

Comparative Accuracy of Diagnosis by Collective Intelligence of Multiple Physicians vs Individual Physicians
- PMID: 30821822
- PMCID: PMC6484633
- DOI: 10.1001/jamanetworkopen.2019.0096
Comparative Accuracy of Diagnosis by Collective Intelligence of Multiple Physicians vs Individual Physicians
Abstract
Importance: The traditional approach of diagnosis by individual physicians has a high rate of misdiagnosis. Pooling multiple physicians' diagnoses (collective intelligence) is a promising approach to reducing misdiagnoses, but its accuracy in clinical cases is unknown to date.
Objective: To assess how the diagnostic accuracy of groups of physicians and trainees compares with the diagnostic accuracy of individual physicians.
Design, setting, and participants: Cross-sectional study using data from the Human Diagnosis Project (Human Dx), a multicountry data set of ranked differential diagnoses by individual physicians, graduate trainees, and medical students (users) solving user-submitted, structured clinical cases. From May 7, 2014, to October 5, 2016, groups of 2 to 9 randomly selected physicians solved individual cases. Data analysis was performed from March 16, 2017, to July 30, 2018.
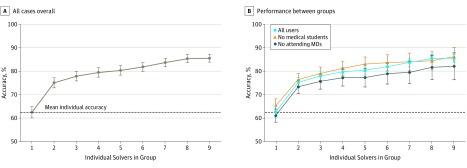
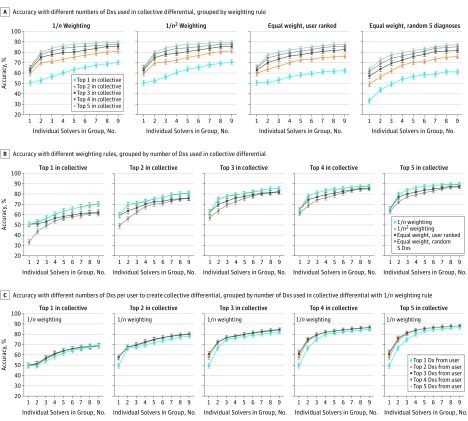
Main outcomes and measures: The primary outcome was diagnostic accuracy, assessed as a correct diagnosis in the top 3 ranked diagnoses for an individual; for groups, the top 3 diagnoses were a collective differential generated using a weighted combination of user diagnoses with a variety of approaches. A version of the McNemar test was used to account for clustering across repeated solvers to compare diagnostic accuracy.
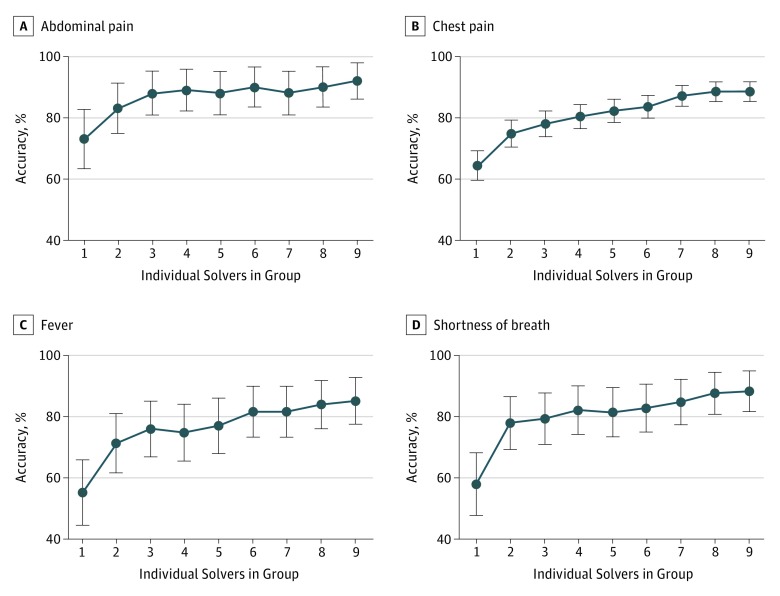
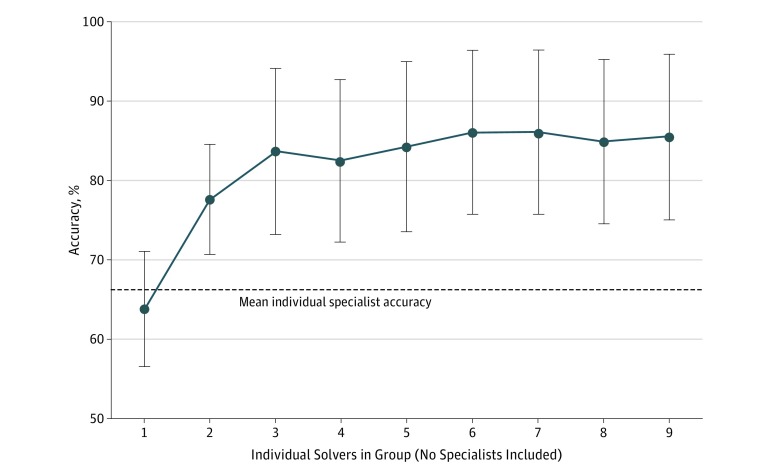
Results: Of the 2069 users solving 1572 cases from the Human Dx data set, 1228 (59.4%) were residents or fellows, 431 (20.8%) were attending physicians, and 410 (19.8%) were medical students. Collective intelligence was associated with increasing diagnostic accuracy, from 62.5% (95% CI, 60.1%-64.9%) for individual physicians up to 85.6% (95% CI, 83.9%-87.4%) for groups of 9 (23.0% difference; 95% CI, 14.9%-31.2%; P < .001). The range of improvement varied by the specifications used for combining groups' diagnoses, but groups consistently outperformed individuals regardless of approach. Absolute improvement in accuracy from individuals to groups of 9 varied by presenting symptom from an increase of 17.3% (95% CI, 6.4%-28.2%; P = .002) for abdominal pain to 29.8% (95% CI, 3.7%-55.8%; P = .02) for fever. Groups from 2 users (77.7% accuracy; 95% CI, 70.1%-84.6%) to 9 users (85.5% accuracy; 95% CI, 75.1%-95.9%) outperformed individual specialists in their subspecialty (66.3% accuracy; 95% CI, 59.1%-73.5%; P < .001 vs groups of 2 and 9).
Conclusions and relevance: A collective intelligence approach was associated with higher diagnostic accuracy compared with individuals, including individual specialists whose expertise matched the case diagnosis, across a range of medical cases. Given the few proven strategies to address misdiagnosis, this technique merits further study in clinical settings.
Conflict of interest statement
Figures
Comment in
-
Collective Intelligence for Clinical Diagnosis-Are 2 (or 3) Heads Better Than 1?JAMA Netw Open. 2019 Mar 1;2(3):e191071. doi: 10.1001/jamanetworkopen.2019.1071. JAMA Netw Open. 2019. PMID: 30821821 No abstract available.
References
-
- Shojania KG, Burton EC, McDonald KM, Goldman L Autopsy as an outcome and performance measure: summary. Agency for Healthcare Research and Quality. https://www.ncbi.nlm.nih.gov/books/NBK11951/ Published 2002. Accessed January 28, 2019.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
