 95 million predicted domains) organised into 6119 superfamilies. The coverage of high-resolution, protein PDB chains that contain at least one assigned CATH domain is now 90.2% (increased from 82.3% in the previous release). A number of highly requested features have also been implemented in our web pages: allowing the user to view an alignment between their query sequence and a representative FunFam structure and providing tools that make it easier to view the full structural context (multi-domain architecture) of domains and chains.
Figures
References
-
- Orengo C.A., Taylor W.R.. SSAP: sequential structure alignment program for protein structure comparison. Methods Enzymol. 1996; 266:617–635. - PubMed
Publication types
MeSH terms
Grants and funding
- BB/K020013/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- 203780/Z/16/A/WT_/Wellcome Trust/United Kingdom
- BB/N019253/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- WT_/Wellcome Trust/United Kingdom
- 104960/Z/14/Z /WT_/Wellcome Trust/United Kingdom
LinkOut - more resources
Full Text Sources
