

Recurrent Spiking Neural Network Learning Based on a Competitive Maximization of Neuronal Activity
- PMID: 30498439
- PMCID: PMC6250118
- DOI: 10.3389/fninf.2018.00079
Recurrent Spiking Neural Network Learning Based on a Competitive Maximization of Neuronal Activity
Abstract
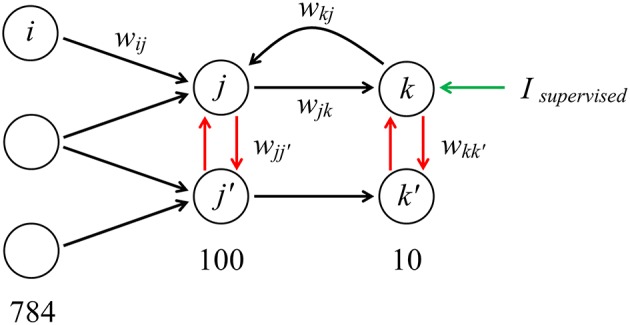
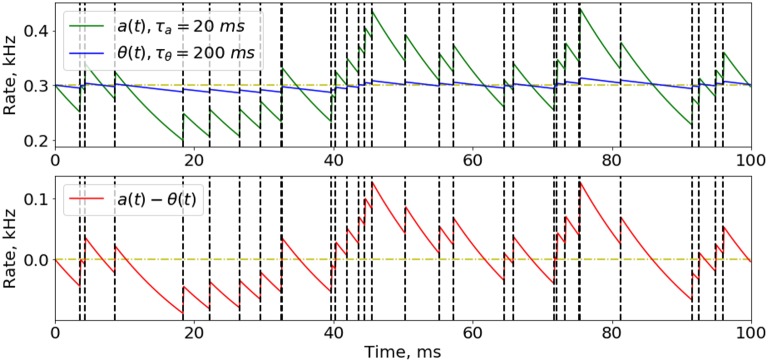
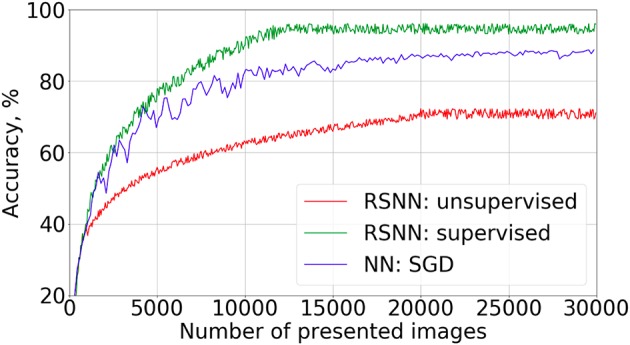
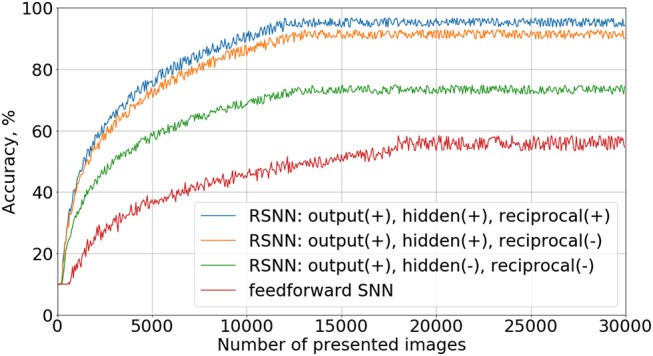
Spiking neural networks (SNNs) are believed to be highly computationally and energy efficient for specific neurochip hardware real-time solutions. However, there is a lack of learning algorithms for complex SNNs with recurrent connections, comparable in efficiency with back-propagation techniques and capable of unsupervised training. Here we suppose that each neuron in a biological neural network tends to maximize its activity in competition with other neurons, and put this principle at the basis of a new SNN learning algorithm. In such a way, a spiking network with the learned feed-forward, reciprocal and intralayer inhibitory connections, is introduced to the MNIST database digit recognition. It has been demonstrated that this SNN can be trained without a teacher, after a short supervised initialization of weights by the same algorithm. Also, it has been shown that neurons are grouped into families of hierarchical structures, corresponding to different digit classes and their associations. This property is expected to be useful to reduce the number of layers in deep neural networks and modeling the formation of various functional structures in a biological nervous system. Comparison of the learning properties of the suggested algorithm, with those of the Sparse Distributed Representation approach shows similarity in coding but also some advantages of the former. The basic principle of the proposed algorithm is believed to be practically applicable to the construction of much more complicated and diverse task solving SNNs. We refer to this new approach as "Family-Engaged Execution and Learning of Induced Neuron Groups," or FEELING.
Keywords: classification; digits recognition; neuron clustering; spiking neural networks; supervised learning; unsupervised learning.
Figures


Similar articles
-
Competitive Learning in a Spiking Neural Network: Towards an Intelligent Pattern Classifier.Sensors (Basel). 2020 Jan 16;20(2):500. doi: 10.3390/s20020500. Sensors (Basel). 2020. PMID: 31963143 Free PMC article.
-
Spiking neural networks for handwritten digit recognition-Supervised learning and network optimization.Neural Netw. 2018 Jul;103:118-127. doi: 10.1016/j.neunet.2018.03.019. Epub 2018 Apr 6. Neural Netw. 2018. PMID: 29674234
-
SSTDP: Supervised Spike Timing Dependent Plasticity for Efficient Spiking Neural Network Training.Front Neurosci. 2021 Nov 4;15:756876. doi: 10.3389/fnins.2021.756876. eCollection 2021. Front Neurosci. 2021. PMID: 34803591 Free PMC article.
-
Deep Learning With Spiking Neurons: Opportunities and Challenges.Front Neurosci. 2018 Oct 25;12:774. doi: 10.3389/fnins.2018.00774. eCollection 2018. Front Neurosci. 2018. PMID: 30410432 Free PMC article. Review.
-
Deep learning in spiking neural networks.Neural Netw. 2019 Mar;111:47-63. doi: 10.1016/j.neunet.2018.12.002. Epub 2018 Dec 18. Neural Netw. 2019. PMID: 30682710 Review.
Cited by
-
Learnable Leakage and Onset-Spiking Self-Attention in SNNs with Local Error Signals.Sensors (Basel). 2023 Dec 12;23(24):9781. doi: 10.3390/s23249781. Sensors (Basel). 2023. PMID: 38139626 Free PMC article.
-
CRBA: A Competitive Rate-Based Algorithm Based on Competitive Spiking Neural Networks.Front Comput Neurosci. 2021 Apr 22;15:627567. doi: 10.3389/fncom.2021.627567. eCollection 2021. Front Comput Neurosci. 2021. PMID: 33967726 Free PMC article.
-
Topological features of spike trains in recurrent spiking neural networks that are trained to generate spatiotemporal patterns.Front Comput Neurosci. 2024 Feb 23;18:1363514. doi: 10.3389/fncom.2024.1363514. eCollection 2024. Front Comput Neurosci. 2024. PMID: 38463243 Free PMC article.
-
Unsupervised Spiking Neural Network with Dynamic Learning of Inhibitory Neurons.Sensors (Basel). 2023 Aug 17;23(16):7232. doi: 10.3390/s23167232. Sensors (Basel). 2023. PMID: 37631767 Free PMC article.
-
Heterogeneous recurrent spiking neural network for spatio-temporal classification.Front Neurosci. 2023 Jan 30;17:994517. doi: 10.3389/fnins.2023.994517. eCollection 2023. Front Neurosci. 2023. PMID: 36793542 Free PMC article.
References
-
- Barlow H. (1961). Possible principles underlying the transformations of sensory messages, in Sensory Communication, ed Rosenblith W. A. (Cambridge, MA: MIT Press; ), 217–234.
-
- Bottou L. (1998). Online algorithms and stochastic approximations, in Online Learning and Neural Networks, ed Saad D. (Cambridge: Cambridge University Press; ), 9–42.
LinkOut - more resources
Full Text Sources
Other Literature Sources