

Assessing the practical differences between model selection methods in inferences about choice response time tasks
- PMID: 30783896
- PMCID: PMC6710222
- DOI: 10.3758/s13423-018-01563-9
Assessing the practical differences between model selection methods in inferences about choice response time tasks
Abstract
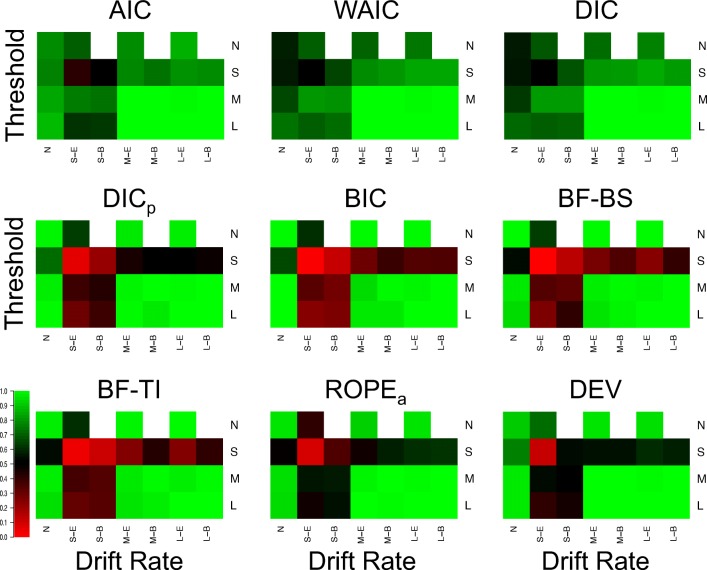
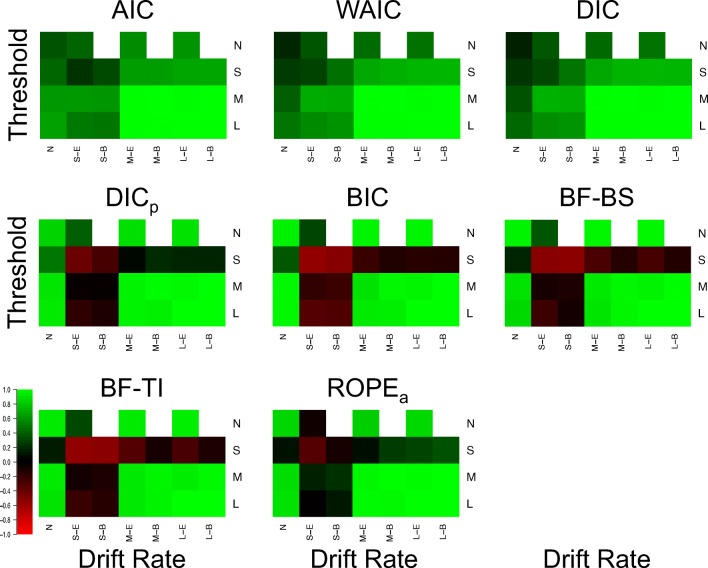
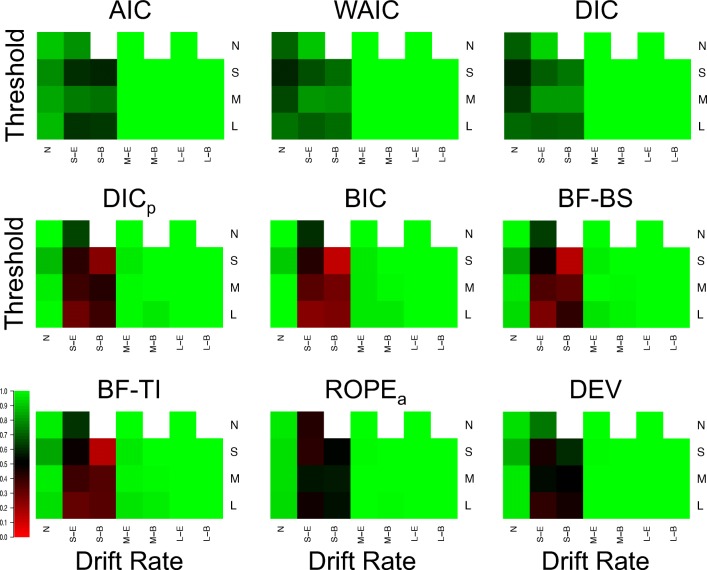
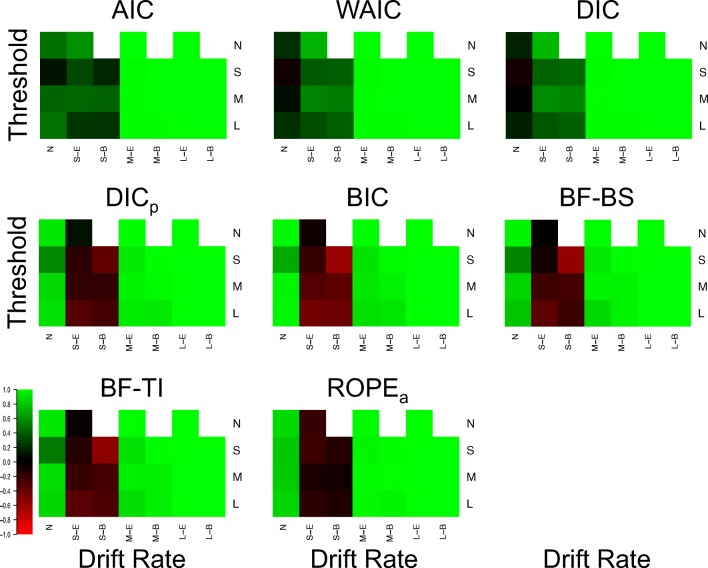
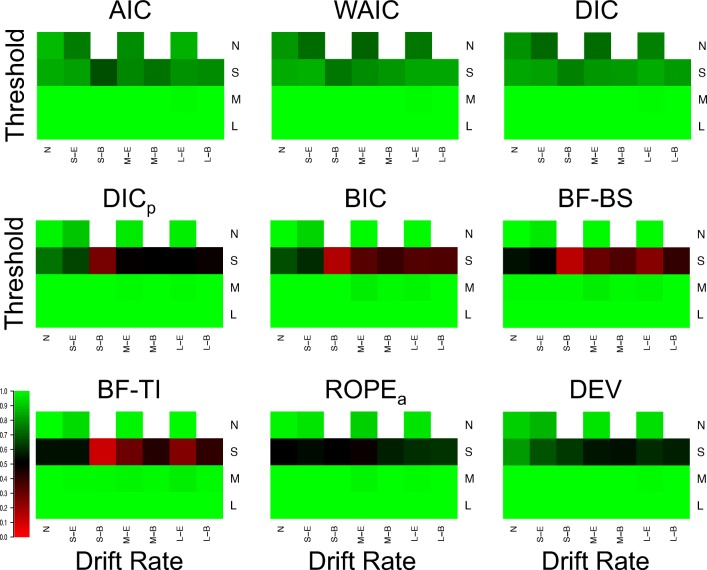
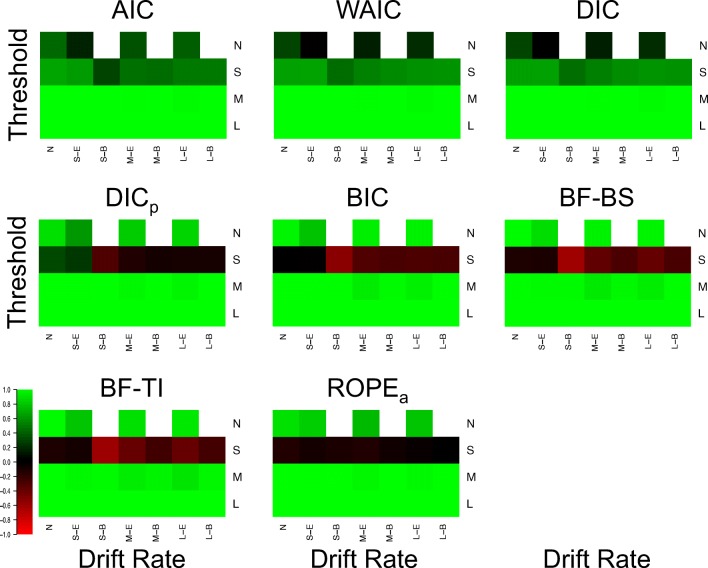
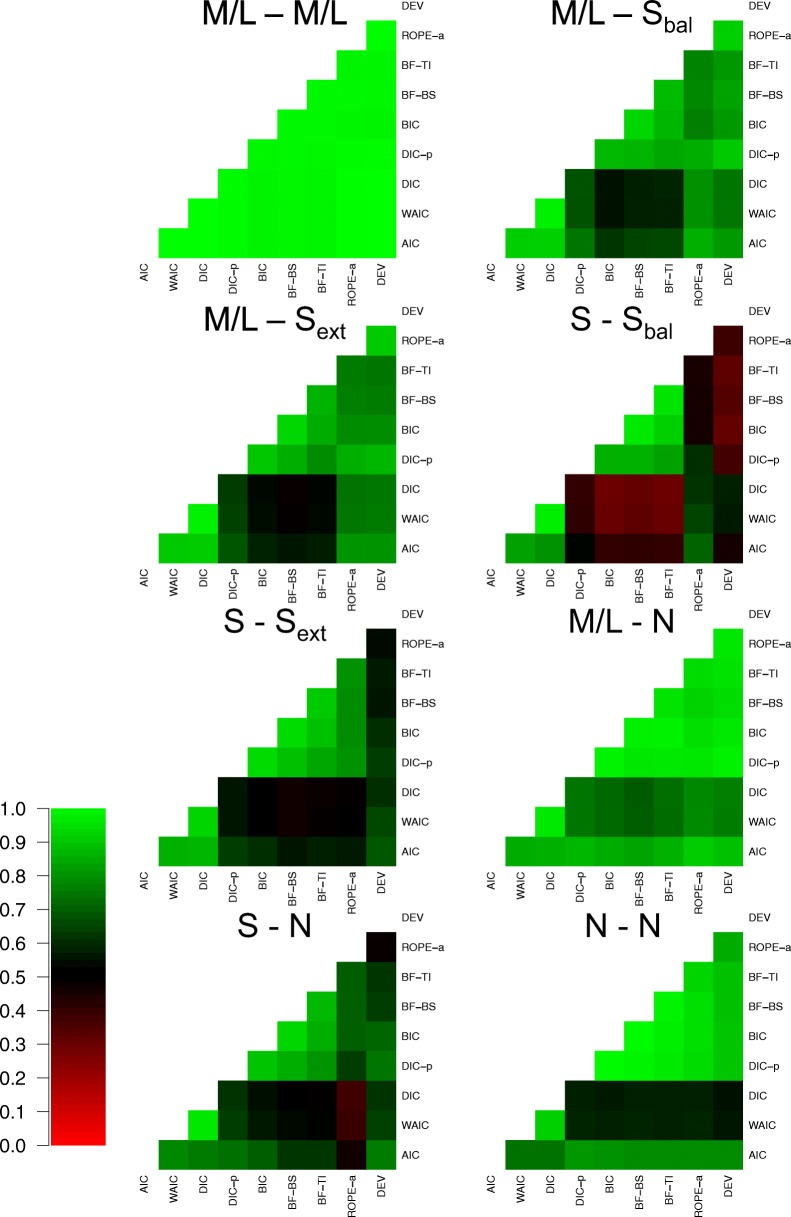
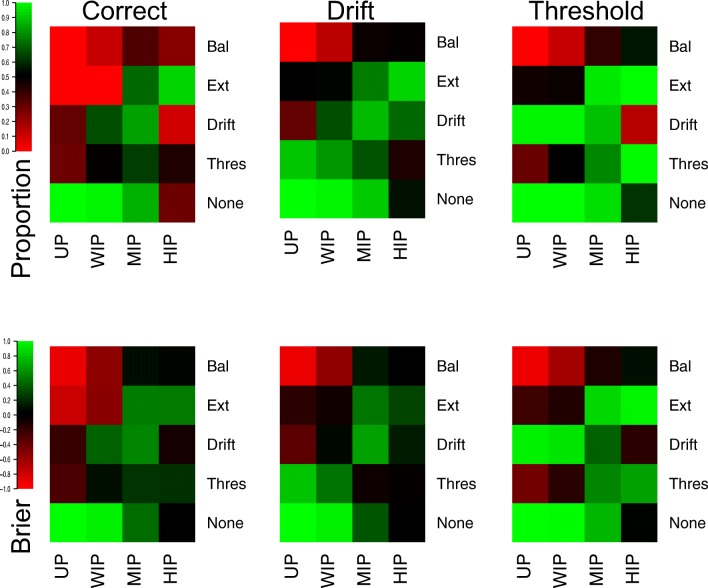
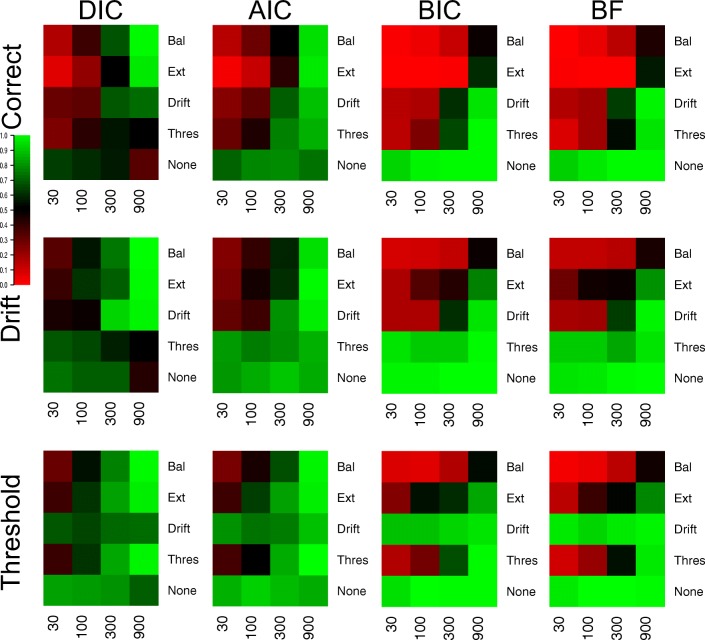
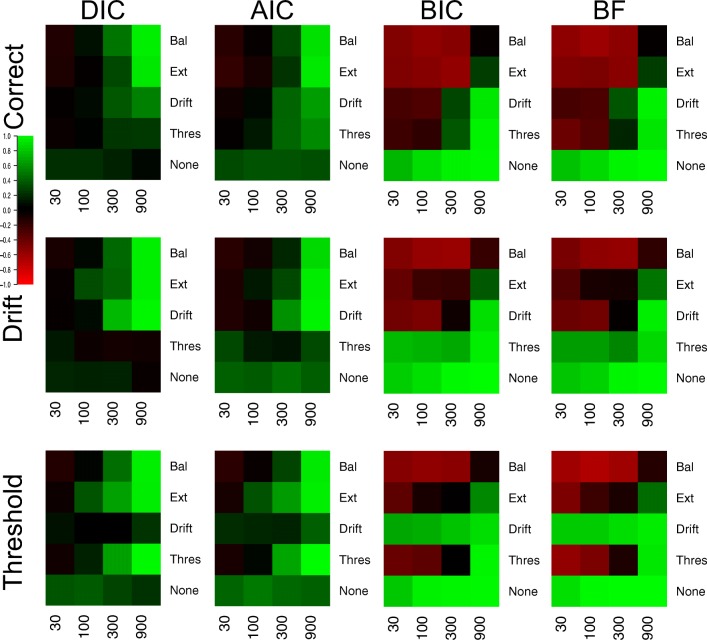
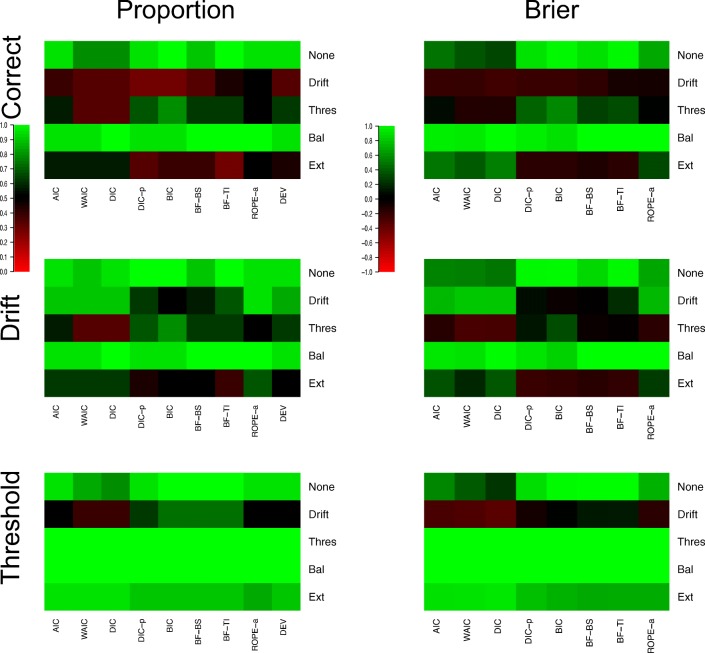
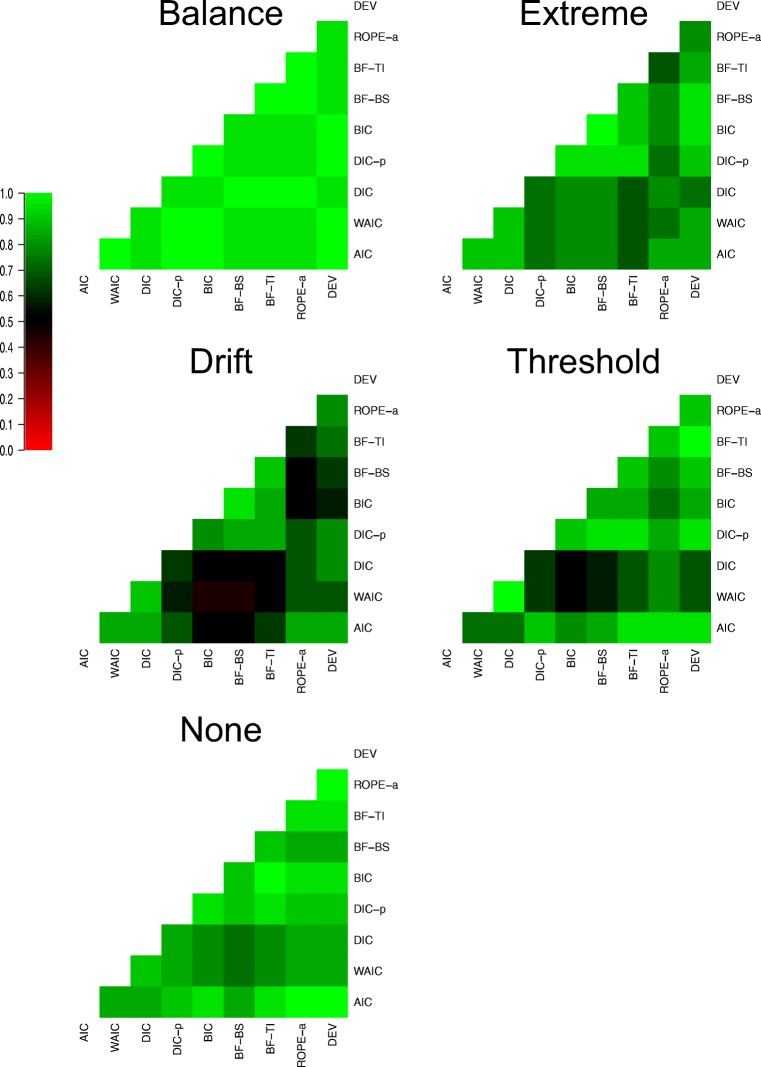
Evidence accumulations models (EAMs) have become the dominant modeling framework within rapid decision-making, using choice response time distributions to make inferences about the underlying decision process. These models are often applied to empirical data as "measurement tools", with different theoretical accounts being contrasted within the framework of the model. Some method is then needed to decide between these competing theoretical accounts, as only assessing the models on their ability to fit trends in the empirical data ignores model flexibility, and therefore, creates a bias