

Validation of a Bioinformatics Workflow for Routine Analysis of Whole-Genome Sequencing Data and Related Challenges for Pathogen Typing in a European National Reference Center: Neisseria meningitidis as a Proof-of-Concept
- PMID: 30894839
- PMCID: PMC6414443
- DOI: 10.3389/fmicb.2019.00362
Validation of a Bioinformatics Workflow for Routine Analysis of Whole-Genome Sequencing Data and Related Challenges for Pathogen Typing in a European National Reference Center: Neisseria meningitidis as a Proof-of-Concept
Abstract
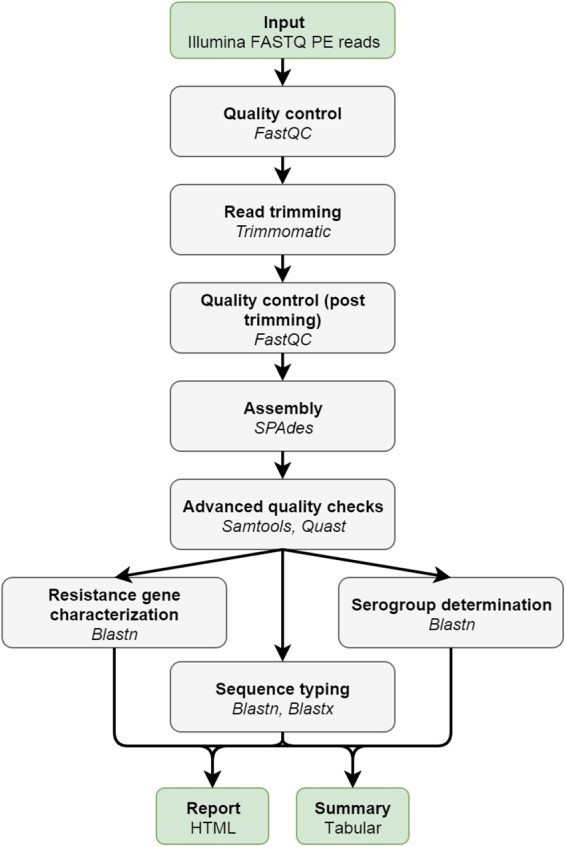
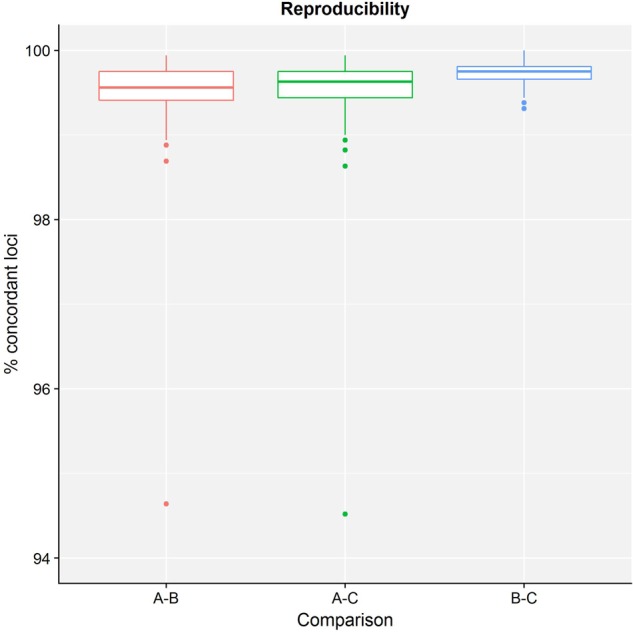
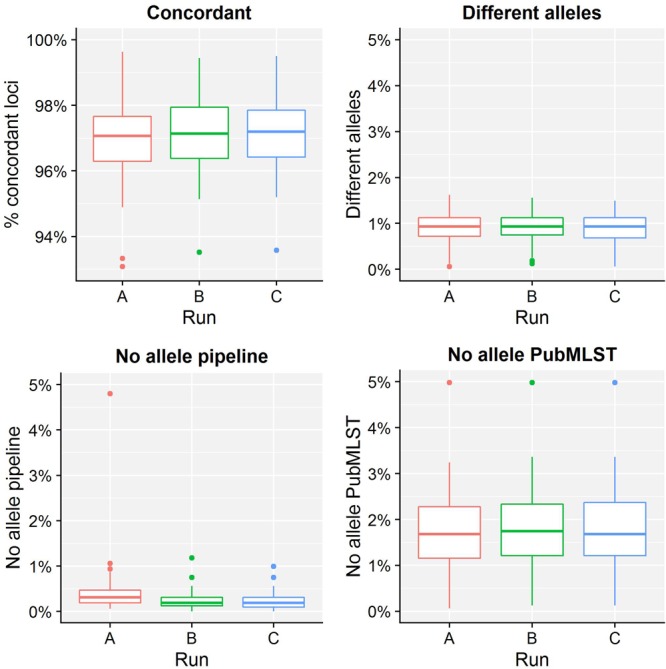
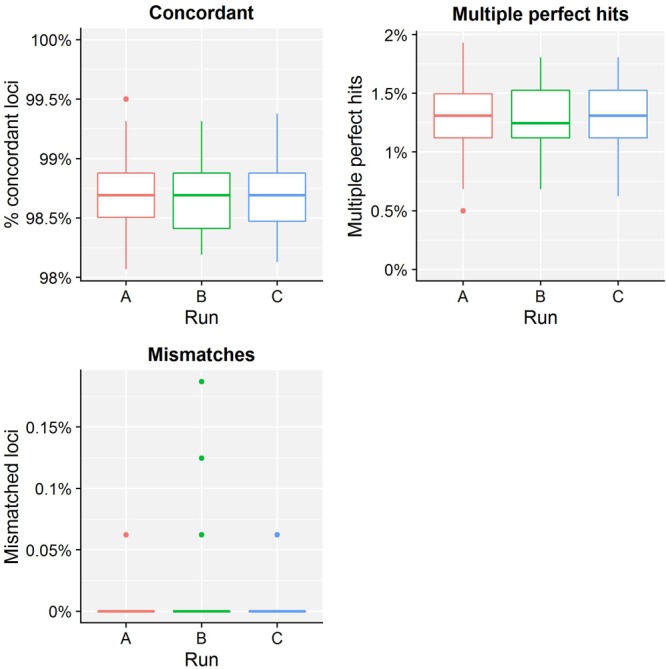
Despite being a well-established research method, the use of whole-genome sequencing (WGS) for routine molecular typing and pathogen characterization remains a substantial challenge due to the required bioinformatics resources and/or expertise. Moreover, many national reference laboratories and centers, as well as other laboratories working under a quality system, require extensive validation to demonstrate that employed methods are "fit-for-purpose" and provide high-quality results. A harmonized framework with guidelines for the validation of WGS workflows does currently, however, not exist yet, despite several recent case studies highlighting the urgent need thereof. We present a validation strategy focusing specifically on the exhaustive characterization of the bioinformatics analysis of a WGS workflow designed to replace conventionally employed molecular typing methods for microbial isolates in a representative small-scale laboratory, using the pathogen Neisseria meningitidis as a proof-of-concept. We adapted several classically employed performance metrics specifically toward three different bioinformatics assays: resistance gene characterization (based on the ARG-ANNOT, ResFinder, CARD, and NDARO databases), several commonly employed typing schemas (including, among others, core genome multilocus sequence typing), and serogroup determination. We