

Assessment of Convolutional Neural Networks for Automated Classification of Chest Radiographs
- PMID: 30422093
- PMCID: PMC6358056
- DOI: 10.1148/radiol.2018181422
Assessment of Convolutional Neural Networks for Automated Classification of Chest Radiographs
Abstract
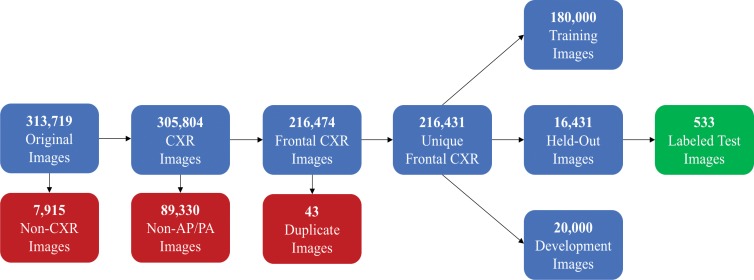
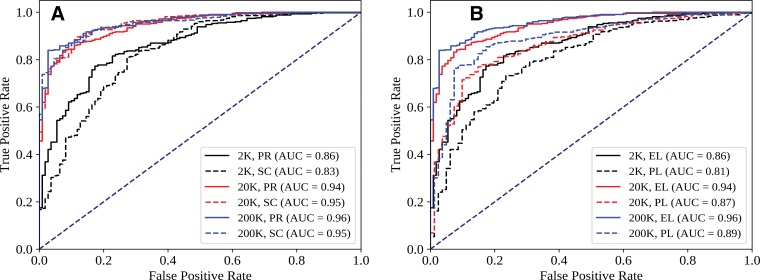
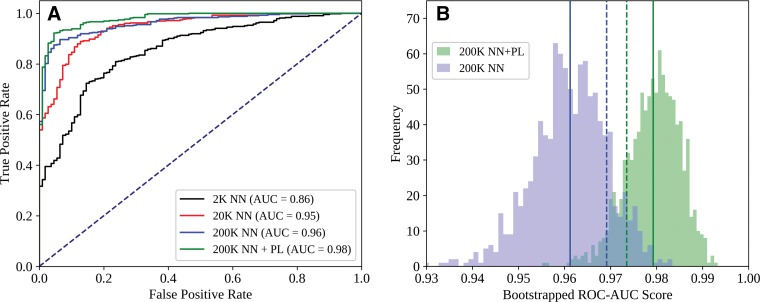
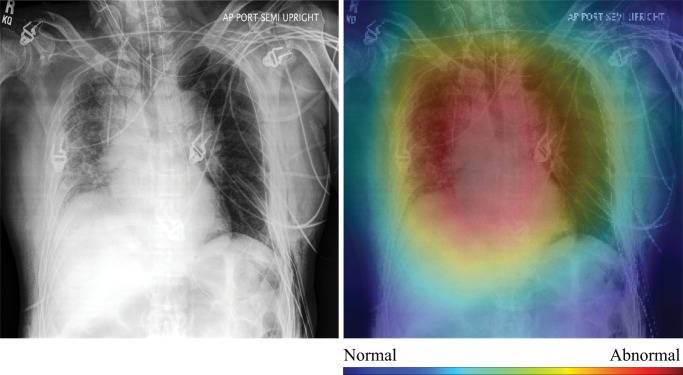
Purpose To assess the ability of convolutional neural networks (CNNs) to enable high-performance automated binary classification of chest radiographs. Materials and Methods In a retrospective study, 216 431 frontal chest radiographs obtained between 1998 and 2012 were procured, along with associated text reports and a prospective label from the attending radiologist. This data set was used to train CNNs to classify chest radiographs as normal or abnormal before evaluation on a held-out set of 533 images hand-labeled by expert radiologists. The effects of development set size, training set size, initialization strategy, and network architecture on end performance were assessed by using standard binary classification metrics; detailed error analysis, including visualization of CNN activations, was also performed. Results Average area under the receiver operating characteristic curve (AUC) was 0.96 for a CNN trained with 200 000 images. This AUC value was greater than that observed when the same model was trained with 2000 images (AUC = 0.84, P < .005) but was not significantly different from that observed when the model was trained with 20 000 images (AUC = 0.95, P > .05). Averaging the CNN output score with the binary prospective label yielded the best-performing classifier, with an AUC of 0.98 (P < .005). Analysis of specific radiographs revealed that the model was heavily influenced by clinically relevant spatial regions but did not reliably generalize beyond thoracic disease. Conclusion CNNs trained with a modestly sized collection of prospectively labeled chest radiographs achieved high diagnostic performance in the classification of chest radiographs as normal or abnormal; this function may be useful for automated prioritization of abnormal chest radiographs. © RSNA, 2018 Online supplemental material is available for this article. See also the editorial by van Ginneken in this issue.
