

Control of a Humanoid NAO Robot by an Adaptive Bioinspired Cerebellar Module in 3D Motion Tasks
- PMID: 30833964
- PMCID: PMC6369512
- DOI: 10.1155/2019/4862157
Control of a Humanoid NAO Robot by an Adaptive Bioinspired Cerebellar Module in 3D Motion Tasks
Erratum in
-
Corrigendum to "Control of a Humanoid NAO Robot by an Adaptive Bioinspired Cerebellar Module in 3D Motion Tasks".Comput Intell Neurosci. 2020 Oct 22;2020:2390349. doi: 10.1155/2020/2390349. eCollection 2020. Comput Intell Neurosci. 2020. PMID: 33149735 Free PMC article.
Abstract
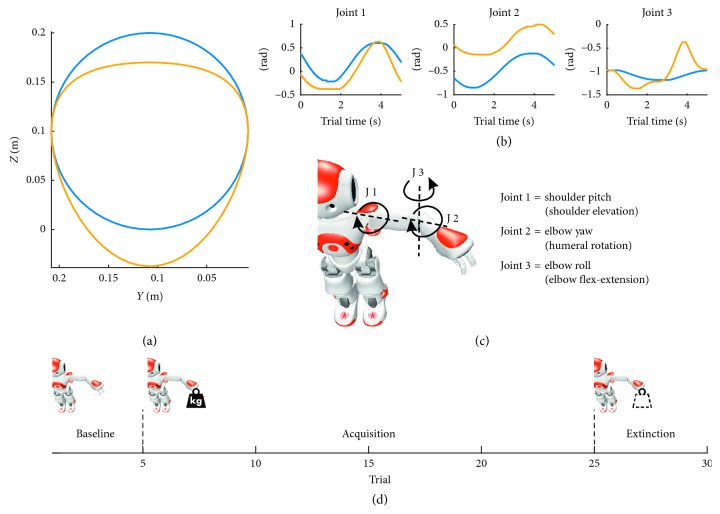
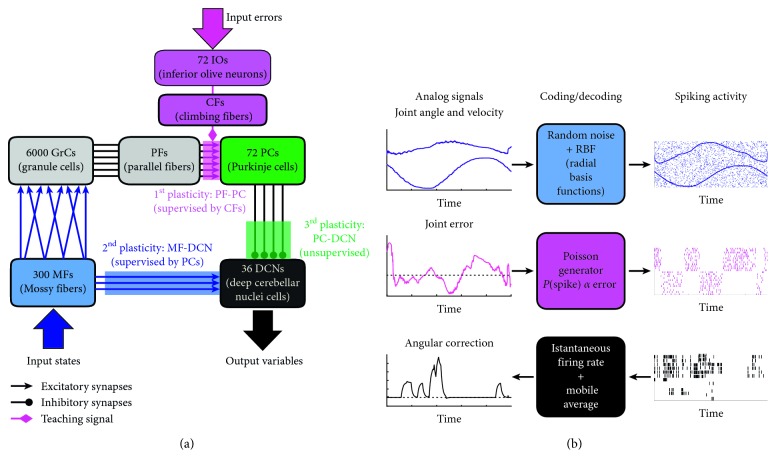
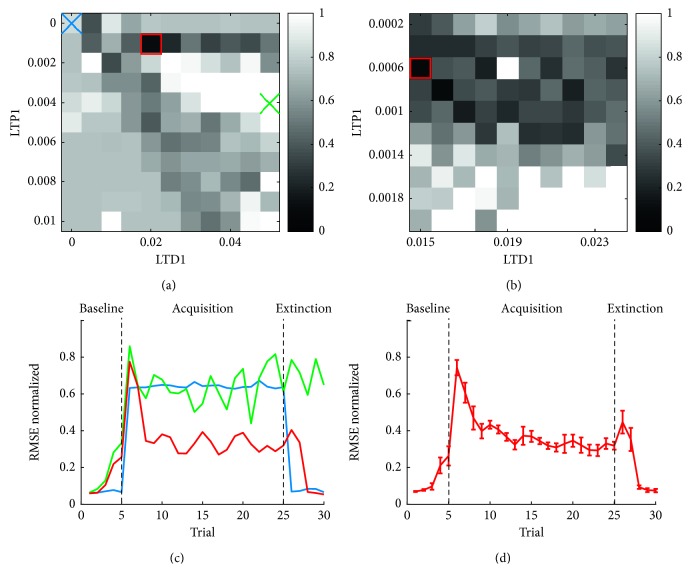
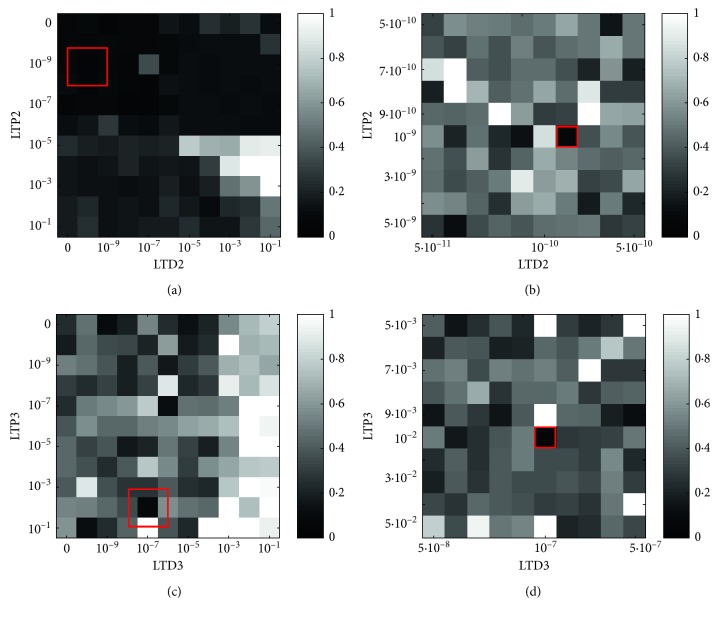
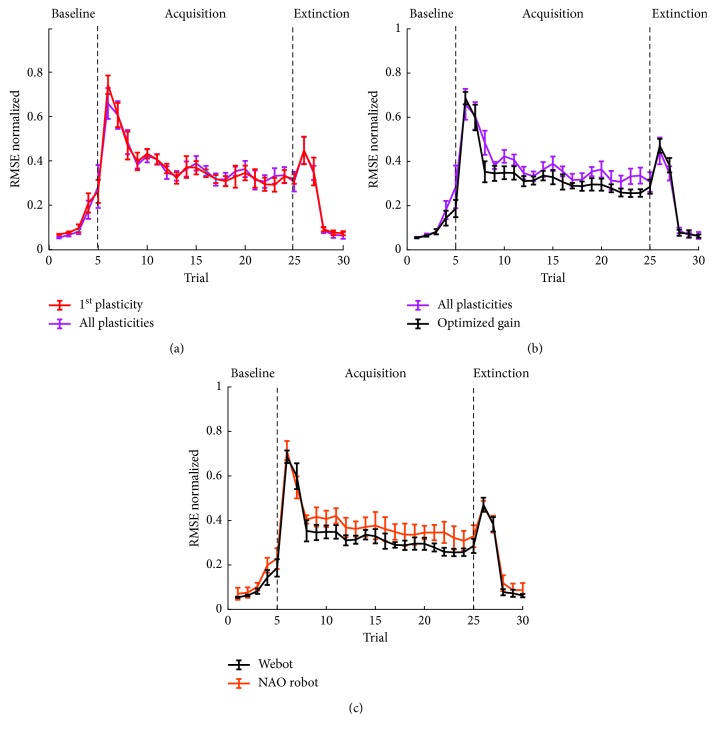
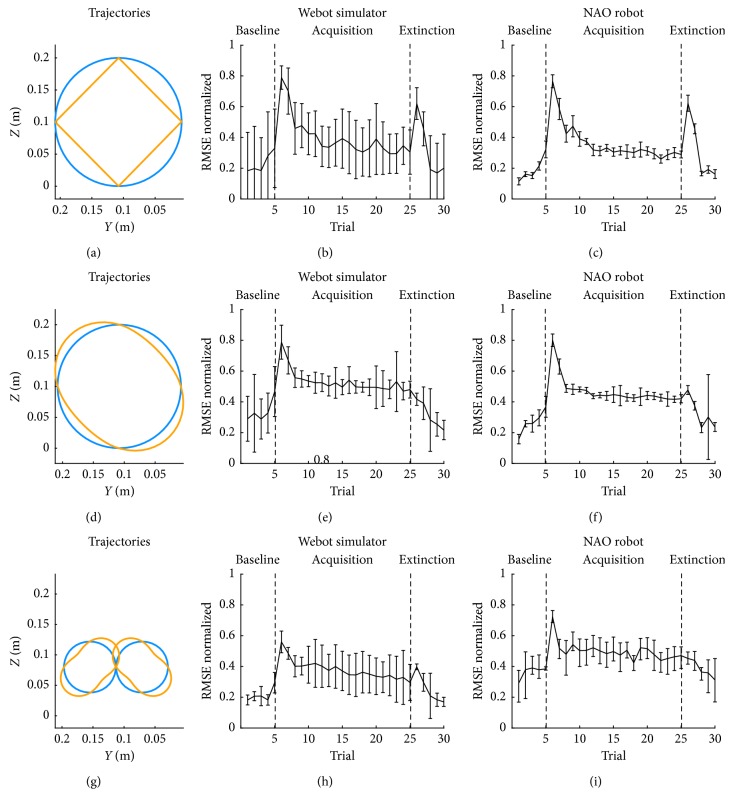
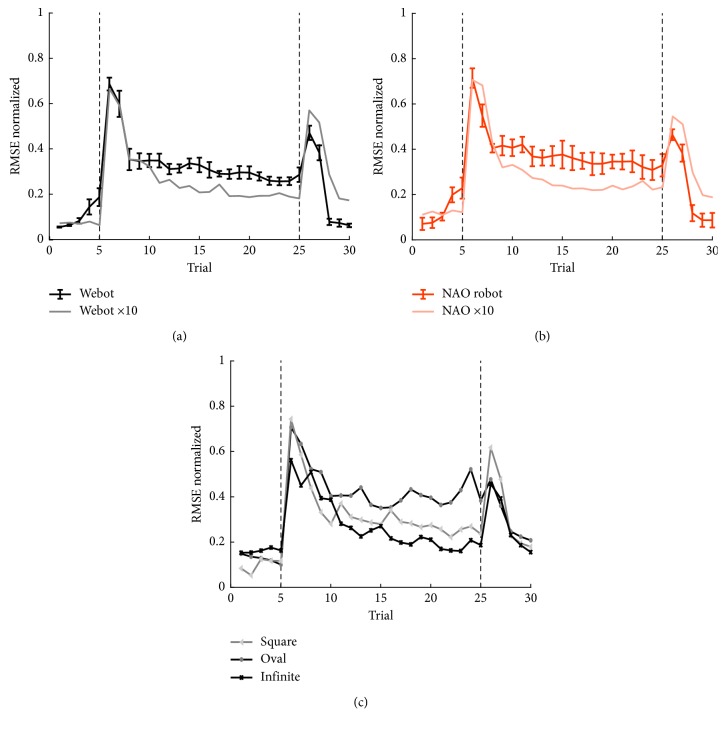
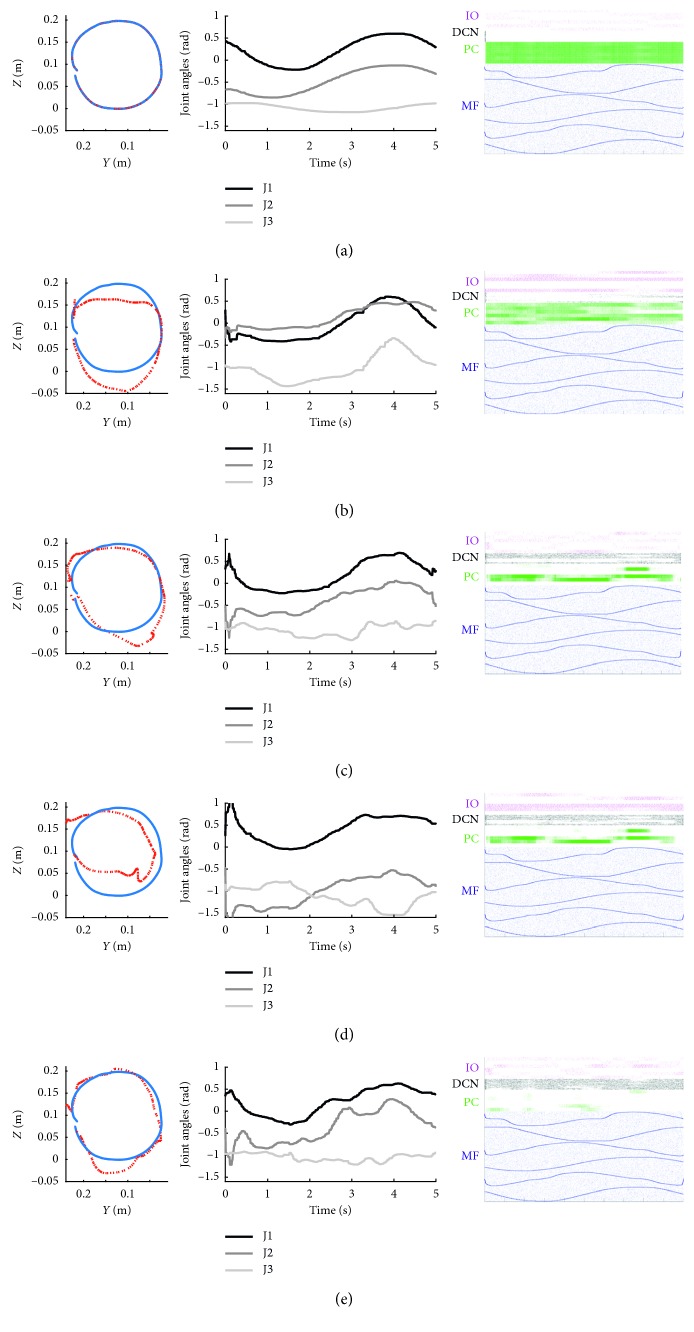
A bioinspired adaptive model, developed by means of a spiking neural network made of thousands of artificial neurons, has been leveraged to control a humanoid NAO robot in real time. The learning properties of the system have been challenged in a classic cerebellum-driven paradigm, a perturbed upper limb reaching protocol. The neurophysiological principles used to develop the model succeeded in driving an adaptive motor control protocol with baseline, acquisition, and extinction phases. The spiking neural network model showed learning behaviours similar to the ones experimentally measured with human subjects in the same task in the acquisition phase, while resorted to other strategies in the extinction phase. The model processed in real-time external inputs, encoded as spikes, and the generated spiking activity of its output neurons was decoded, in order to provide the proper correction on the motor actuators. Three bidirectional long-term plasticity rules have been embedded for different connections and with different time scales. The plasticities shaped the firing activity of the output layer neurons of the network. In the perturbed upper limb reaching protocol, the neurorobot successfully learned how to compensate for the external perturbation generating an appropriate correction. Therefore, the spiking cerebellar model was able to reproduce in the robotic platform how biological systems deal with external sources of error, in both ideal and real (noisy) environments.
Figures
References
-
- Bartha G. T., Thompson R. F. The Handbook of Brain Theory and Neural Networks. Cambridge, MA, USA: MIT Press; 1998. Cerebellum and conditioning; pp. 169–172.
-
- de Nó R. L. Vestibulo-ocular reflex arc. Archives of Neurology and Psychiatry. 1933;30(2):p. 245. doi: 10.1001/archneurpsyc.1933.02240140009001. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
