

Hierarchical structure guides rapid linguistic predictions during naturalistic listening
- PMID: 30650078
- PMCID: PMC6334990
- DOI: 10.1371/journal.pone.0207741
Hierarchical structure guides rapid linguistic predictions during naturalistic listening
Abstract
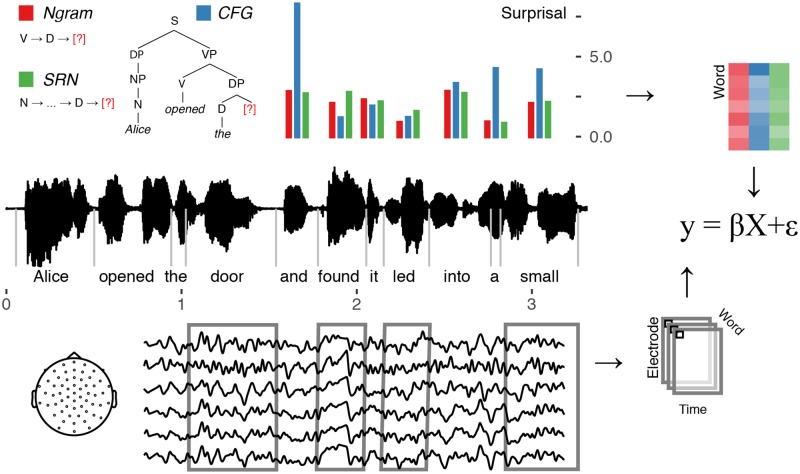
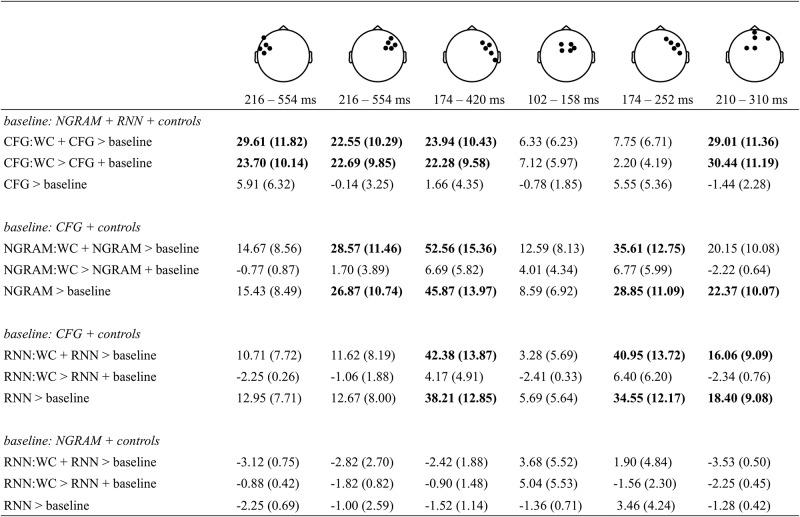
The grammar, or syntax, of human language is typically understood in terms of abstract hierarchical structures. However, theories of language processing that emphasize sequential information, not hierarchy, successfully model diverse phenomena. Recent work probing brain signals has shown mixed evidence for hierarchical information in some tasks. We ask whether sequential or hierarchical information guides the expectations that a human listener forms about a word's part-of-speech when simply listening to every-day language. We compare the predictions of three computational models against electroencephalography signals recorded from human participants who listen passively to an audiobook story. We find that predictions based on hierarchical structure correlate with the human brain response above-and-beyond predictions based only on sequential information. This establishes a link between hierarchical linguistic structure and neural signals that generalizes across the range of syntactic structures found in every-day language.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures


Similar articles
-
Localizing syntactic predictions using recurrent neural network grammars.Neuropsychologia. 2020 Sep;146:107479. doi: 10.1016/j.neuropsychologia.2020.107479. Epub 2020 May 16. Neuropsychologia. 2020. PMID: 32428530
-
Modeling Structure-Building in the Brain With CCG Parsing and Large Language Models.Cogn Sci. 2023 Jul;47(7):e13312. doi: 10.1111/cogs.13312. Cogn Sci. 2023. PMID: 37417470
-
Phase synchronization varies systematically with linguistic structure composition.Philos Trans R Soc Lond B Biol Sci. 2020 Feb 3;375(1791):20190305. doi: 10.1098/rstb.2019.0305. Epub 2019 Dec 16. Philos Trans R Soc Lond B Biol Sci. 2020. PMID: 31840584 Free PMC article.
-
Songs to syntax: the linguistics of birdsong.Trends Cogn Sci. 2011 Mar;15(3):113-21. doi: 10.1016/j.tics.2011.01.002. Trends Cogn Sci. 2011. PMID: 21296608 Review.
-
How hierarchical is language use?Proc Biol Sci. 2012 Nov 22;279(1747):4522-31. doi: 10.1098/rspb.2012.1741. Epub 2012 Sep 12. Proc Biol Sci. 2012. PMID: 22977157 Free PMC article. Review.
Cited by
-
Phonological acquisition depends on the timing of speech sounds: Deconvolution EEG modeling across the first five years.Sci Adv. 2023 Nov 3;9(44):eadh2560. doi: 10.1126/sciadv.adh2560. Epub 2023 Nov 1. Sci Adv. 2023. PMID: 37910625 Free PMC article.
-
A hierarchy of linguistic predictions during natural language comprehension.Proc Natl Acad Sci U S A. 2022 Aug 9;119(32):e2201968119. doi: 10.1073/pnas.2201968119. Epub 2022 Aug 3. Proc Natl Acad Sci U S A. 2022. PMID: 35921434 Free PMC article.
-
What's Surprising About Surprisal.Comput Brain Behav. 2025;8(2):233-248. doi: 10.1007/s42113-025-00237-9. Epub 2025 Feb 21. Comput Brain Behav. 2025. PMID: 40453151 Free PMC article.
-
Let them eat ceke: An electrophysiological study of form-based prediction in rich naturalistic contexts.J Exp Psychol Gen. 2025 Mar;154(3):711-738. doi: 10.1037/xge0001677. Epub 2024 Dec 16. J Exp Psychol Gen. 2025. PMID: 39680005
-
Understanding words in context: A naturalistic EEG study of children's lexical processing.J Mem Lang. 2024 Aug;137:104512. doi: 10.1016/j.jml.2024.104512. Epub 2024 Mar 8. J Mem Lang. 2024. PMID: 38855737 Free PMC article.
References
-
- Frank SL, Christiansen MH. Hierarchical and sequential processing of language. Language, Cognition and Neuroscience. 2018; p. 1–6.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