Figures
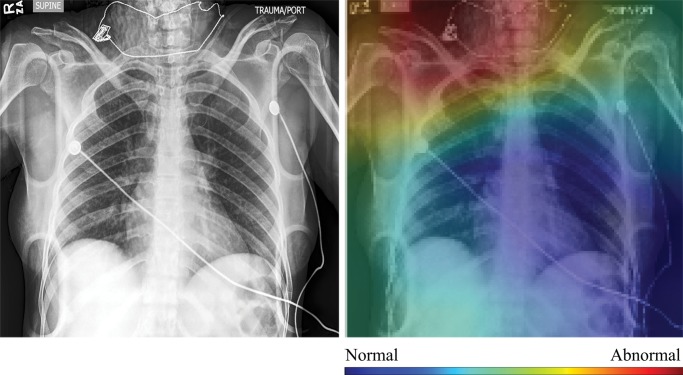
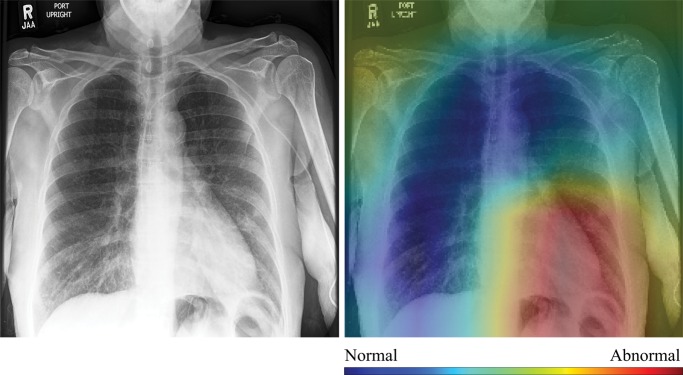
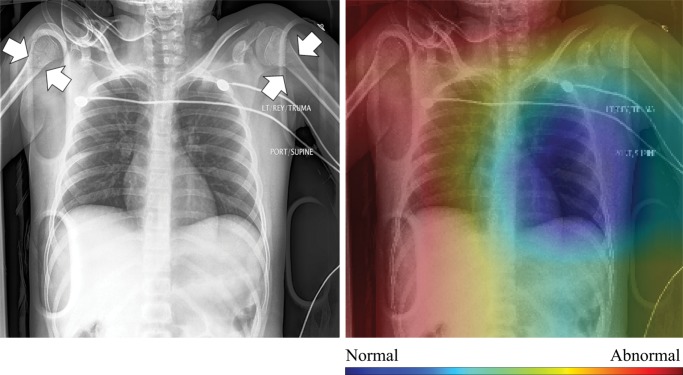
Comment in
-
Deep Learning for Triage of Chest Radiographs: Should Every Institution Train Its Own System?Radiology. 2019 Feb;290(2):545-546. doi: 10.1148/radiol.2018182318. Epub 2018 Nov 13. Radiology. 2019. PMID: 30422089 No abstract available.
References
-
- Rimmer A. Radiologist shortage leaves patient care at risk, warns royal college. BMJ 2017;359:j4683. - PubMed
-
- Rosman DA, Nshizirungu JJ, Rudakemwa E, et al. Imaging in the land of 1000 hills: Rwanda radiology country report. J Glob Radiol 2015;1(1):6.
-
- Ali FS, Harrington SG, Kennedy SB, Hussain S. Diagnostic radiology in Liberia: a country report. J Glob Radiol 2015;1(1):6.
-
- LeCun Y, Bengio Y, Hinton G. Deep learning. Nature 2015;521(7553):436–444. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
