

Code Generation in Computational Neuroscience: A Review of Tools and Techniques
- PMID: 30455637
- PMCID: PMC6230720
- DOI: 10.3389/fninf.2018.00068
Code Generation in Computational Neuroscience: A Review of Tools and Techniques
Abstract
Advances in experimental techniques and computational power allowing researchers to gather anatomical and electrophysiological data at unprecedented levels of detail have fostered the development of increasingly complex models in computational neuroscience. Large-scale, biophysically detailed cell models pose a particular set of computational challenges, and this has led to the development of a number of domain-specific simulators. At the other level of detail, the ever growing variety of point neuron models increases the implementation barrier even for those based on the relatively simple integrate-and-fire neuron model. Independently of the model complexity, all modeling methods crucially depend on an efficient and accurate transformation of mathematical model descriptions into efficiently executable code. Neuroscientists usually publish model descriptions in terms of the mathematical equations underlying them. However, actually simulating them requires they be translated into code. This can cause problems because errors may be introduced if this process is carried out by hand, and code written by neuroscientists may not be very computationally efficient. Furthermore, the translated code might be generated for different hardware platforms, operating system variants or even written in different languages and thus cannot easily be combined or even compared. Two main approaches to addressing this issues have been followed. The first is to limit users to a fixed set of optimized models, which limits flexibility. The second is to allow model definitions in a high level interpreted language, although this may limit performance. Recently, a third approach has become increasingly popular: using code generation to automatically translate high level descriptions into efficient low level code to combine the best of previous approaches. This approach also greatly enriches efforts to standardize simulator-independent model description languages. In the past few years, a number of code generation pipelines have been developed in the computational neuroscience community, which differ considerably in aim, scope and functionality. This article provides an overview of existing pipelines currently used within the community and contrasts their capabilities and the technologies and concepts behind them.
Keywords: code generation; domain specific language; modeling language; neuronal networks; simulation.
Figures
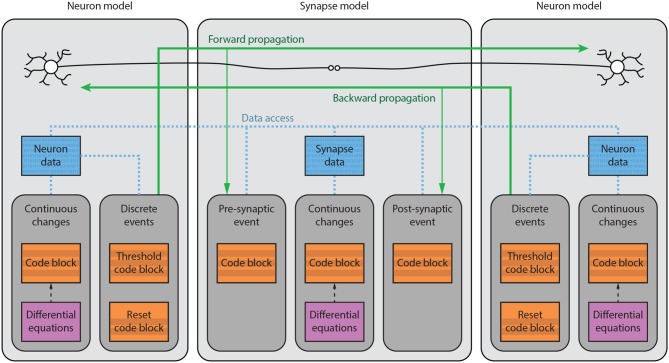

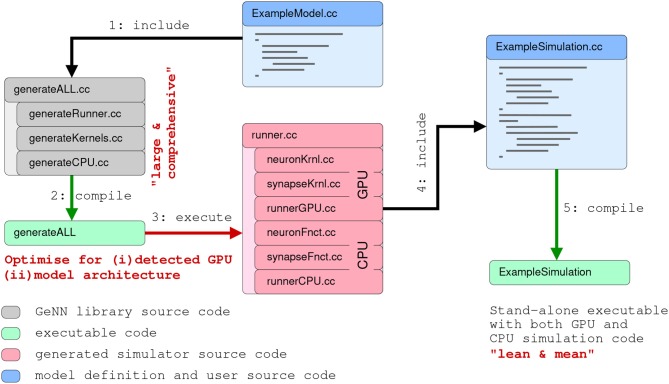
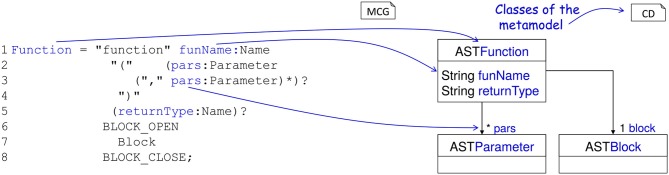
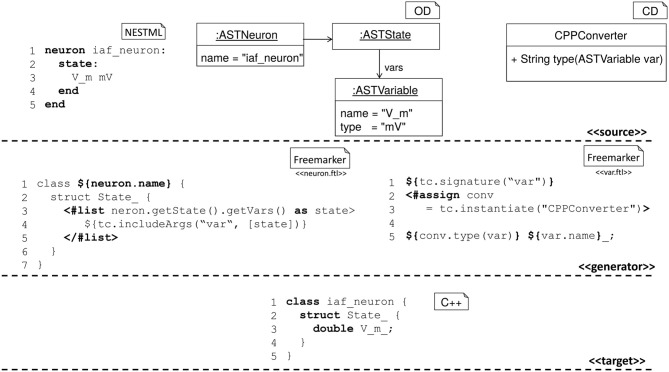
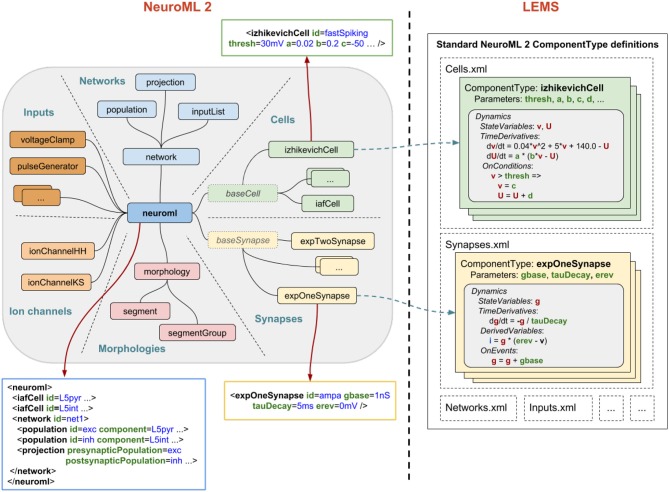
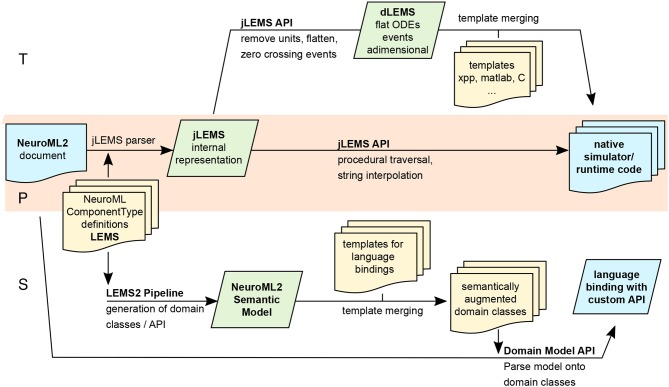
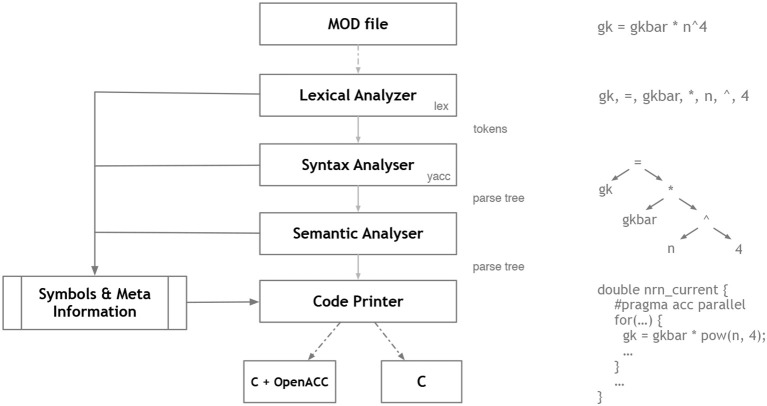

