

Self-organising coordinate transformation with peaked and monotonic gain modulation in the primate dorsal visual pathway
- PMID: 30496225
- PMCID: PMC6264903
- DOI: 10.1371/journal.pone.0207961
Self-organising coordinate transformation with peaked and monotonic gain modulation in the primate dorsal visual pathway
Abstract
We study a self-organising neural network model of how visual representations in the primate dorsal visual pathway are transformed from an eye-centred to head-centred frame of reference. The model has previously been shown to robustly develop head-centred output neurons with a standard trace learning rule, but only under limited conditions. Specifically it fails when incorporating visual input neurons with monotonic gain modulation by eye-position. Since eye-centred neurons with monotonic gain modulation are so common in the dorsal visual pathway, it is an important challenge to show how efferent synaptic connections from these neurons may self-organise to produce head-centred responses in a subpopulation of postsynaptic neurons. We show for the first time how a variety of modified, yet still biologically plausible, versions of the standard trace learning rule enable the model to perform a coordinate transformation from eye-centred to head-centred reference frames when the visual input neurons have monotonic gain modulation by eye-position.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures


















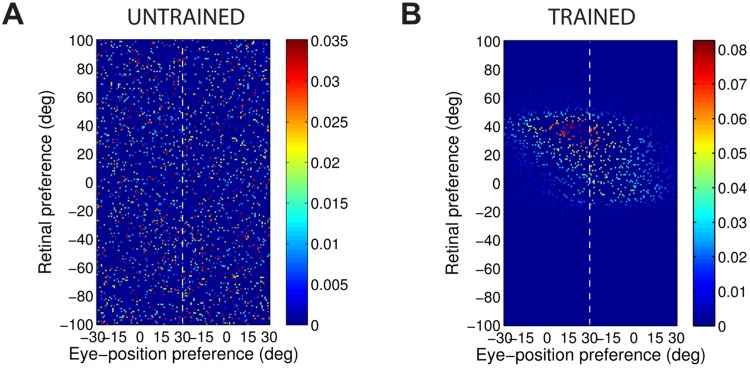



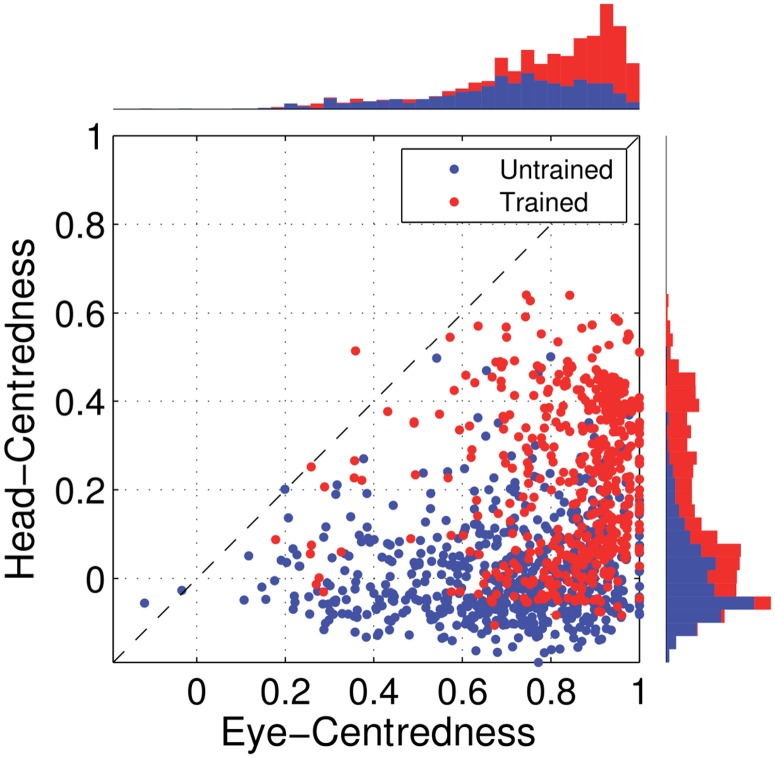



References
-
- Andersen RA, Mountcastle VB. The influence of the angle of gaze upon the excitability of the light-sensitive neurons of the posterior parietal cortex. The Journal of Neuroscience. 1983;3(3):532–548. 10.1523/JNEUROSCI.03-03-00532.1983 - DOI - PMC - PubMed
-
- Andersen R, Essick G, Siegel R. Encoding of spatial location by posterior parietal neurons. Science. 1985;230(4724):456–458. 10.1126/science.4048942 - DOI - PubMed
-
- Andersen R, Bracewell R, Barash S, Gnadt J, Fogassi L. Eye position effects on visual, memory, and saccade-related activity in areas LIP and 7a of macaque. The Journal of Neuroscience. 1990;10(4):1176–1196. 10.1523/JNEUROSCI.10-04-01176.1990 - DOI - PMC - PubMed
-
- Galletti C, Battaglini P, Fattori P. Eye Position Influence on the Parieto-occipital Area PO of the Macaque Monkey. European Journal of Neuroscience. 1995;7(12):2486–2501. 10.1111/j.1460-9568.1995.tb01047.x - DOI - PubMed
-
- Mullette-Gillman OA, Cohen YE, Groh JM. Eye-Centered, Head-Centered, and Complex Coding of Visual and Auditory Targets in the Intraparietal Sulcus. Journal of Neurophysiology. 2005;94(4):2331–2352. 10.1152/jn.00021.2005 - DOI - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
