

Tumor co-segmentation in PET/CT using multi-modality fully convolutional neural network
- PMID: 30523964
- PMCID: PMC7493812
- DOI: 10.1088/1361-6560/aaf44b
Tumor co-segmentation in PET/CT using multi-modality fully convolutional neural network
Abstract
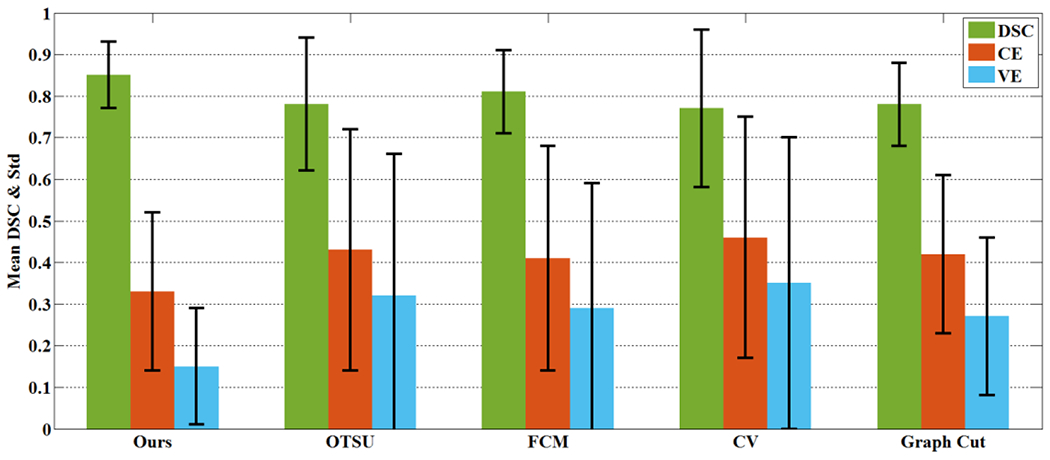
Automatic tumor segmentation from medical images is an important step for computer-aided cancer diagnosis and treatment. Recently, deep learning has been successfully applied to this task, leading to state-of-the-art performance. However, most of existing deep learning segmentation methods only work for a single imaging modality. PET/CT scanner is nowadays widely used in the clinic, and is able to provide both metabolic information and anatomical information through integrating PET and CT into the same utility. In this study, we proposed a novel multi-modality segmentation method based on a 3D fully convolutional neural network (FCN), which is capable of taking account of both PET and CT information simultaneously for tumor segmentation. The network started with a multi-task training module, in which two parallel sub-segmentation architectures constructed using deep convolutional neural networks (CNNs) were designed to automatically extract feature maps from PET and CT respectively. A feature fusion module was subsequently designed based on cascaded convolutional blocks, which re-extracted features from PET/CT feature maps using a weighted cross entropy minimization strategy. The tumor mask was obtained as the output at the end of the network using a softmax function. The effectiveness of the proposed method was validated on a clinic PET/CT dataset of 84 patients with lung cancer. The results demonstrated that the proposed network was effective, fast and robust and achieved significantly performance gain over CNN-based methods and traditional methods using PET or CT only, two V-net based co-segmentation methods, two variational co-segmentation methods based on fuzzy set theory and a deep learning co-segmentation method using W-net.
Figures



















References
-
- Lecun Y, Bengio Y, Hinton G, Deep learning, Nature, 521 (2015) 436–444. - PubMed
-
- Krizhevsky A, Sutskever I, Hinton GE, ImageNet classification with deep convolutional neural networks, in: International Conference on Neural Information Processing Systems, 2012, pp. 1097–1105.
-
- Simonyan K, Zisserman A, Very deep convolutional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556, (2014).
-
- Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A, Going deeper with convolutions, in: Computer Vision and Pattern Recognition, 2015, pp. 1–9.
-
- Gao XW, Hui R, Tian Z, Classification of CT brain images based on deep learning networks, Computer Methods & Programs in Biomedicine, 138 (2017) 49–56. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources