

Neural responses to natural and model-matched stimuli reveal distinct computations in primary and nonprimary auditory cortex
- PMID: 30507943
- PMCID: PMC6292651
- DOI: 10.1371/journal.pbio.2005127
Neural responses to natural and model-matched stimuli reveal distinct computations in primary and nonprimary auditory cortex
Abstract
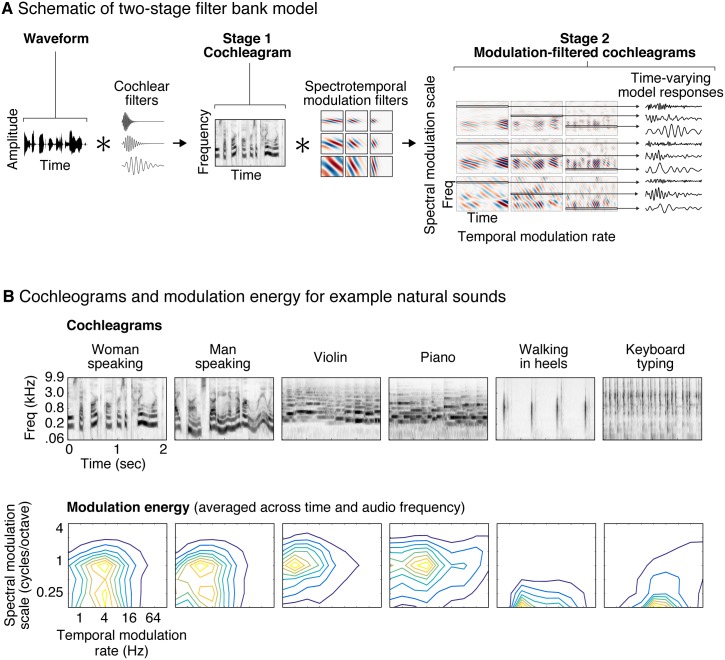
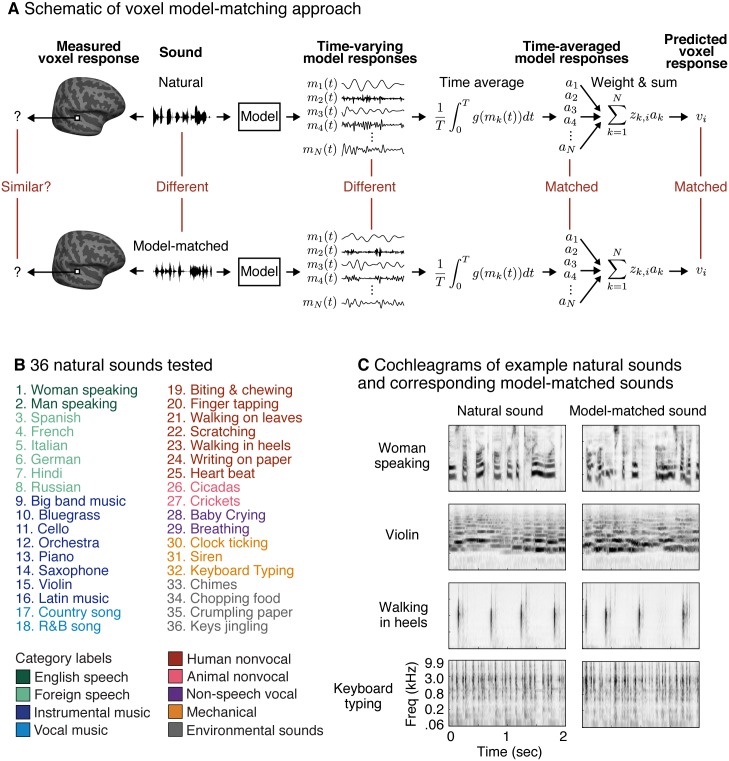
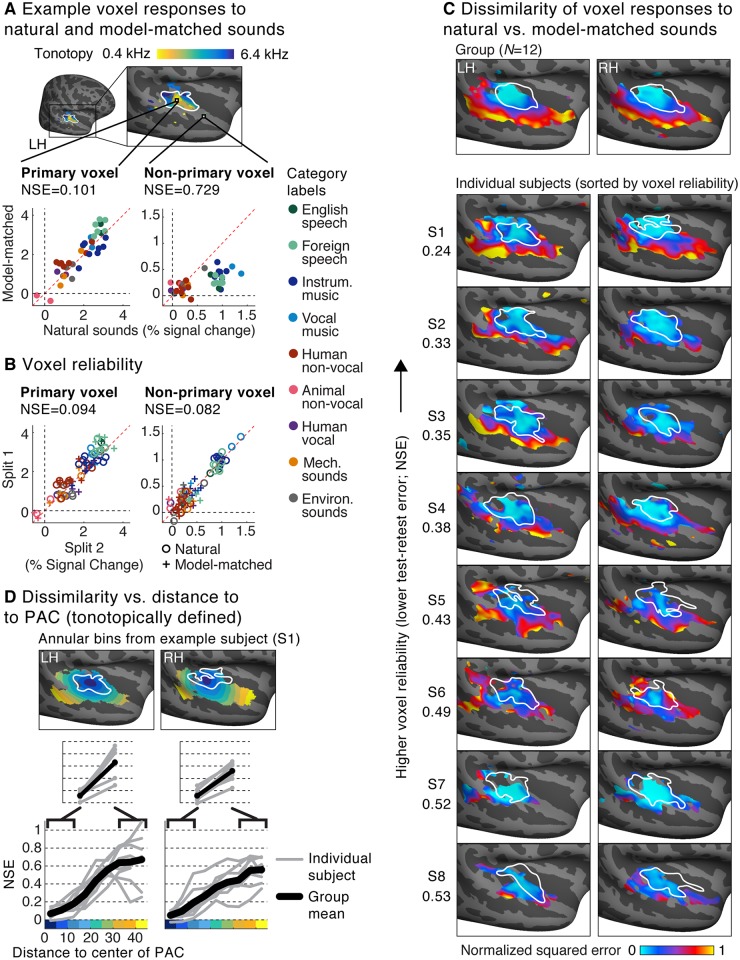
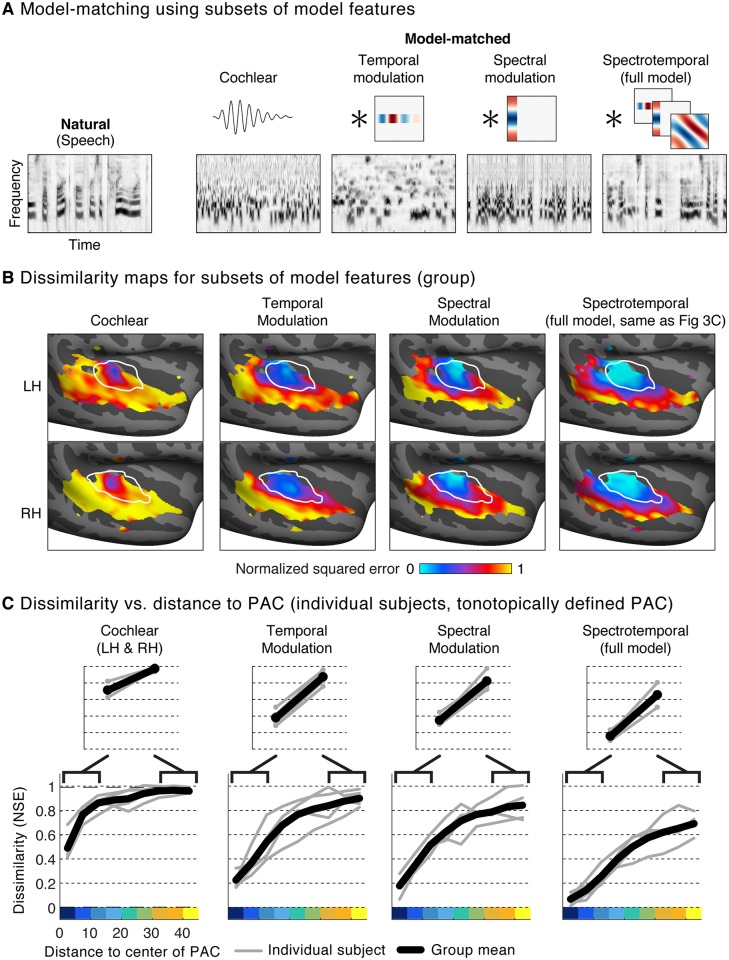
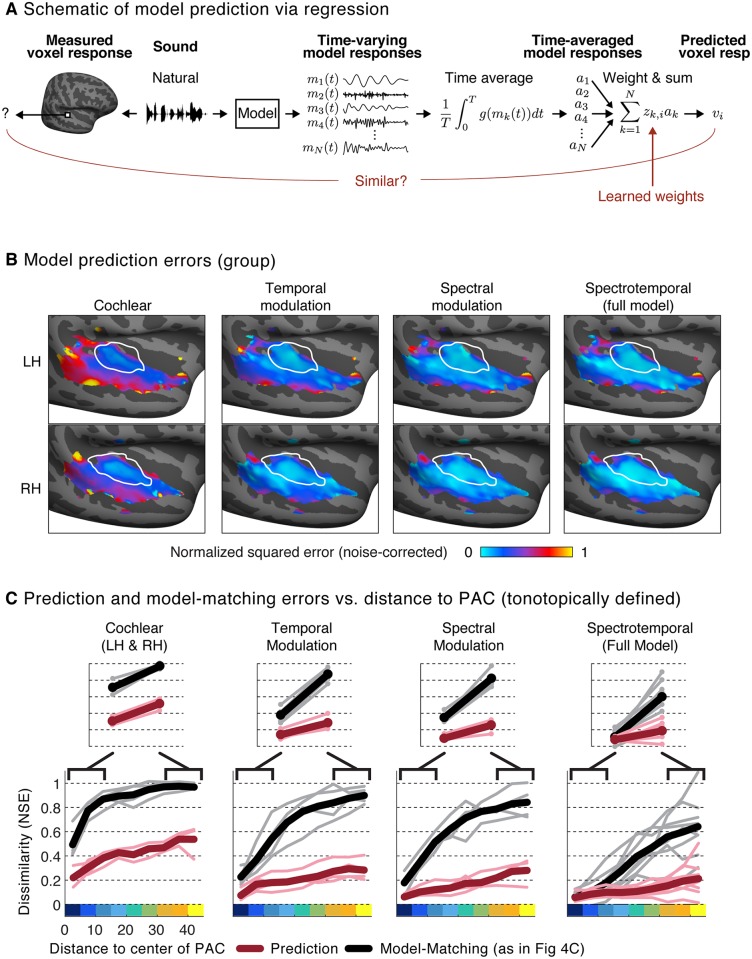
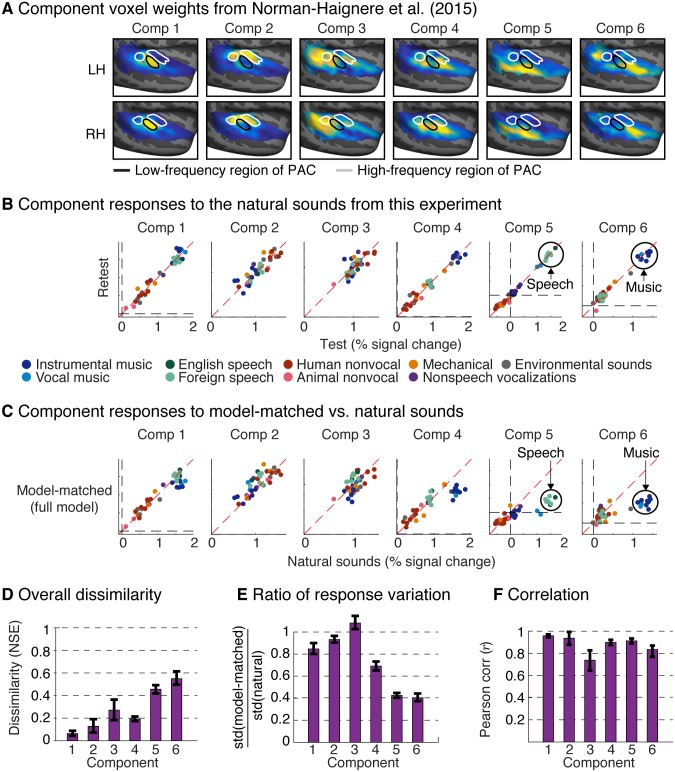
A central goal of sensory neuroscience is to construct models that can explain neural responses to natural stimuli. As a consequence, sensory models are often tested by comparing neural responses to natural stimuli with model responses to those stimuli. One challenge is that distinct model features are often correlated across natural stimuli, and thus model features can predict neural responses even if they do not in fact drive them. Here, we propose a simple alternative for testing a sensory model: we synthesize a stimulus that yields the same model response as each of a set of natural stimuli, and test whether the natural and "model-matched" stimuli elicit the same neural responses. We used this approach to test whether a common model of auditory cortex-in which spectrogram-like peripheral input is processed by linear spectrotemporal filters-can explain fMRI responses in humans to natural sounds. Prior studies have that shown that this model has good predictive power throughout auditory cortex, but this finding could reflect feature correlations in natural stimuli. We observed that fMRI responses to natural and model-matched stimuli were nearly equivalent in primary auditory cortex (PAC) but that nonprimary regions, including those selective for music or speech, showed highly divergent responses to the two sound sets. This dissociation between primary and nonprimary regions was less clear from model predictions due to the influence of feature correlations across natural stimuli. Our results provide a signature of hierarchical organization in human auditory cortex, and suggest that nonprimary regions compute higher-order stimulus properties that are not well captured by traditional models. Our methodology enables stronger tests of sensory models and could be broadly applied in other domains.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Simoncelli EP, Olshausen BA. Natural image statistics and neural representation. Annu Rev Neurosci. 2001;24: 1193–1216. 10.1146/annurev.neuro.24.1.1193 - DOI - PubMed
-
- Woolley SM, Fremouw TE, Hsu A, Theunissen FE. Tuning for spectro-temporal modulations as a mechanism for auditory discrimination of natural sounds. Nat Neurosci. 2005;8: 1371–1379. 10.1038/nn1536 - DOI - PubMed
-
- Smith EC, Lewicki MS. Efficient auditory coding. Nature. 2006;439: 978–982. 10.1038/nature04485 - DOI - PubMed
-
- Sharpee T, Rust NC, Bialek W. Analyzing neural responses to natural signals: maximally informative dimensions. Neural Comput. 2004;16: 223–250. 10.1162/089976604322742010 - DOI - PubMed
-
- Naselaris T, Kay KN, Nishimoto S, Gallant JL. Encoding and decoding in fMRI. Neuroimage. 2011;56: 400–410. 10.1016/j.neuroimage.2010.07.073 - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