analyzed a core validation dataset of 67 well-characterized samples typed by means of classical genotypic and/or phenotypic methods that were sequenced in-house, allowing to evaluate repeatability, reproducibility, accuracy, precision, sensitivity, and specificity of the different bioinformatics assays. We also analyzed an extended validation dataset composed of publicly available WGS data for 64 samples by comparing results of the different bioinformatics assays against results obtained from commonly used bioinformatics tools. We demonstrate high performance, with values for all performance metrics >87%, >97%, and >90% for the resistance gene characterization, sequence typing, and serogroup determination assays, respectively, for both validation datasets. Our WGS workflow has been made publicly available as a "push-button" pipeline for Illumina data at https://galaxy.sciensano.be to showcase its implementation for non-profit and/or academic usage. Our validation strategy can be adapted to other WGS workflows for other pathogens of interest and demonstrates the added value and feasibility of employing WGS with the aim of being integrated into routine use in an applied public health setting.
Keywords: Neisseria meningitidis; national reference center; public health; validation; whole-genome sequencing.
Figures
References
-
- Aanensen D. M., Feil E. J., Holden M. T. G., Dordel J., Yeats C. A., Fedosejev A., et al. (2016). Whole-genome sequencing for routine pathogen surveillance in public health: a population snapshot of invasive Staphylococcus aureus in Europe. MBio 7:e00444-16. 10.1128/mBio.00444-16 - DOI - PMC - PubMed
-
- Angers-Loustau A., Petrillo M., Bengtsson-Palme J., Berendonk T., Blais B., Chan K.-G., et al. (2018). The challenges of designing a benchmark strategy for bioinformatics pipelines in the identification of antimicrobial resistance determinants using next generation sequencing technologies. F1000Research 7:459. 10.12688/f1000research.14509.1 - DOI - PMC - PubMed
LinkOut - more resources
Full Text Sources