

A Random Forests Quantile Classifier for Class Imbalanced Data
- PMID: 30765897
- PMCID: PMC6370055
- DOI: 10.1016/j.patcog.2019.01.036
A Random Forests Quantile Classifier for Class Imbalanced Data
Abstract
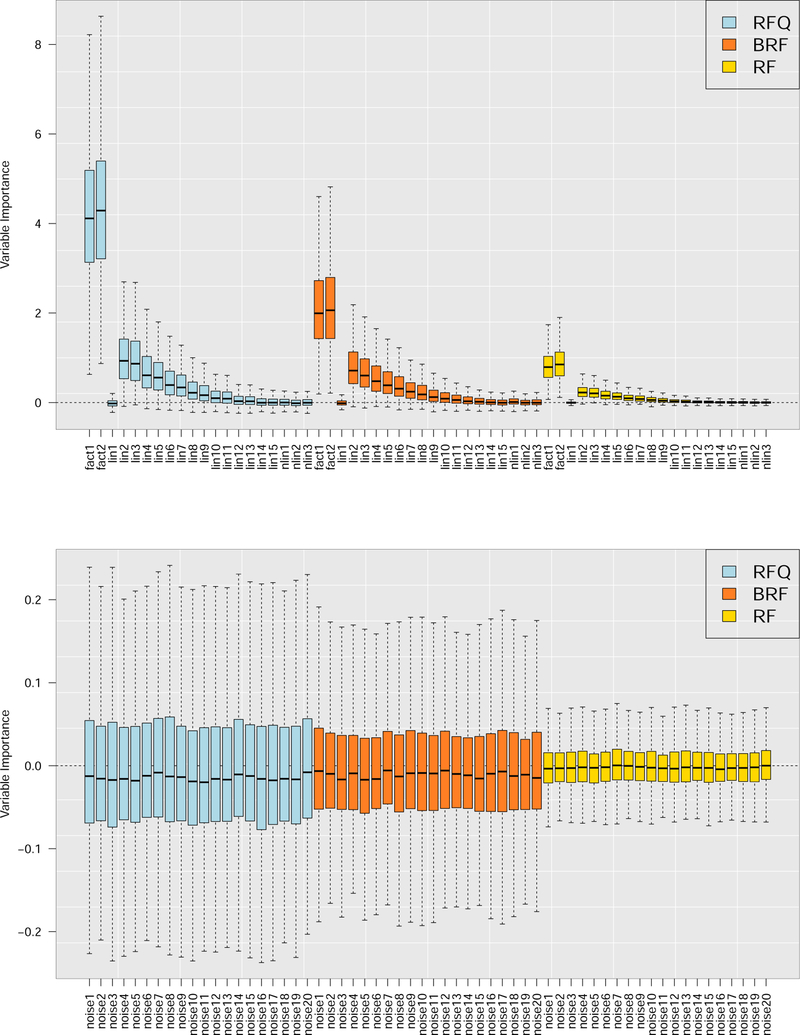
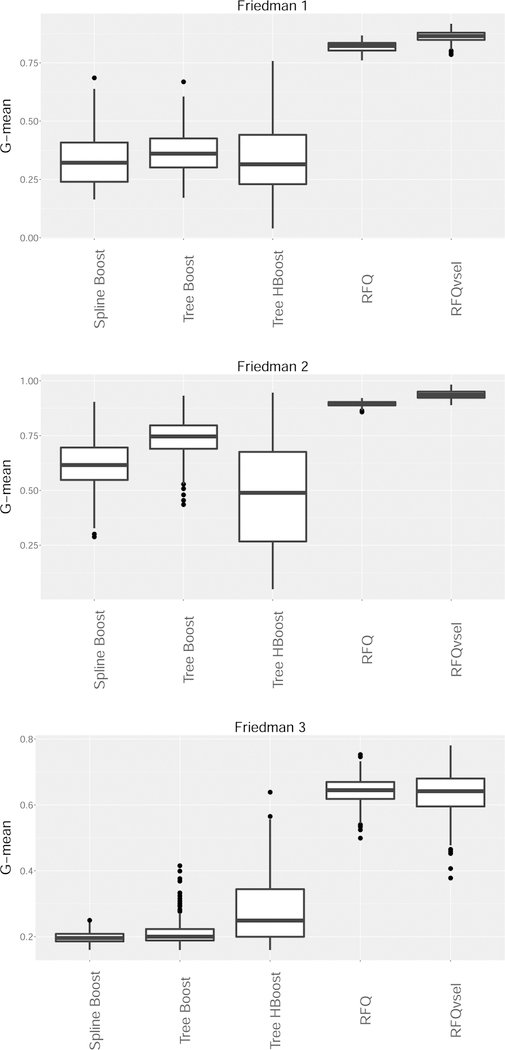
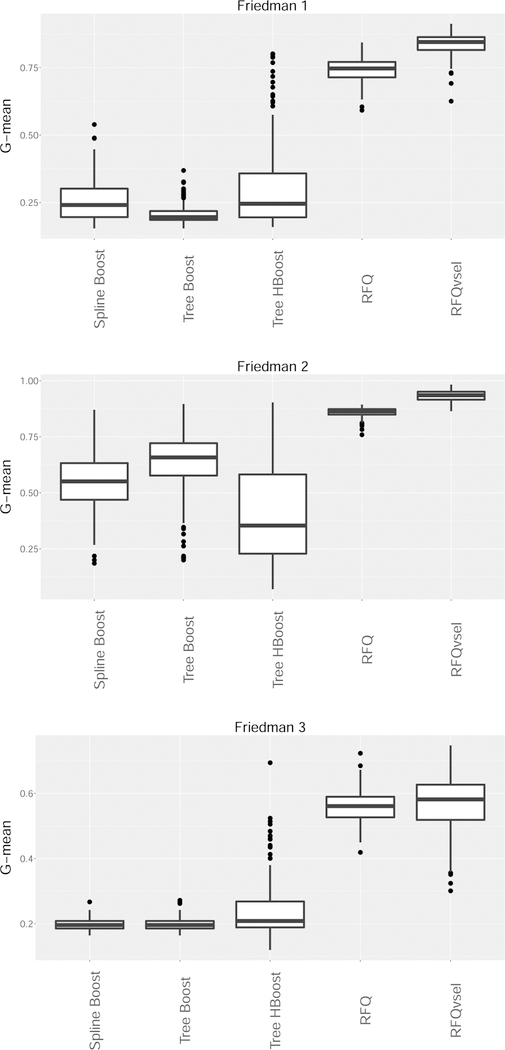
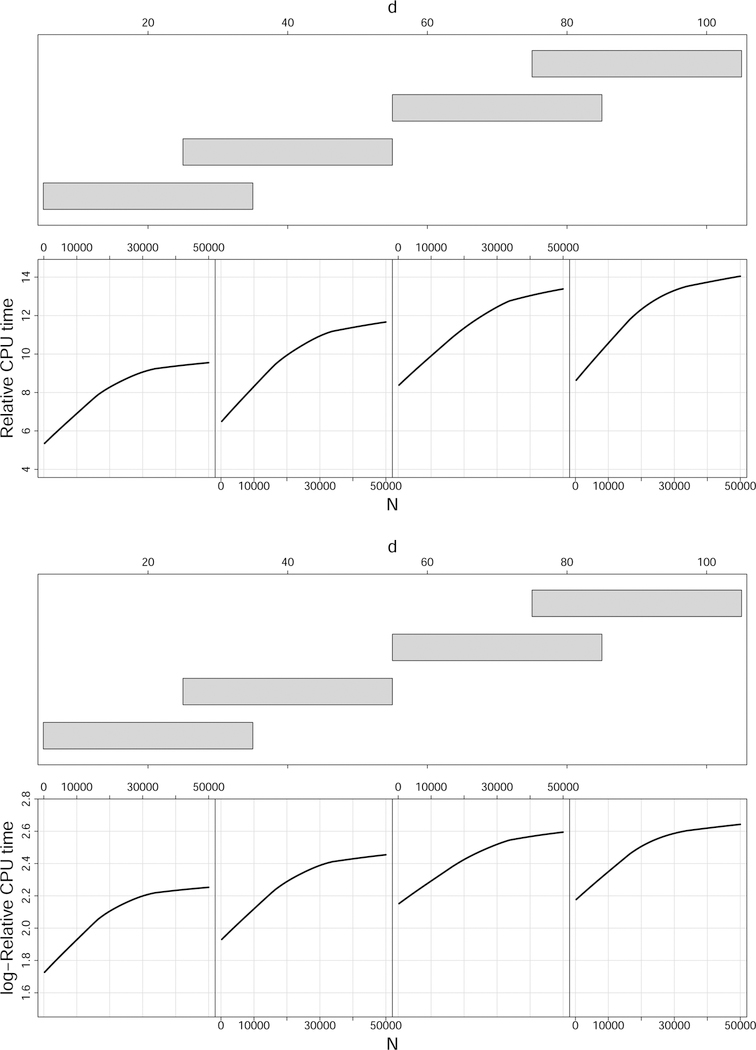
Extending previous work on quantile classifiers (q-classifiers) we propose the q*-classifier for the class imbalance problem. The classifier assigns a sample to the minority class if the minority class conditional probability exceeds 0 < q* < 1, where q* equals the unconditional probability of observing a minority class sample. The motivation for q*-classification stems from a density-based approach and leads to the useful property that the q*-classifier maximizes the sum of the true positive and true negative rates. Moreover, because the procedure can be equivalently expressed as a cost-weighted Bayes classifier, it also minimizes weighted risk. Because of this dual optimization, the q*-classifier can achieve near zero risk in imbalance problems, while simultaneously optimizing true positive and true negative rates. We use random forests to apply q*-classification. This new method which we call RFQ is shown to outperform or is competitive with existing techniques with respect to tt-mean performance and variable selection. Extensions to the multiclass imbalanced setting are also considered.
