

Accounting for missing data in statistical analyses: multiple imputation is not always the answer
- PMID: 30879056
- PMCID: PMC6693809
- DOI: 10.1093/ije/dyz032
Accounting for missing data in statistical analyses: multiple imputation is not always the answer
Abstract
Background: Missing data are unavoidable in epidemiological research, potentially leading to bias and loss of precision. Multiple imputation (MI) is widely advocated as an improvement over complete case analysis (CCA). However, contrary to widespread belief, CCA is preferable to MI in some situations.
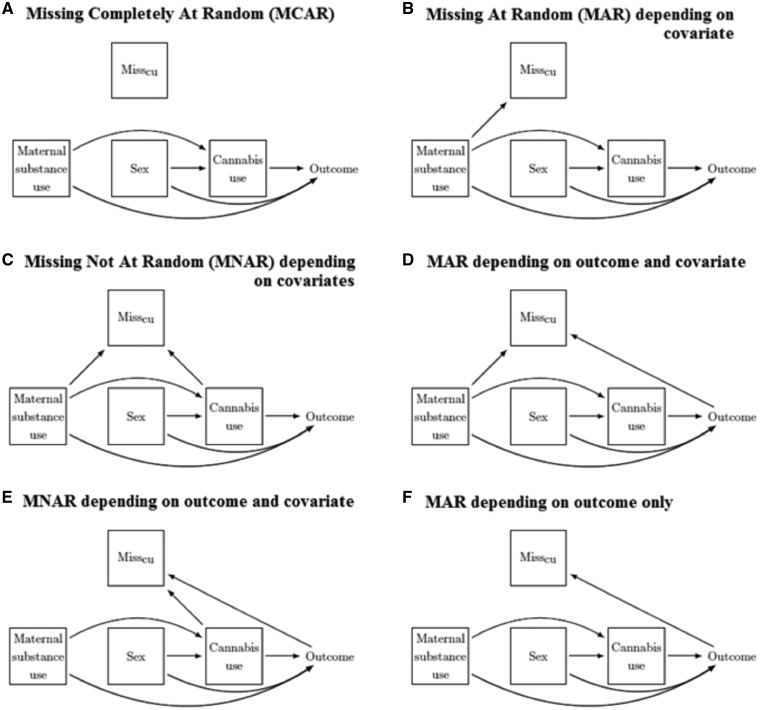
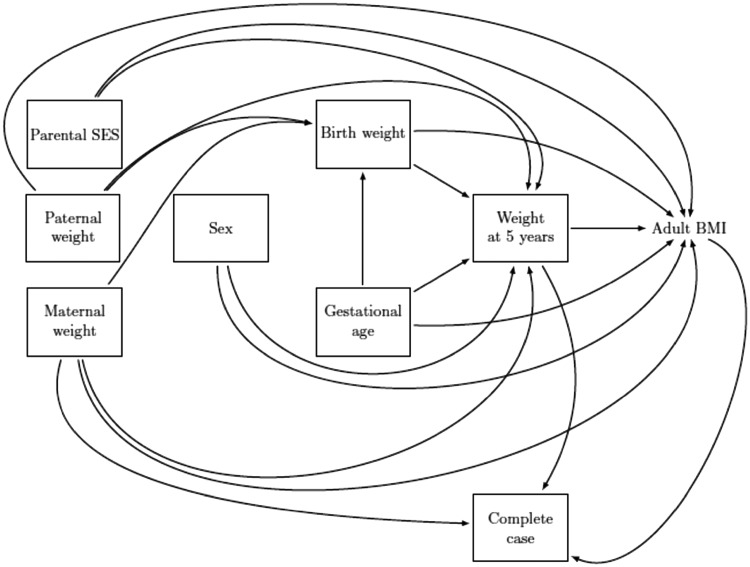
Methods: We provide guidance on choice of analysis when data are incomplete. Using causal diagrams to depict missingness mechanisms, we describe when CCA will not be biased by missing data and compare MI and CCA, with respect to bias and efficiency, in a range of missing data situations. We illustrate selection of an appropriate method in practice.
Results: For most regression models, CCA gives unbiased results when the chance of being a complete case does not depend on the outcome after taking the covariates into consideration, which includes situations where data are missing not at random. Consequently, there are situations in which CCA analyses are unbiased while MI analyses, assuming missing at random (MAR), are biased. By contrast MI, unlike CCA, is valid for all MAR situations and has the potential to use information contained in the incomplete cases and auxiliary variables to reduce bias and/or improve precision. For this reason, MI was preferred over CCA in our real data example.
Conclusions: Choice of method for dealing with missing data is crucial for validity of conclusions, and should be based on careful consideration of the reasons for the missing data, missing data patterns and the availability of auxiliary information.
Keywords: Complete case analysis; inverse probability weighting; missing data; missing data mechanisms; missing data patterns; multiple imputation.
© The Author(s) 2019. Published by Oxford University Press on behalf of the International Epidemiological Association.
Figures
References
-
- Little RJA, Rubin DB.. Statistical Analysis with Missing Data. 2nd edn. Hoboken, NJ: Wiley, 2002.
-
- Schafer JL, Graham JW.. Missing data: our view of the state of the art. Psychol Methods 2002;7:147–77. - PubMed
-
- Molenberghs G, Fitzmaurice G, Kenward MG, Tsiatis A, Verbeke G.. Handbook of Missing Data Methodology. London: Chapman and Hall/CRC, 2014.
-
- Carpenter JR, Goldstein H, Kenward MG.. REALCOM-IMPUTE software for multilevel multiple imputation with mixed response types. J Stat Softw 2011;45:1–14.
-
- Honaker J, King G, Blackwell M.. Amelia II: a program for missing data. J Stat Softw 2011;45:1–47.
