

FLOating-Window Projective Separator (FloWPS): A Data Trimming Tool for Support Vector Machines (SVM) to Improve Robustness of the Classifier
- PMID: 30697229
- PMCID: PMC6341065
- DOI: 10.3389/fgene.2018.00717
FLOating-Window Projective Separator (FloWPS): A Data Trimming Tool for Support Vector Machines (SVM) to Improve Robustness of the Classifier
Abstract
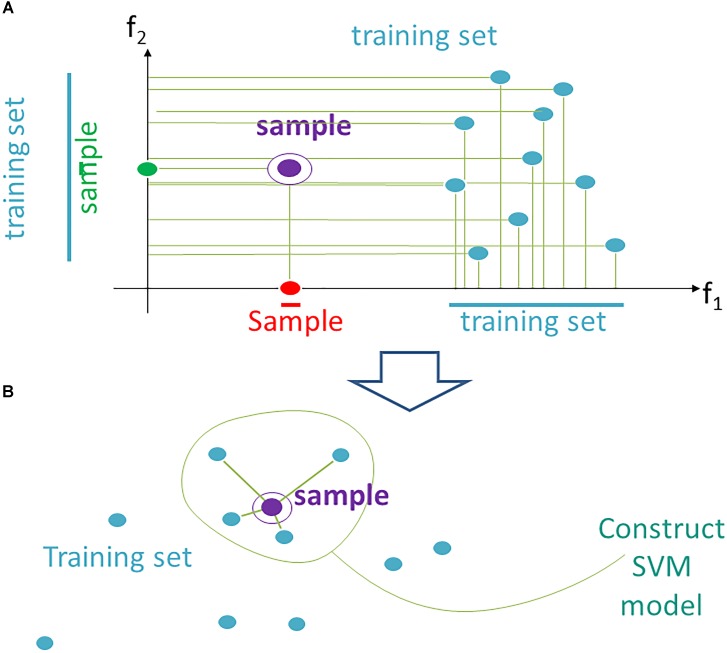
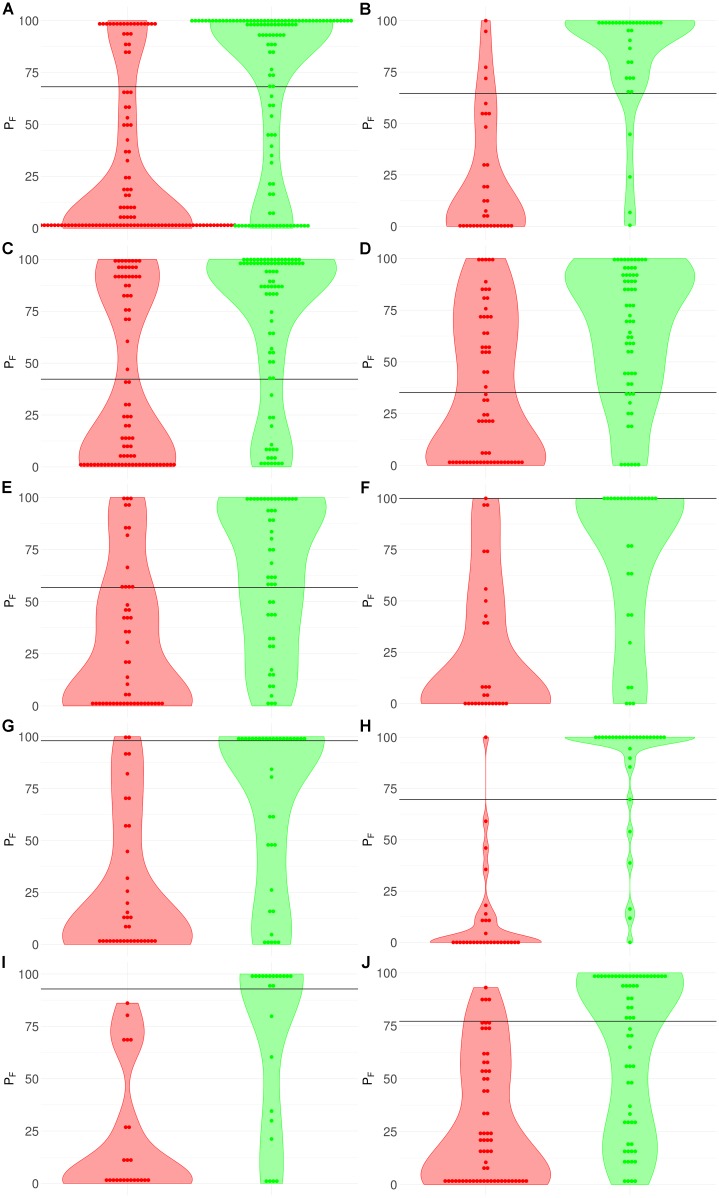
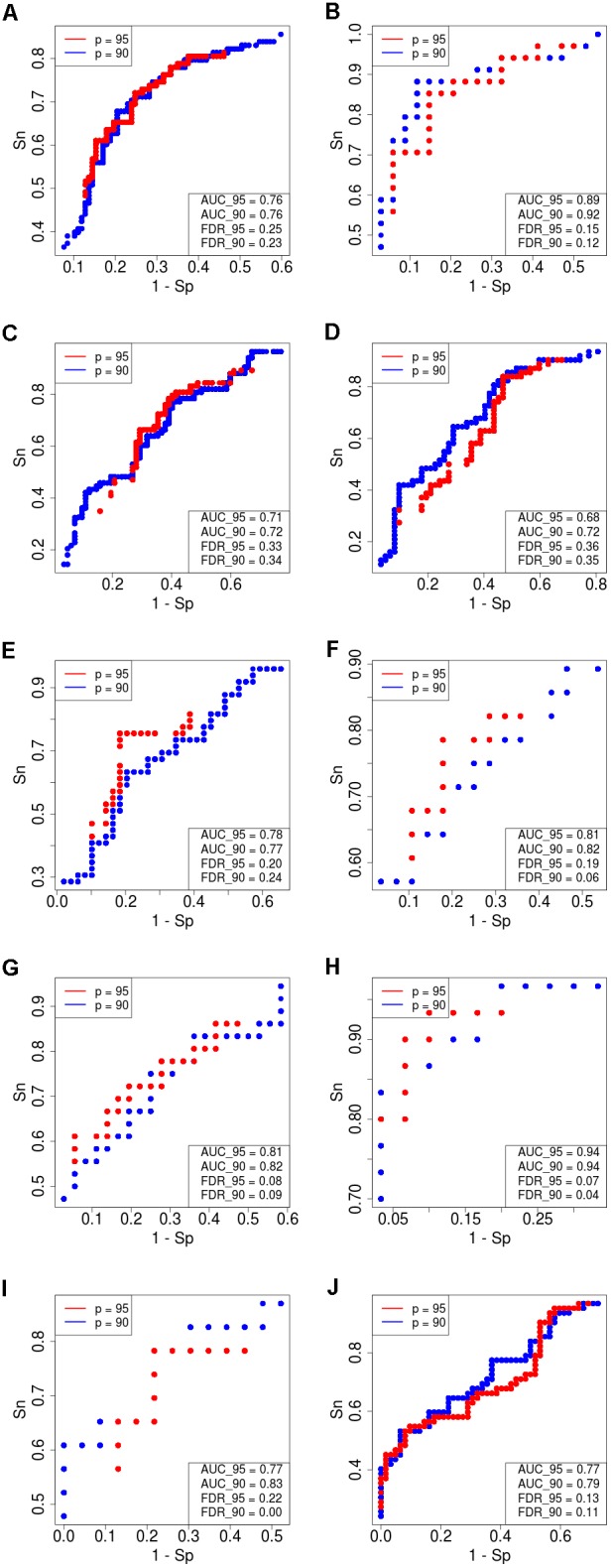
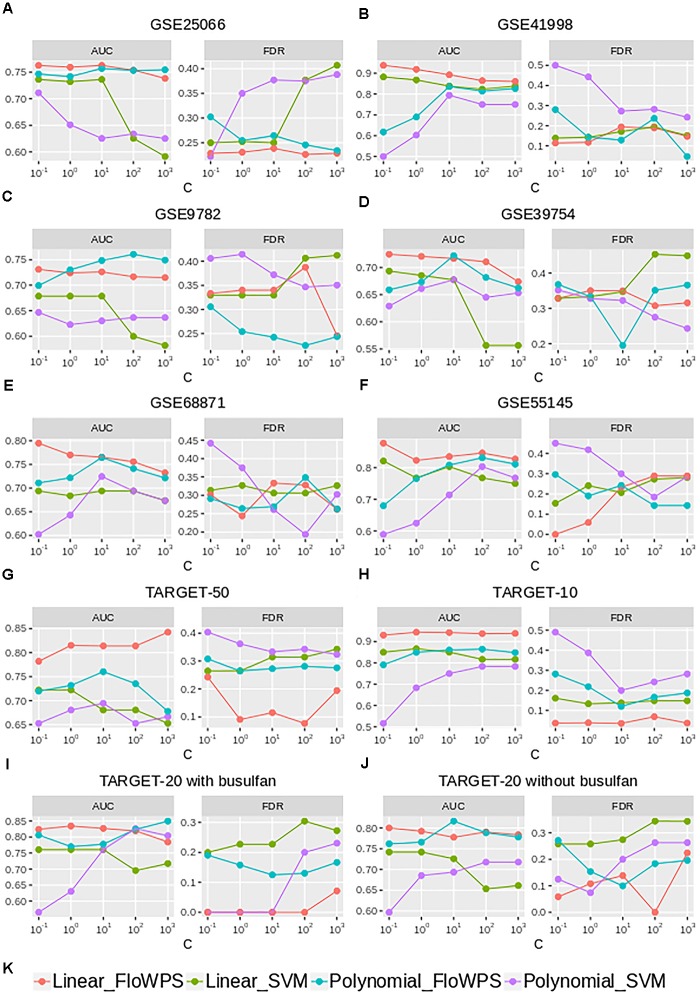
Here, we propose a heuristic technique of data trimming for SVM termed FLOating Window Projective Separator (FloWPS), tailored for personalized predictions based on molecular data. This procedure can operate with high throughput genetic datasets like gene expression or mutation profiles. Its application prevents SVM from extrapolation by excluding non-informative features. FloWPS requires training on the data for the individuals with known clinical outcomes to create a clinically relevant classifier. The genetic profiles linked with the outcomes are broken as usual into the training and validation datasets. The unique property of FloWPS is that irrelevant features in validation dataset that don't have significant number of neighboring hits in the training dataset are removed from further analyses. Next, similarly to the k nearest neighbors (kNN) method, for each point of a validation dataset, FloWPS takes into account only the proximal points of the training dataset. Thus, for every point of a validation dataset, the training dataset is adjusted to form a floating window. FloWPS performance was tested on ten gene expression datasets for 992 cancer patients either responding or not on the different types of chemotherapy. We experimentally confirmed by leave-one-out cross-validation that FloWPS enables to significantly increase quality of a classifier built based on the classical SVM in most of the applications, particularly for polynomial kernels.
Keywords: bioinformatics; gene expression; machine learning; oncology; personalized medicine; support vector machines.
Figures


References
-
- Ahmed F., Kumar M., Raghava G. P. S. (2009b). Prediction of polyadenylation signals in human DNA sequences using nucleotide frequencies. In Silico Biol. 9 135–148. - PubMed
-
- Altman N. S. (1992). An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 46 175–185. 10.1080/00031305.1992.10475879 - DOI
LinkOut - more resources
Full Text Sources