Keywords: Class Imbalance; Minority Class; Random Forests; Response-based Sampling; Weighted Bayes Classifier.
Conflict of interest statement
Conflict of interest None declared.
Figures
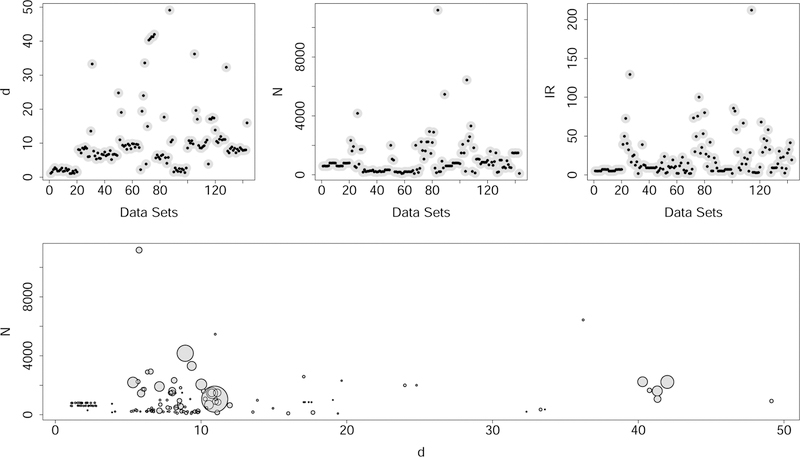
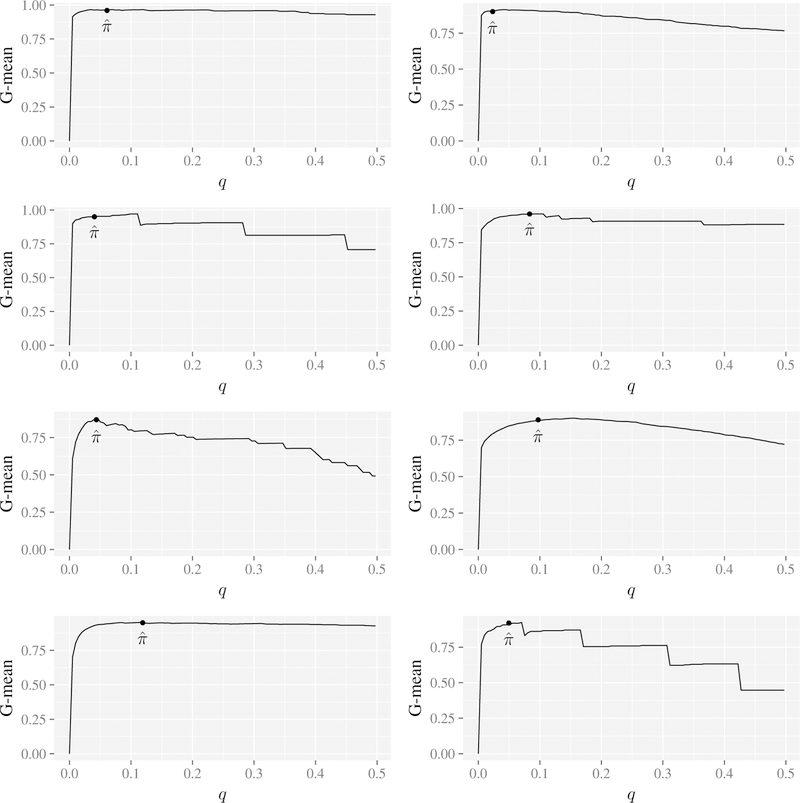
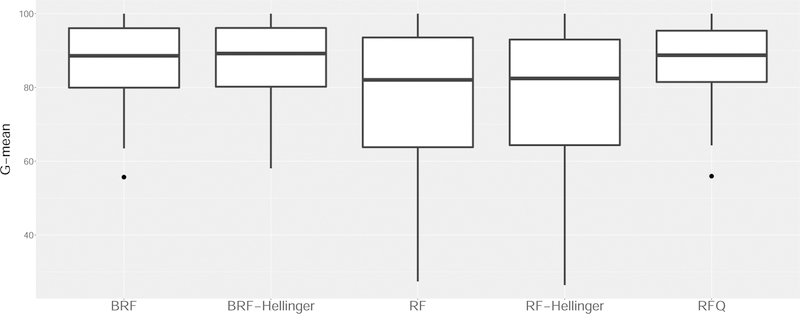
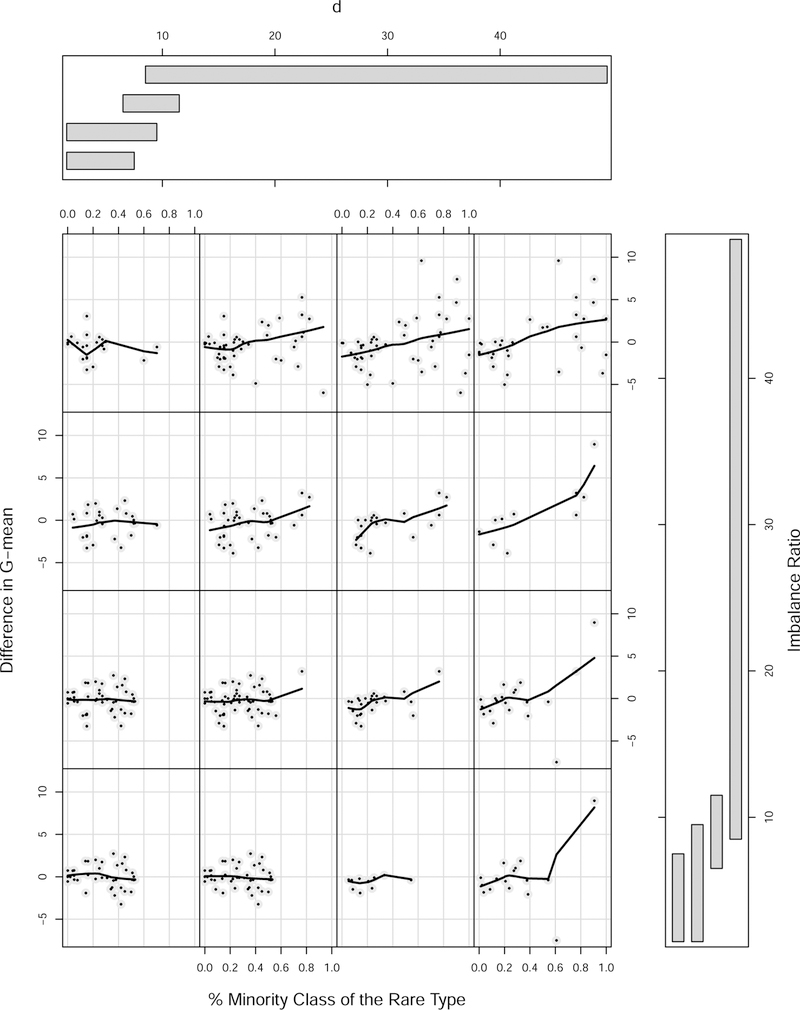
References
-
- Breiman L, Random forests, Machine Learning 45 (1) (2001) 5–32.
-
- Verikas A, Gelzinis A, Bacauskiene M, Mining data with random forests: A survey and results of new tests, Pattern Recognition 44 (2) (2011) 330–349.
-
- Biau G, Scornet E, A random forest guided tour, Test 25 (2) (2016) 197–227.
-
- Breiman L, Manual on Setting up, Using, and Understanding Random Forests V3 1, 2002.
-
- Ishwaran H, Variable importance in binary regression trees and forests, Electronic Journal of Statis-tics 1 (2007) 519–537.
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous