

Exploring the GDB-13 chemical space using deep generative models
- PMID: 30868314
- PMCID: PMC6419837
- DOI: 10.1186/s13321-019-0341-z
Exploring the GDB-13 chemical space using deep generative models
Abstract
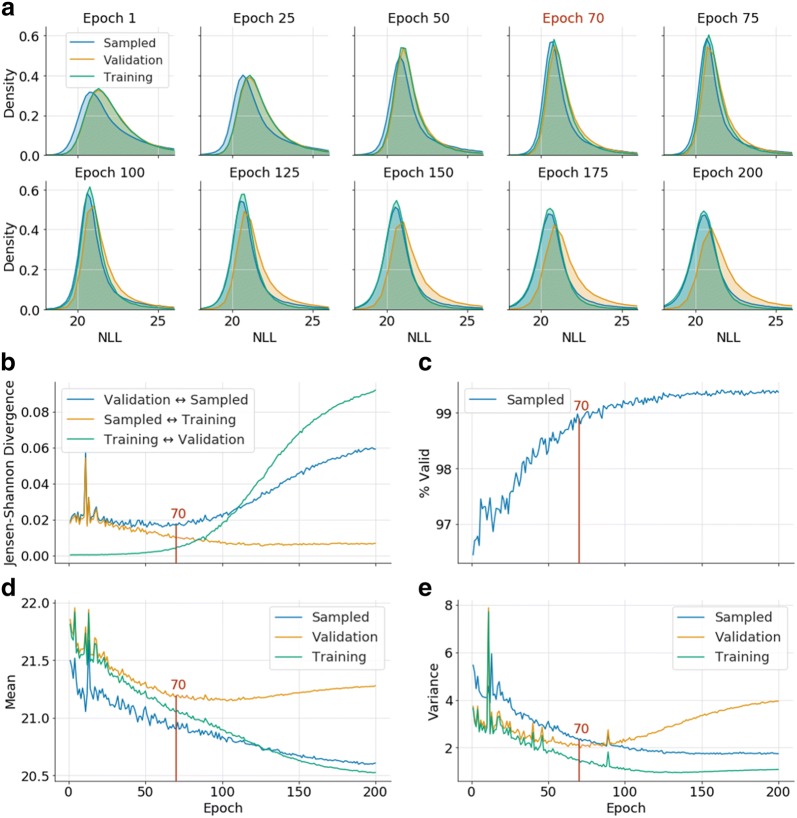
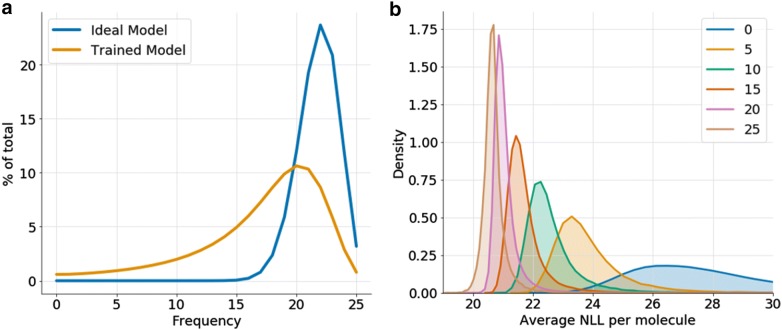
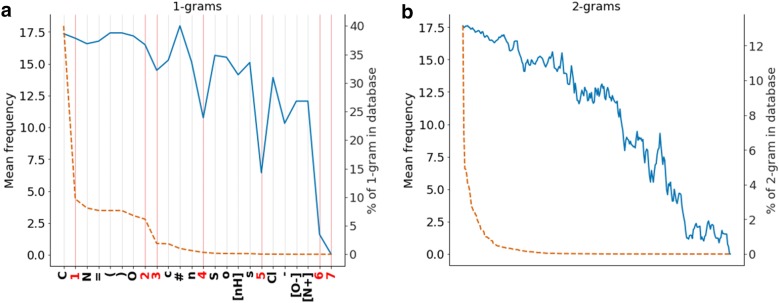
Recent applications of recurrent neural networks (RNN) enable training models that sample the chemical space. In this study we train RNN with molecular string representations (SMILES) with a subset of the enumerated database GDB-13 (975 million molecules). We show that a model trained with 1 million structures (0.1% of the database) reproduces 68.9% of the entire database after training, when sampling 2 billion molecules. We also developed a method to assess the quality of the training process using negative log-likelihood plots. Furthermore, we use a mathematical model based on the "coupon collector problem" that compares the trained model to an upper bound and thus we are able to quantify how much it has learned. We also suggest that this method can be used as a tool to benchmark the learning capabilities of any molecular generative model architecture. Additionally, an analysis of the generated chemical space was performed, which shows that, mostly due to the syntax of SMILES, complex molecules with many rings and heteroatoms are more difficult to sample.
Keywords: Chemical databases; Chemical space exploration; Deep generative models; Deep learning; Recurrent neural networks.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures





Similar articles
-
Randomized SMILES strings improve the quality of molecular generative models.J Cheminform. 2019 Nov 21;11(1):71. doi: 10.1186/s13321-019-0393-0. J Cheminform. 2019. PMID: 33430971 Free PMC article.
-
Comparative Study of Deep Generative Models on Chemical Space Coverage.J Chem Inf Model. 2021 Jun 28;61(6):2572-2581. doi: 10.1021/acs.jcim.0c01328. Epub 2021 May 20. J Chem Inf Model. 2021. PMID: 34015916
-
GEN: highly efficient SMILES explorer using autodidactic generative examination networks.J Cheminform. 2020 Apr 10;12(1):22. doi: 10.1186/s13321-020-00425-8. J Cheminform. 2020. PMID: 33430998 Free PMC article.
-
Training recurrent neural networks as generative neural networks for molecular structures: how does it impact drug discovery?Expert Opin Drug Discov. 2022 Oct;17(10):1071-1079. doi: 10.1080/17460441.2023.2134340. Epub 2022 Oct 17. Expert Opin Drug Discov. 2022. PMID: 36216812 Review.
-
Using deep neural networks to explore chemical space.Expert Opin Drug Discov. 2022 Mar;17(3):297-304. doi: 10.1080/17460441.2022.2019704. Epub 2021 Dec 29. Expert Opin Drug Discov. 2022. PMID: 34918594 Review.
Cited by
-
Identification of nanomolar adenosine A2A receptor ligands using reinforcement learning and structure-based drug design.Nat Commun. 2025 Jul 1;16(1):5485. doi: 10.1038/s41467-025-60629-0. Nat Commun. 2025. PMID: 40592852 Free PMC article.
-
Transfer Learning-Enhanced Prediction of Glass Transition Temperature in Bismaleimide-Based Polyimides.Polymers (Basel). 2025 Jun 30;17(13):1833. doi: 10.3390/polym17131833. Polymers (Basel). 2025. PMID: 40647844 Free PMC article.
-
ChemSpaceAL: An Efficient Active Learning Methodology Applied to Protein-Specific Molecular Generation.ArXiv [Preprint]. 2023 Dec 4:arXiv:2309.05853v2. ArXiv. 2023. Update in: J Chem Inf Model. 2024 Feb 12;64(3):653-665. doi: 10.1021/acs.jcim.3c01456. PMID: 37744464 Free PMC article. Updated. Preprint.
-
Substructure-based neural machine translation for retrosynthetic prediction.J Cheminform. 2021 Jan 11;13(1):4. doi: 10.1186/s13321-020-00482-z. J Cheminform. 2021. PMID: 33431017 Free PMC article.
-
DeepGraphMolGen, a multi-objective, computational strategy for generating molecules with desirable properties: a graph convolution and reinforcement learning approach.J Cheminform. 2020 Sep 4;12(1):53. doi: 10.1186/s13321-020-00454-3. J Cheminform. 2020. PMID: 33431037 Free PMC article.
References
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
