

Adaptive stimulus selection for multi-alternative psychometric functions with lapses
- PMID: 30458512
- PMCID: PMC6222824
- DOI: 10.1167/18.12.4
Adaptive stimulus selection for multi-alternative psychometric functions with lapses
Abstract
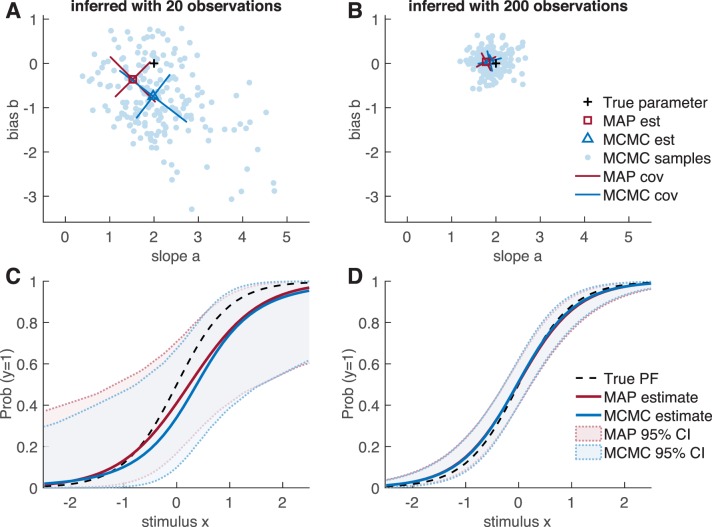
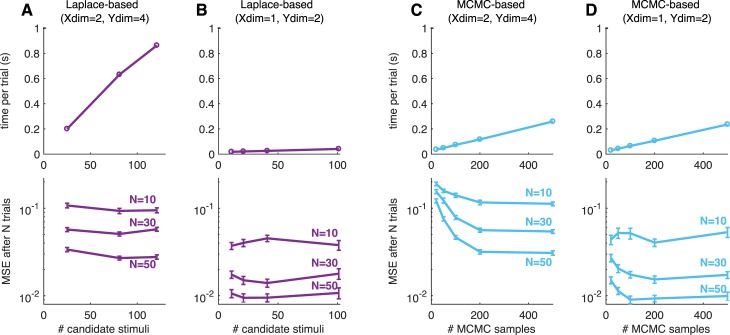
Psychometric functions (PFs) quantify how external stimuli affect behavior, and they play an important role in building models of sensory and cognitive processes. Adaptive stimulus-selection methods seek to select stimuli that are maximally informative about the PF given data observed so far in an experiment and thereby reduce the number of trials required to estimate the PF. Here we develop new adaptive stimulus-selection methods for flexible PF models in tasks with two or more alternatives. We model the PF with a multinomial logistic regression mixture model that incorporates realistic aspects of psychophysical behavior, including lapses and multiple alternatives for the response. We propose an information-theoretic criterion for stimulus selection and develop computationally efficient methods for inference and stimulus selection based on adaptive Markov-chain Monte Carlo sampling. We apply these methods to data from macaque monkeys performing a multi-alternative motion-discrimination task and show in simulated experiments that our method can achieve a substantial speed-up over random designs. These advances will reduce the amount of data needed to build accurate models of multi-alternative PFs and can be extended to high-dimensional PFs that would be infeasible to characterize with standard methods.
Figures








References
-
- Bak J. H, Choi J. Y, Akrami A, Witten I. B, Pillow J. W. Adaptive optimal training of animal behavior. In: Lee D. D, Sugiyama M, Luxburg U. V, Guyon I, Garnett R, editors. Advances in neural information processing systems 29. Red Hook, NY: Curran Associates, Inc; (2016). pp. 1947–1955. (Eds.)
-
- Barthelmé S, Mamassian P. A flexible Bayesian method for adaptive measurement in psychophysics. arXiv:0809.0387. (2008). pp. 1–28.
-
- Bishop C. M. Pattern recognition and machine learning. New York: Springer; (2006).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