towards more flexible models. However, there is no objectively optimal method to select between models, with methods varying in both their computational tractability and theoretical basis. I provide a systematic comparison between nine different model selection methods using a popular EAM-the linear ballistic accumulator (LBA; Brown & Heathcote, Cognitive Psychology 57(3), 153-178 2008)-in a large-scale simulation study and the empirical data of Dutilh et al. (Psychonomic Bulletin and Review, 1-19 2018). I find that the "predictive accuracy" class of methods (i.e., the Akaike Information Criterion [AIC], the Deviance Information Criterion [DIC], and the Widely Applicable Information Criterion [WAIC]) make different inferences to the "Bayes factor" class of methods (i.e., the Bayesian Information Criterion [BIC], and Bayes factors) in many, but not all, instances, and that the simpler methods (i.e., AIC and BIC) make inferences that are highly consistent with their more complex counterparts. These findings suggest that researchers should be able to use simpler "parameter counting" methods when applying the LBA and be confident in their inferences, but that researchers need to carefully consider and justify the general class of model selection method that they use, as different classes of methods often result in different inferences.
Keywords: Bayes factors; Decision-making; Model selection; Predictive accuracy; Response time modeling.
Figures
References
-
- Akaike H. A new look at the statistical model identification. IEEE Transactions on Automatic Control. 1974;19(6):716–723.
-
- Annis, J., Evans, N.J., Miller, B.J., & Palmeri, T.J. (2018). Thermodynamic integration and steppingstone sampling methods for estimating Bayes factors: A tutorial. Retrieved from https://psyarxiv.com/r8sgn - PMC - PubMed
-
- Box GE, Draper NR. Empirical model-building and response surfaces. New York: Wiley; 1987.
-
- Brier GW. Verification of forecasts expressed in terms of probability. Monthey Weather Review. 1950;78(1):1–3.
MeSH terms
LinkOut - more resources
Full Text Sources
