

DVID: Distributed Versioned Image-Oriented Dataservice
- PMID: 30804760
- PMCID: PMC6371063
- DOI: 10.3389/fncir.2019.00005
DVID: Distributed Versioned Image-Oriented Dataservice
Abstract
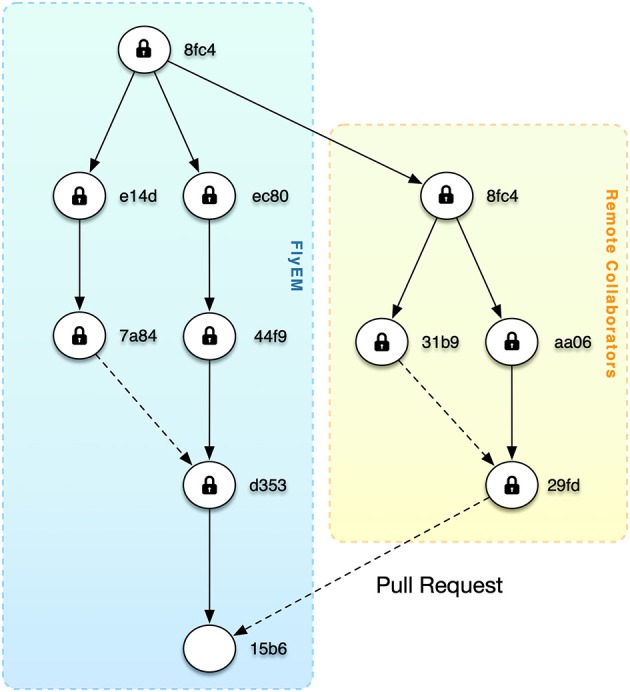
Open-source software development has skyrocketed in part due to community tools like github.com, which allows publication of code as well as the ability to create branches and push accepted modifications back to the original repository. As the number and size of EM-based datasets increases, the connectomics community faces similar issues when we publish snapshot data corresponding to a publication. Ideally, there would be a mechanism where remote collaborators could modify branches of the data and then flexibly reintegrate results via moderated acceptance of changes. The DVID system provides a web-based connectomics API and the first steps toward such a distributed versioning approach to EM-based connectomics datasets. Through its use as the central data resource for Janelia's FlyEM team, we have integrated the concepts of distributed versioning into reconstruction workflows, allowing support for proofreader training and segmentation experiments through branched, versioned data. DVID also supports persistence to a variety of storage systems from high-speed local SSDs to cloud-based object stores, which allows its deployment on laptops as well as large servers. The tailoring of the backend storage to each type of connectomics data leads to efficient storage and fast queries. DVID is freely available as open-source software with an increasing number of supported storage options.
Keywords: EM reconstruction; big data; collaboration; connectomics; dataservice; datastore; distributed version control; versioning.
Figures
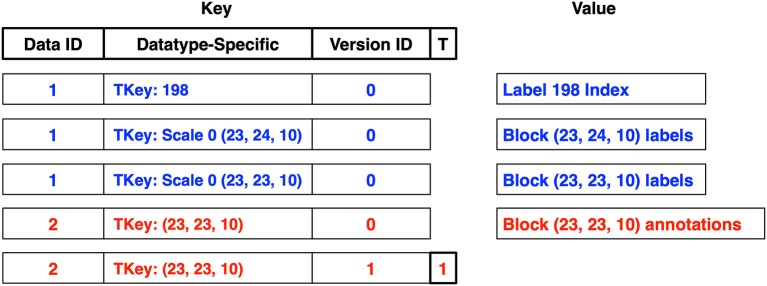
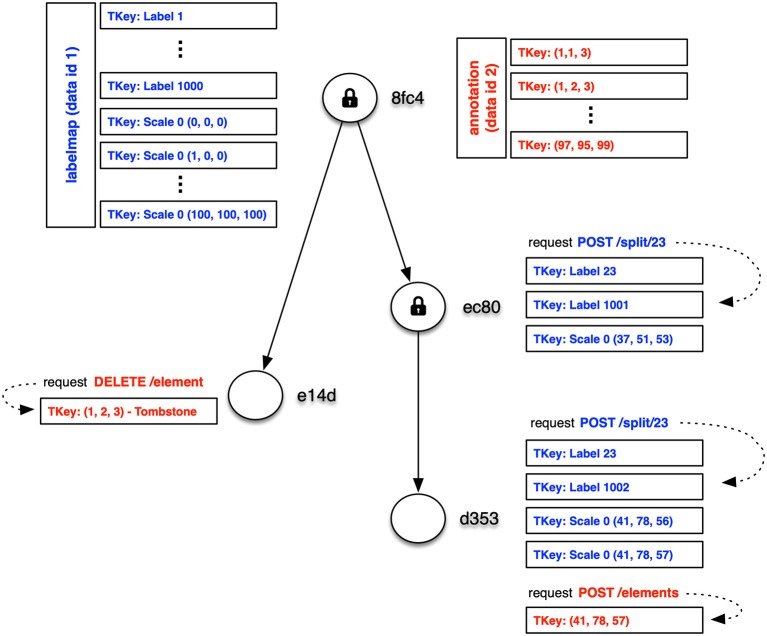
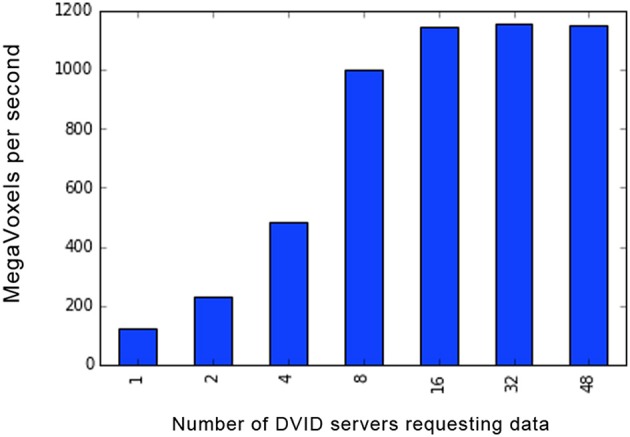
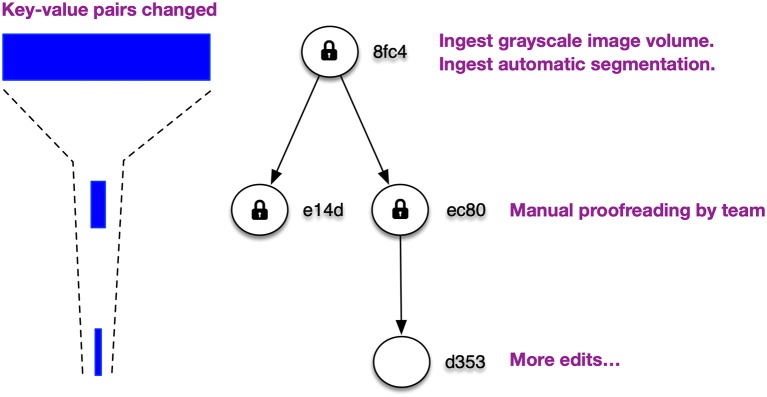
References
-
- Bhardwaj A., Bhattacherjee S., Chavan A., Deshpande A., Elmore A. J., Madden S., et al. (2014). DataHub: collaborative data science & dataset version management at scale. arXiv.org.
-
- Dutka L., Wrzeszcz M., Lichoń T., Slota R., Zemek K., Trzepla K., et al. (2015). Onedata - a step forward towards globalization of data access for computing infrastructures. Proc. Comput. Sci. 51, 2843–2847. 10.1016/j.procs.2015.05.445 - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources