

Strawberry Mottle Virus (Family Secoviridae, Order Picornavirales) Encodes a Novel Glutamic Protease To Process the RNA2 Polyprotein at Two Cleavage Sites
- PMID: 30541838
- PMCID: PMC6384087
- DOI: 10.1128/JVI.01679-18
Strawberry Mottle Virus (Family Secoviridae, Order Picornavirales) Encodes a Novel Glutamic Protease To Process the RNA2 Polyprotein at Two Cleavage Sites
Abstract
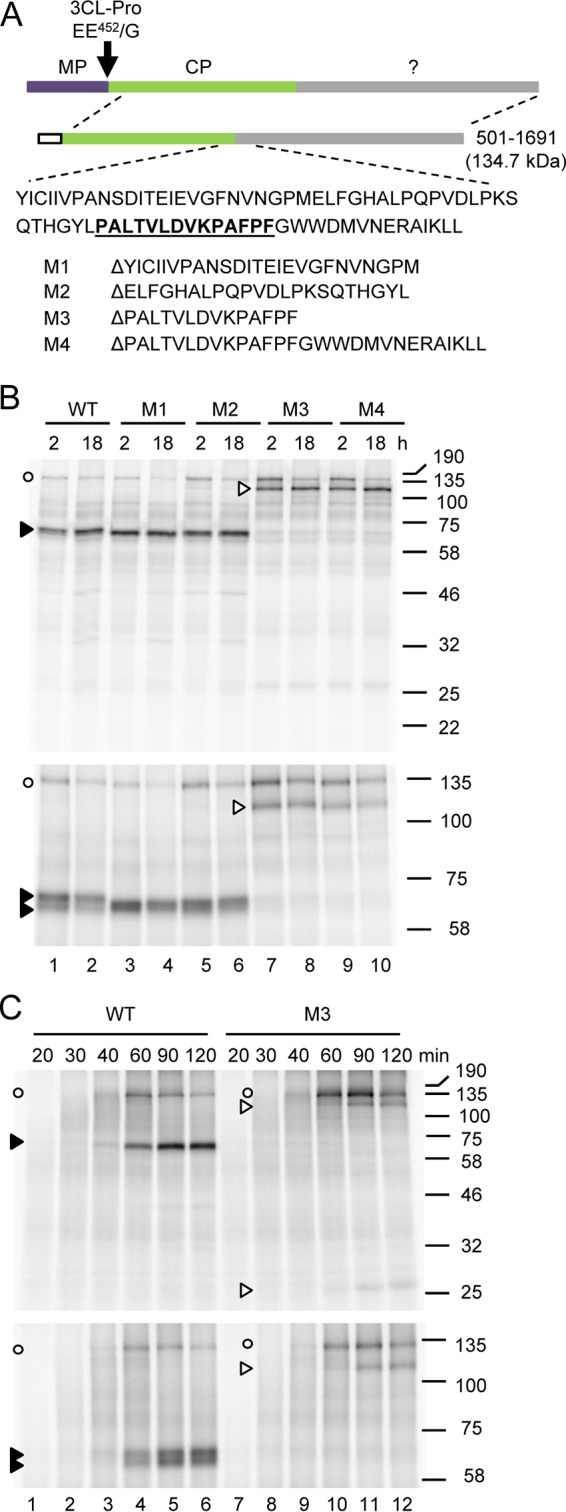
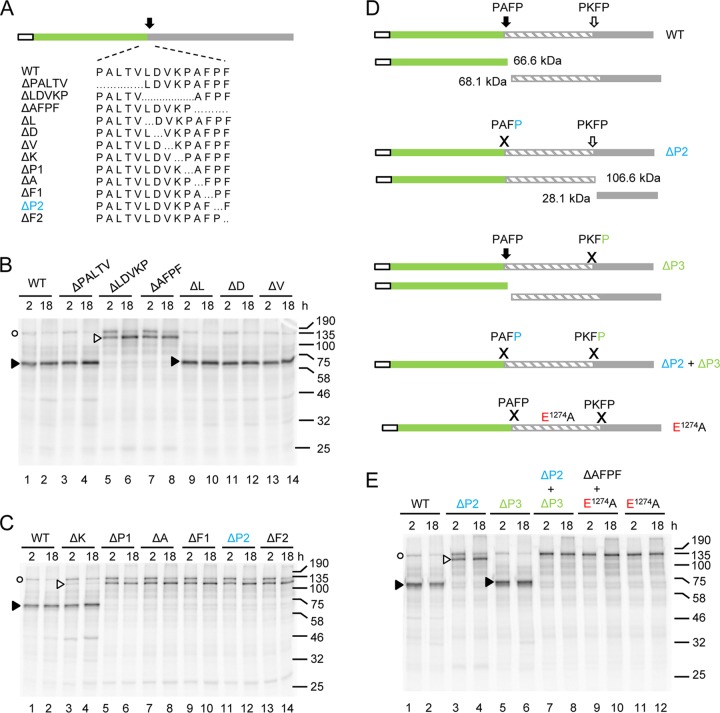
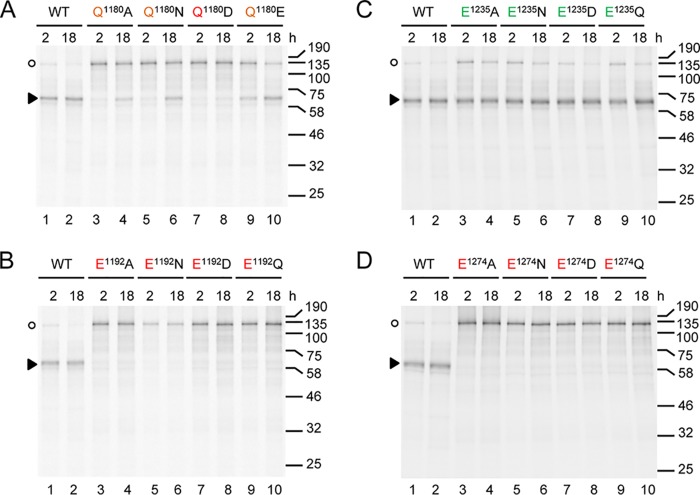
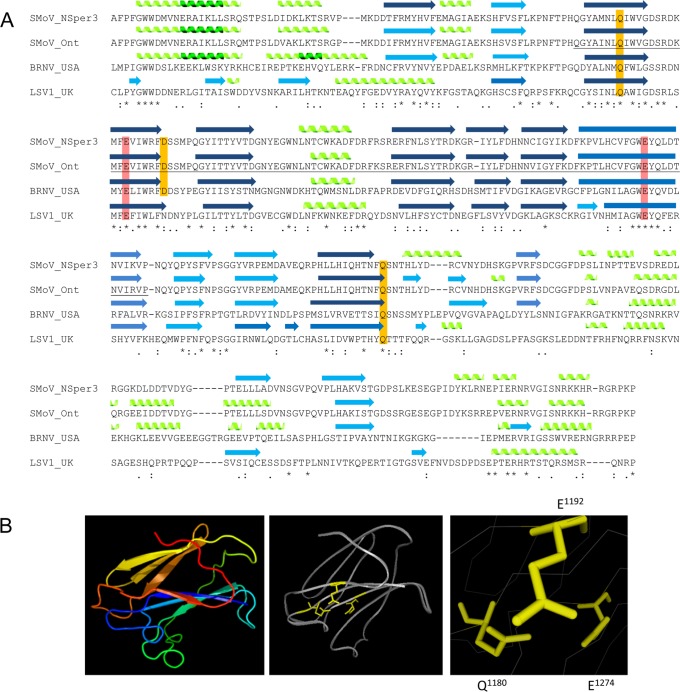
Strawberry mottle virus (SMoV) belongs to the family Secoviridae (order Picornavirales) and has a bipartite genome with each RNA encoding one polyprotein. All characterized secovirids encode a single protease related to the picornavirus 3C protease. The SMoV 3C-like protease was previously shown to cut the RNA2 polyprotein (P2) at a single site between the predicted movement protein and coat protein (CP) domains. However, the SMoV P2 polyprotein includes an extended C-terminal region with a coding capacity of up to 70 kDa downstream of the presumed CP domain, an unusual characteristic for this family. In this study, we identified a novel cleavage event at a P↓AFP sequence immediately downstream of the CP domain. Following deletion of the PAFP sequence, the polyprotein was processed at or near a related PKFP sequence 40 kDa further downstream, defining two protein domains in the C-terminal region of the P2 polyprotein. Both processing events were dependent on a novel protease domain located between the two cleavage sites. Mutagenesis of amino acids that are conserved among isolates of SMoV and of the related Black raspberry necrosis virus did not identify essential cysteine, serine, or histidine residues, suggesting that the RNA2-encoded SMoV protease is not related to serine or cysteine proteases of other picorna-like viruses. Rather, two highly conserved glutamic acid residues spaced by 82 residues were found to be strictly required for protease activity. We conclude that the processing of SMoV polyproteins requires two viral proteases, the RNA1-encoded 3C-like protease and a novel glutamic protease encoded by RNA2.IMPORTANCE Many viruses encode proteases to release mature proteins and intermediate polyproteins from viral polyproteins. Polyprotein processing allows regulation of the accumulation and activity of viral proteins. Many viral proteases also cleave host factors to facilitate virus infection. Thus, viral proteases are key virulence factors. To date, viruses with a positive-strand RNA genome are only known to encode cysteine or serine proteases, most of which are related to the cellular papain, trypsin, or chymotrypsin proteases. Here, we characterize the first glutamic protease encoded by a plant virus or by a positive-strand RNA virus. The novel glutamic protease is unique to a few members of the family Secoviridae, suggesting that it is a recent acquisition in the evolution of this family. The protease does not resemble known cellular proteases. Rather, it is predicted to share structural similarities with a family of fungal and bacterial glutamic proteases that adopt a lectin fold.
Keywords: Picornavirales; Secoviridae; plant viruses; proteases.
© Crown copyright 2019.
Figures






Similar articles
-
Expanding Repertoire of Plant Positive-Strand RNA Virus Proteases.Viruses. 2019 Jan 15;11(1):66. doi: 10.3390/v11010066. Viruses. 2019. PMID: 30650571 Free PMC article. Review.
-
Identification of Cleavage Sites Recognized by the 3C-Like Cysteine Protease within the Two Polyproteins of Strawberry Mottle Virus.Front Microbiol. 2017 Apr 27;8:745. doi: 10.3389/fmicb.2017.00745. eCollection 2017. Front Microbiol. 2017. PMID: 28496438 Free PMC article.
-
Re-examination of nepovirus polyprotein cleavage sites highlights the diverse specificities and evolutionary relationships of nepovirus 3C-like proteases.Arch Virol. 2022 Dec;167(12):2529-2543. doi: 10.1007/s00705-022-05564-x. Epub 2022 Aug 30. Arch Virol. 2022. PMID: 36042138 Free PMC article.
-
Identification of the cleavage sites of the RNA2-encoded polyproteins for two members of the genus Torradovirus by N-terminal sequencing of the virion capsid proteins.Virology. 2016 Nov;498:109-115. doi: 10.1016/j.virol.2016.08.014. Epub 2016 Aug 25. Virology. 2016. PMID: 27567259
-
Picornavirus 3C Proteins Intervene in Host Cell Processes through Proteolysis and Interactions with RNA.Viruses. 2023 Dec 12;15(12):2413. doi: 10.3390/v15122413. Viruses. 2023. PMID: 38140654 Free PMC article. Review.
Cited by
-
Identification of Silencing Suppressor Protein Encoded by Strawberry Mottle Virus.Front Plant Sci. 2022 May 31;13:786489. doi: 10.3389/fpls.2022.786489. eCollection 2022. Front Plant Sci. 2022. PMID: 35712581 Free PMC article.
-
Expanding Repertoire of Plant Positive-Strand RNA Virus Proteases.Viruses. 2019 Jan 15;11(1):66. doi: 10.3390/v11010066. Viruses. 2019. PMID: 30650571 Free PMC article. Review.
-
Evolution of a novel engineered tripartite viral genome of a torradovirus.Virus Evol. 2024 Nov 20;10(1):0. doi: 10.1093/ve/veae098. eCollection 2024. Virus Evol. 2024. PMID: 39678354 Free PMC article.
-
FaNDUFB9 Attenuates Strawberry Mottle Virus Infection by Inhibiting the Activity of the Viral Gene Silencing Suppressor, Pro2Glu.Mol Plant Pathol. 2025 Mar;26(3):e70061. doi: 10.1111/mpp.70061. Mol Plant Pathol. 2025. PMID: 40059087 Free PMC article.
-
Post-Proline Cleaving Enzymes (PPCEs): Classification, Structure, Molecular Properties, and Applications.Plants (Basel). 2022 May 18;11(10):1330. doi: 10.3390/plants11101330. Plants (Basel). 2022. PMID: 35631755 Free PMC article. Review.
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Miscellaneous
