

Origins and evolution of CRISPR-Cas systems
- PMID: 30905284
- PMCID: PMC6452270
- DOI: 10.1098/rstb.2018.0087
Origins and evolution of CRISPR-Cas systems
Abstract
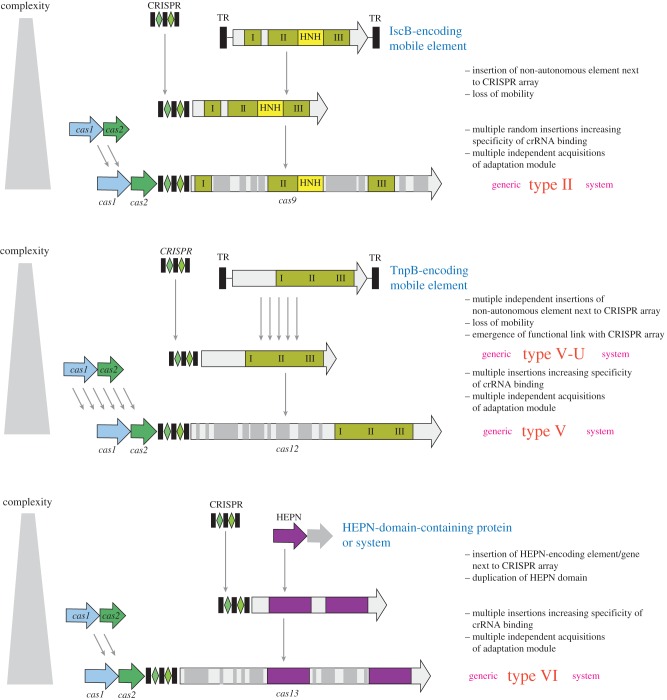
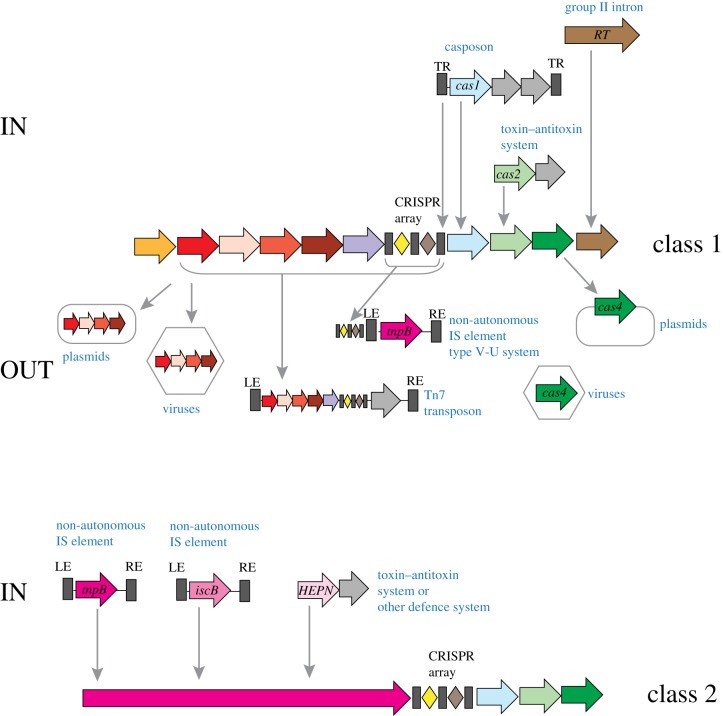
CRISPR-Cas, the bacterial and archaeal adaptive immunity systems, encompass a complex machinery that integrates fragments of foreign nucleic acids, mostly from mobile genetic elements (MGE), into CRISPR arrays embedded in microbial genomes. Transcripts of the inserted segments (spacers) are employed by CRISPR-Cas systems as guide (g)RNAs for recognition and inactivation of the cognate targets. The CRISPR-Cas systems consist of distinct adaptation and effector modules whose evolutionary trajectories appear to be at least partially independent. Comparative genome analysis reveals the origin of the adaptation module from casposons, a distinct type of transposons, which employ a homologue of Cas1 protein, the integrase responsible for the spacer incorporation into CRISPR arrays, as the transposase. The origin of the effector module(s) is far less clear. The CRISPR-Cas systems are partitioned into two classes, class 1 with multisubunit effectors, and class 2 in which the effector consists of a single, large protein. The class 2 effectors originate from nucleases encoded by different MGE, whereas the origin of the class 1 effector complexes remains murky. However, the recent discovery of a signalling pathway built into the type III systems of class 1 might offer a clue, suggesting that type III effector modules could have evolved from a signal transduction system involved in stress-induced programmed cell death. The subsequent evolution of the class 1 effector complexes through serial gene duplication and displacement, primarily of genes for proteins containing RNA recognition motif domains, can be hypothetically reconstructed. In addition to the multiple contributions of MGE to the evolution of CRISPR-Cas, the reverse flow of information is notable, namely, recruitment of minimalist variants of CRISPR-Cas systems by MGE for functions that remain to be elucidated. Here, we attempt a synthesis of the diverse threads that shed light on CRISPR-Cas origins and evolution. This article is part of a discussion meeting issue 'The ecology and evolution of prokaryotic CRISPR-Cas adaptive immune systems'.
