

In-memory computing on a photonic platform
- PMID: 30793028
- PMCID: PMC6377270
- DOI: 10.1126/sciadv.aau5759
In-memory computing on a photonic platform
Abstract
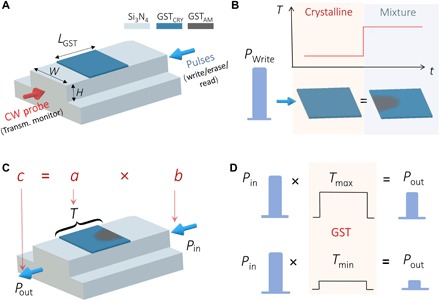
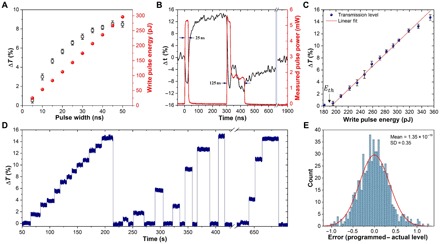
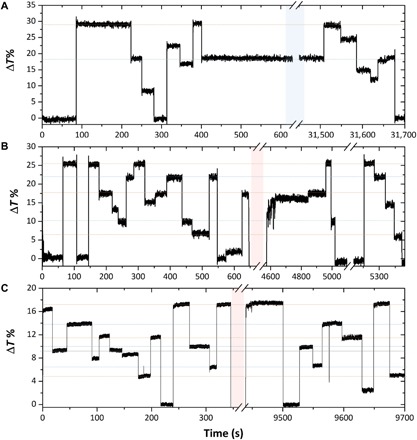
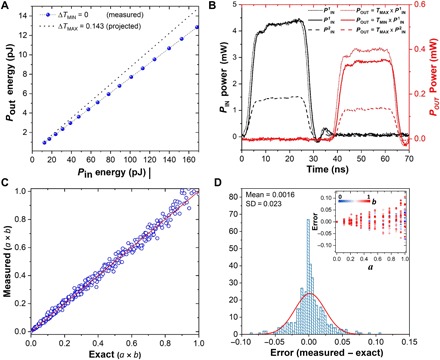
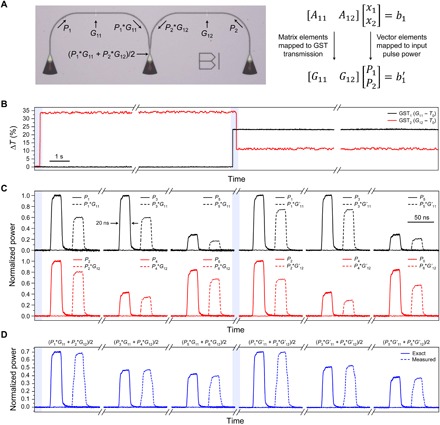
Collocated data processing and storage are the norm in biological computing systems such as the mammalian brain. As our ability to create better hardware improves, new computational paradigms are being explored beyond von Neumann architectures. Integrated photonic circuits are an attractive solution for on-chip computing which can leverage the increased speed and bandwidth potential of the optical domain, and importantly, remove the need for electro-optical conversions. Here we show that we can combine integrated optics with collocated data storage and processing to enable all-photonic in-memory computations. By employing nonvolatile photonic elements based on the phase-change material, Ge2Sb2Te5, we achieve direct scalar and matrix-vector multiplication, featuring a novel single-shot Write/Erase and a drift-free process. The output pulse, carrying the information of the light-matter interaction, is the result of the computation. Our all-optical approach is novel, easy to fabricate and operate, and sets the stage for development of entirely photonic computers.
Figures
References
-
- Sun C., Wade M. T., Lee Y., Orcutt J. S., Alloatti L., Georgas M. S., Waterman A. S., Shainline J. M., Avizienis R. R., Lin S., Moss B. R., Kumar R., Pavanello F., Atabaki A. H., Cook H. M., Ou A. J., Leu J. C., Chen Y.-H., Asanović K., Ram R. J., Popović M. A., Stojanović V. M., Single-chip microprocessor that communicates directly using light. Nature 528, 534–538 (2015). - PubMed
-
- Vandoorne K., Mechet P., Van Vaerenbergh T., Fiers M., Morthier G., Verstraeten D., Schrauwen B., Dambre J., Bienstman P., Experimental demonstration of reservoir computing on a silicon photonics chip. Nat. Commun. 5, 3541 (2014). - PubMed
-
- Shainline J. M., Buckley S. M., Mirin R. P., Nam S. W., Superconducting optoelectronic circuits for neuromorphic computing. Phys. Rev. Appl. 7, 034013 (2017).
-
- Shen Y., Harris N. C., Skirlo S., Prabhu M., Baehr-Jones T., Hochberg M., Sun X., Zhao S., Larochelle H., Englund D., Soljačić M., Deep learning with coherent nanophotonic circuits. Nat. Photonics. 11, 441–446 (2017).
-
- D. Kielpinski, R. Bose, J. Pelc, T. Van Vaerenbergh, G. Mendoza, N. Tezak, R. G. Beausoleil, Information processing with large-scale optical integrated circuits, in 2016 IEEE International Conference on Rebooting Computing (ICRC) (2016), San Diego, CA, USA, 17 to 19 October 2016.
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