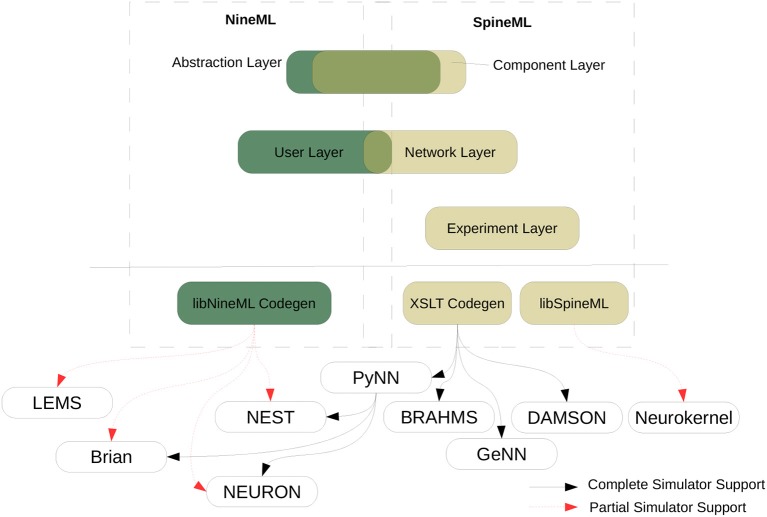
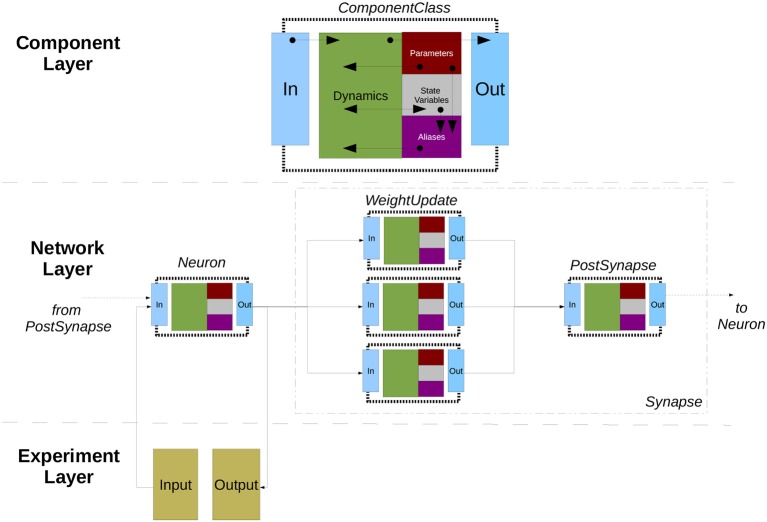


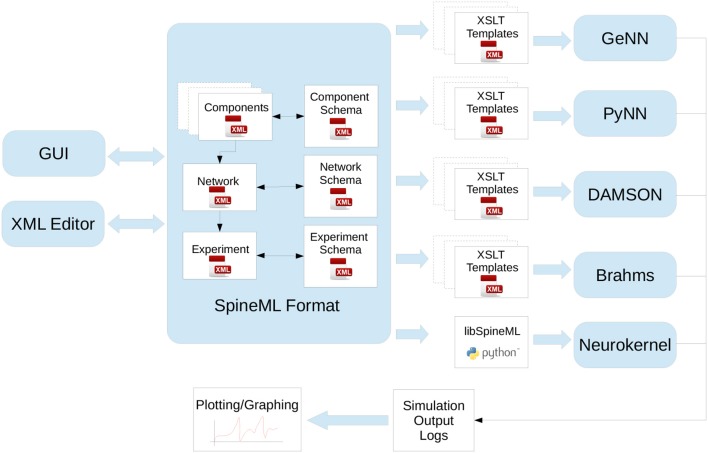

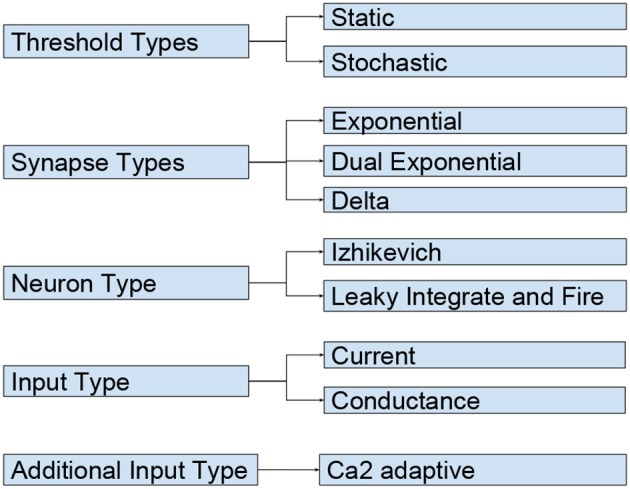
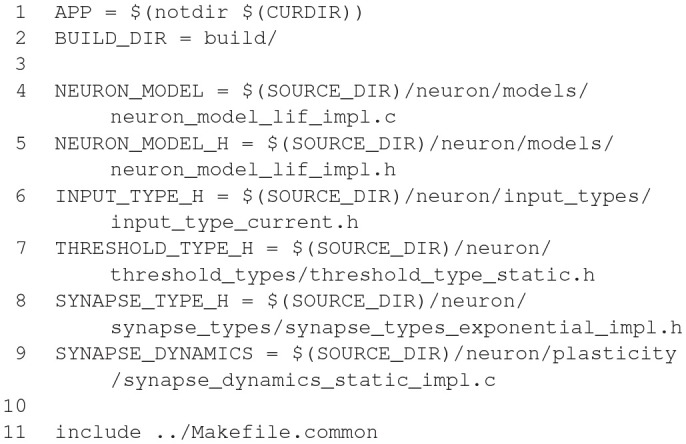
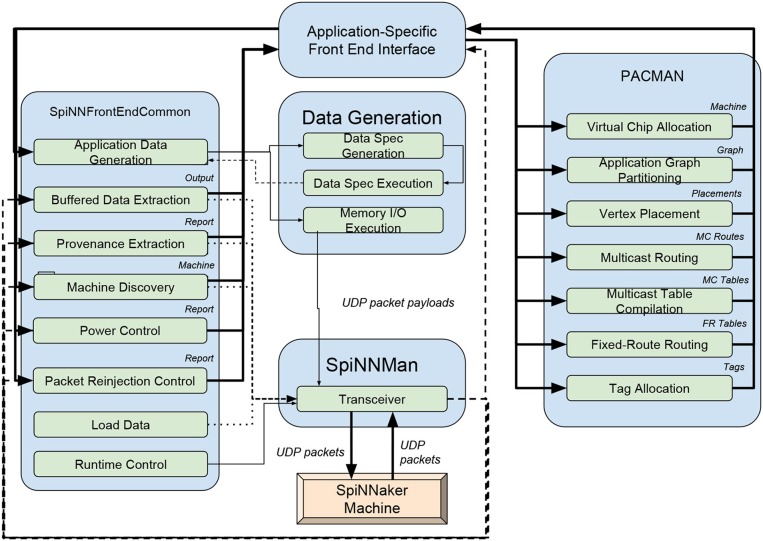
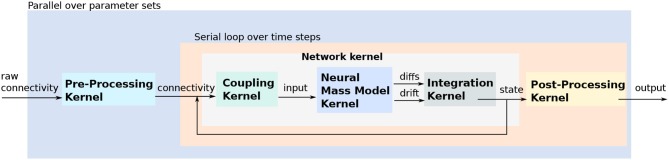









References
-
- Aamir S. A., Müller P., Kriener L., Kiene G., Schemmel J., Meier K. (2017). From LIF to AdEx neuron models: accelerated analog 65-nm CMOS implementation in IEEE Biomedical Circuits and Systems Conference (BioCAS) (Turin: ). - PubMed
-
- Aho A. V., Lam M. S., Sethi R., Ullman J. D. (2006). Compilers: Principles, Techniques, and Tools, (2nd Edn). Boston, MA: Addison-Wesley Longman Publishing Co., Inc.
-
- ARM Limited (2006). Arm968e-s Technical Reference Manual.
-
- Bhalla U. S., Bower J. M. (1993). Genesis: a neuronal simulation system in Neural Systems: Analysis and Modeling (New York, NY: ), 95–102.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous