

Stratification of amyotrophic lateral sclerosis patients: a crowdsourcing approach
- PMID: 30679616
- PMCID: PMC6345935
- DOI: 10.1038/s41598-018-36873-4
Stratification of amyotrophic lateral sclerosis patients: a crowdsourcing approach
Abstract
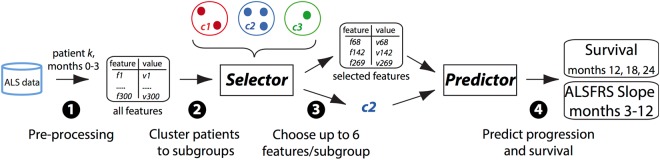
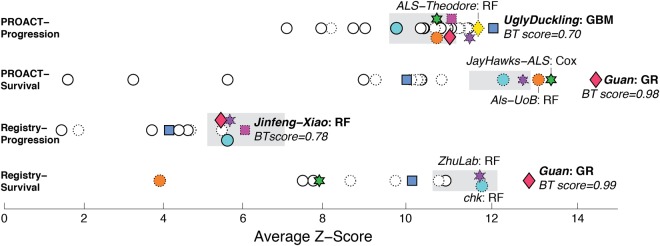
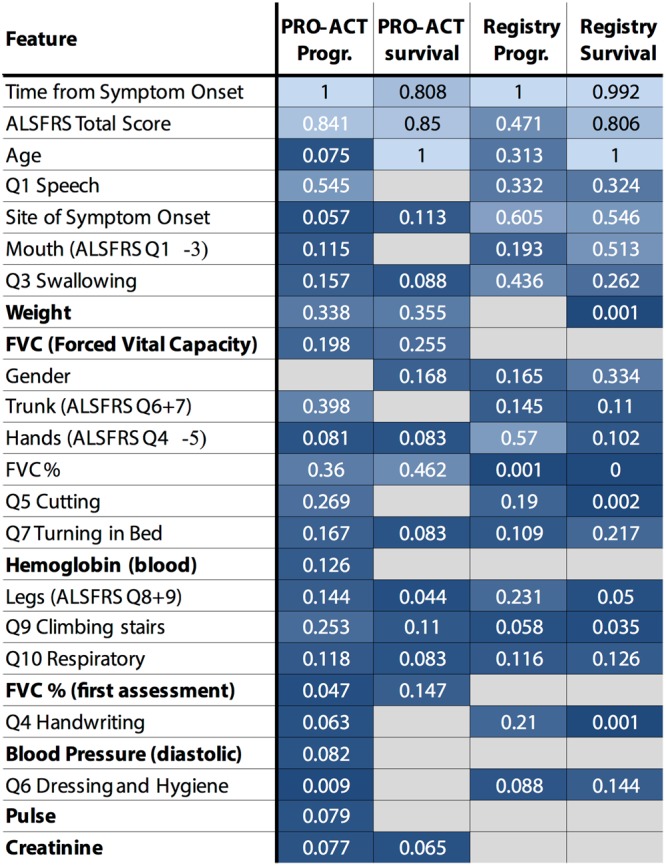
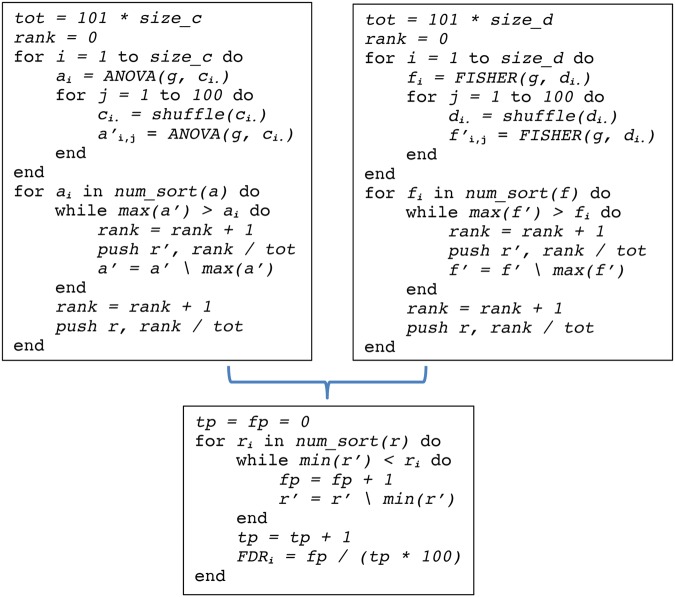
Amyotrophic lateral sclerosis (ALS) is a fatal neurodegenerative disease where substantial heterogeneity in clinical presentation urgently requires a better stratification of patients for the development of drug trials and clinical care. In this study we explored stratification through a crowdsourcing approach, the DREAM Prize4Life ALS Stratification Challenge. Using data from >10,000 patients from ALS clinical trials and 1479 patients from community-based patient registers, more than 30 teams developed new approaches for machine learning and clustering, outperforming the best current predictions of disease outcome. We propose a new method to integrate and analyze patient clusters across methods, showing a clear pattern of consistent and clinically relevant sub-groups of patients that also enabled the reliable classification of new patients. Our analyses reveal novel insights in ALS and describe for the first time the potential of a crowdsourcing to uncover hidden patient sub-populations, and to accelerate disease understanding and therapeutic development.
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Miller, R. G., Mitchell, J. D., Lyon, M. & Moore, D. H. Riluzole for amyotrophic lateralsclerosis (ALS)/motor neuron disease (MND). Cochrane Database Syst Rev. CD001447 (2002). - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
