

Towards reconstructing intelligible speech from the human auditory cortex
- PMID: 30696881
- PMCID: PMC6351601
- DOI: 10.1038/s41598-018-37359-z
Towards reconstructing intelligible speech from the human auditory cortex
Abstract
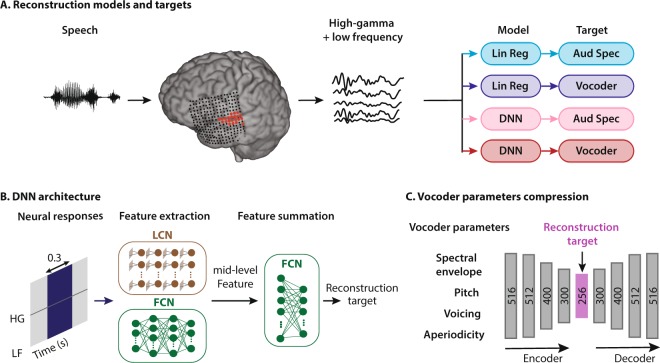
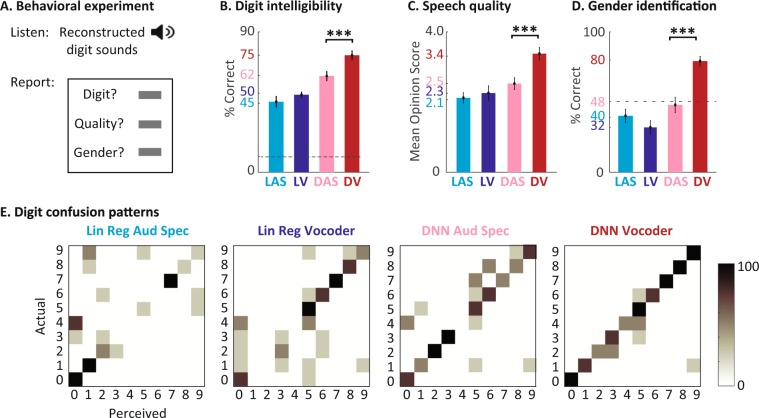
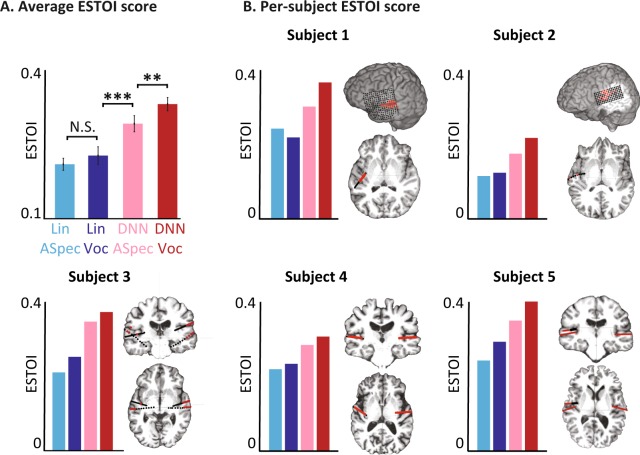
Auditory stimulus reconstruction is a technique that finds the best approximation of the acoustic stimulus from the population of evoked neural activity. Reconstructing speech from the human auditory cortex creates the possibility of a speech neuroprosthetic to establish a direct communication with the brain and has been shown to be possible in both overt and covert conditions. However, the low quality of the reconstructed speech has severely limited the utility of this method for brain-computer interface (BCI) applications. To advance the state-of-the-art in speech neuroprosthesis, we combined the recent advances in deep learning with the latest innovations in speech synthesis technologies to reconstruct closed-set intelligible speech from the human auditory cortex. We investigated the dependence of reconstruction accuracy on linear and nonlinear (deep neural network) regression methods and the acoustic representation that is used as the target of reconstruction, including auditory spectrogram and speech synthesis parameters. In addition, we compared the reconstruction accuracy from low and high neural frequency ranges. Our results show that a deep neural network model that directly estimates the parameters of a speech synthesizer from all neural frequencies achieves the highest subjective and objective scores on a digit recognition task, improving the intelligibility by 65% over the baseline method which used linear regression to reconstruct the auditory spectrogram. These results demonstrate the efficacy of deep learning and speech synthesis algorithms for designing the next generation of speech BCI systems, which not only can restore communications for paralyzed patients but also have the potential to transform human-computer interaction technologies.
Conflict of interest statement
The authors declare no competing interests.
Figures


References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
