

A scalable discrete-time survival model for neural networks
- PMID: 30701130
- PMCID: PMC6348952
- DOI: 10.7717/peerj.6257
A scalable discrete-time survival model for neural networks
Abstract
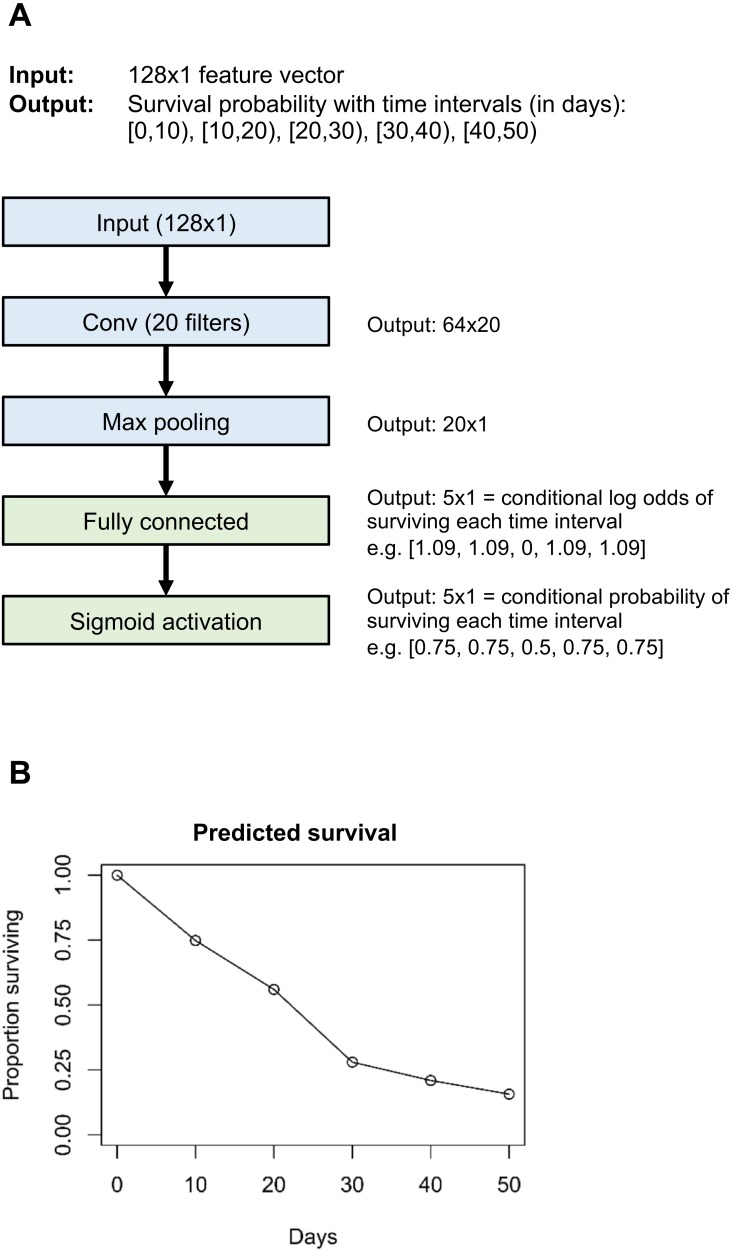
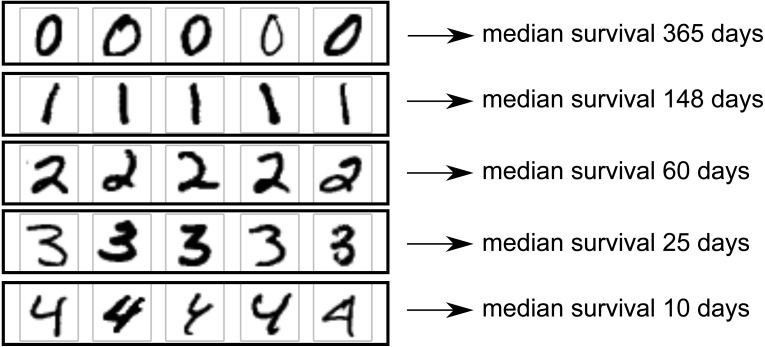
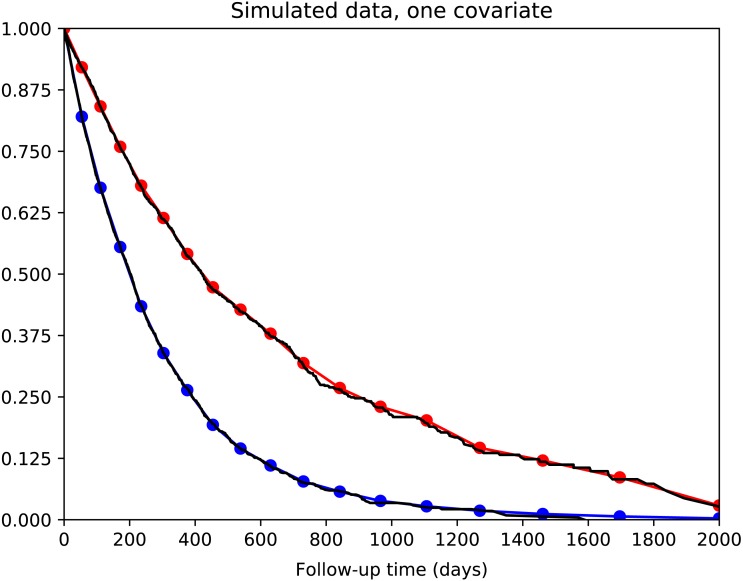
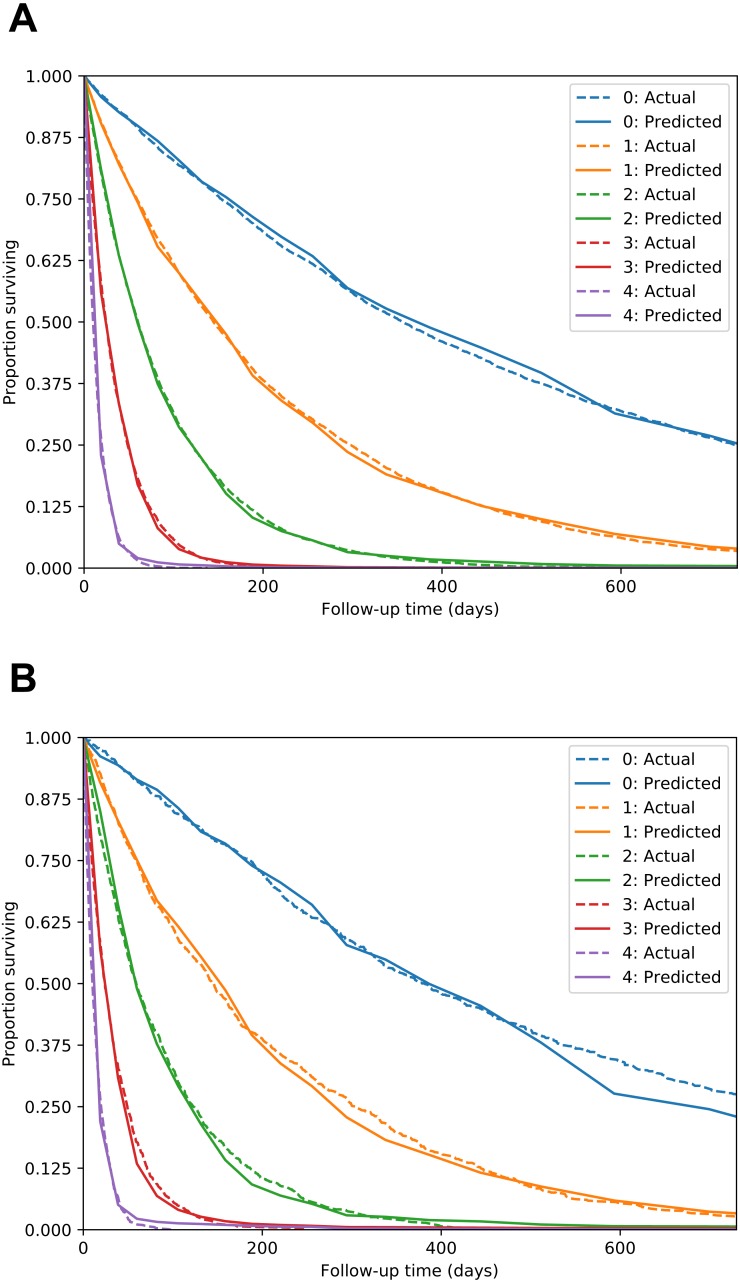
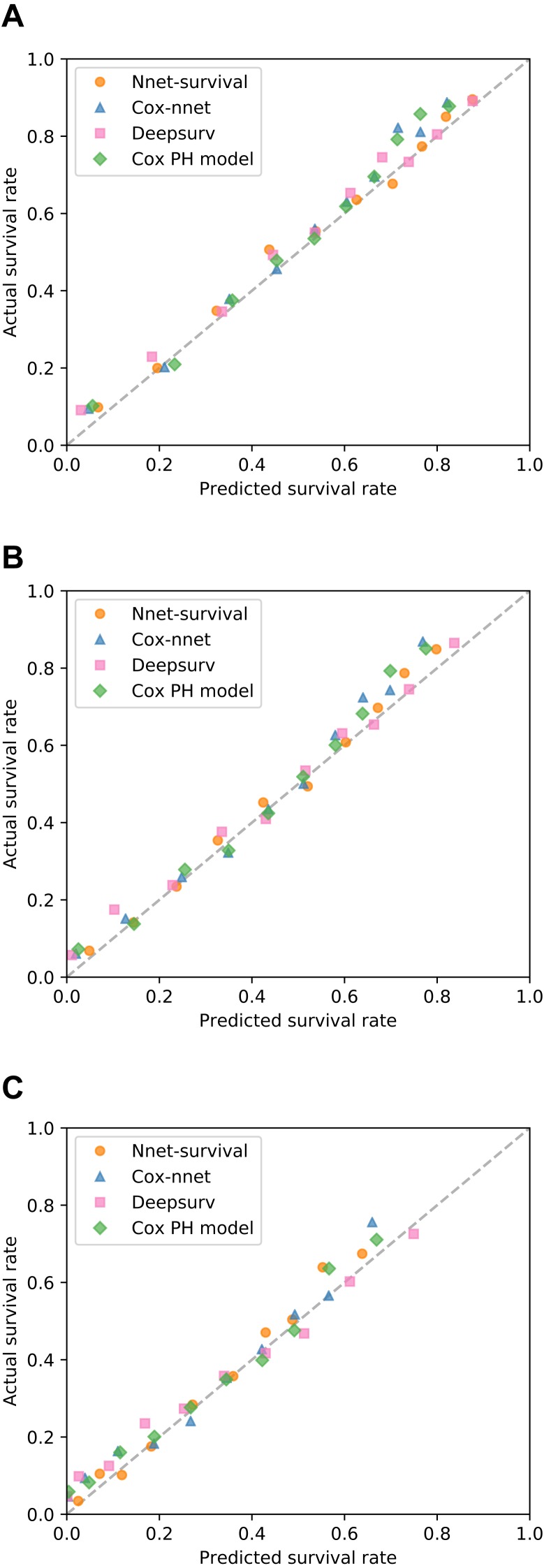
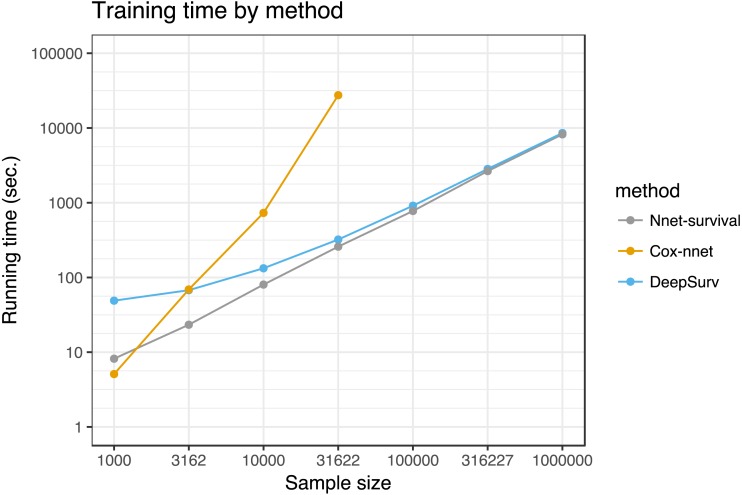
There is currently great interest in applying neural networks to prediction tasks in medicine. It is important for predictive models to be able to use survival data, where each patient has a known follow-up time and event/censoring indicator. This avoids information loss when training the model and enables generation of predicted survival curves. In this paper, we describe a discrete-time survival model that is designed to be used with neural networks, which we refer to as Nnet-survival. The model is trained with the maximum likelihood method using mini-batch stochastic gradient descent (SGD). The use of SGD enables rapid convergence and application to large datasets that do not fit in memory. The model is flexible, so that the baseline hazard rate and the effect of the input data on hazard probability can vary with follow-up time. It has been implemented in the Keras deep learning framework, and source code for the model and several examples is available online. We demonstrate the performance of the model on both simulated and real data and compare it to existing models Cox-nnet and Deepsurv.
Keywords: Machine learning; Neural networks; Survival analysis.
Conflict of interest statement
The authors declare there are no competing interests.
Figures
References
-
- Bottou L. Stochastic gradient learning in neural networks. Proceedings of Neuro-Nimes. 1991;91(8):687–706.
-
- Breslow N. Covariance analysis of censored survival data. Biometrics. 1974;30:89–99. - PubMed
-
- Breslow N, Crowley J. A large sample study of the life table and product limit estimates under random censorship. The Annals of Statistics. 1974;2(3):437–453. doi: 10.1214/aos/1176342705. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