Keywords: adaptive immunity; gene shuffling; mobile genetic elements; signalling.
Conflict of interest statement
We declare we have no competing interests.
Figures
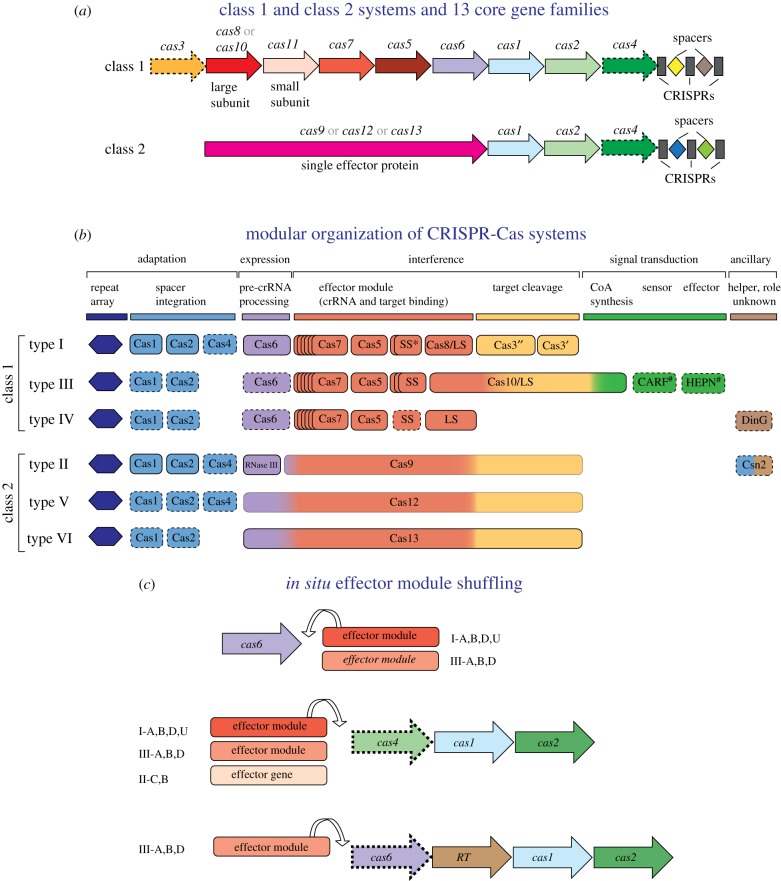
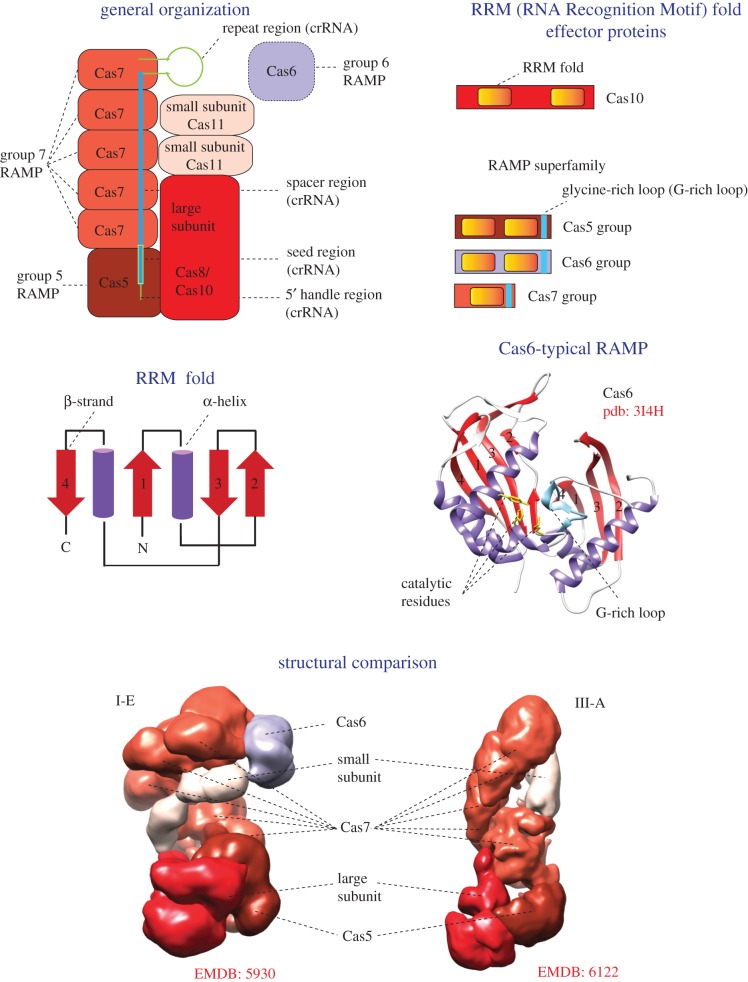
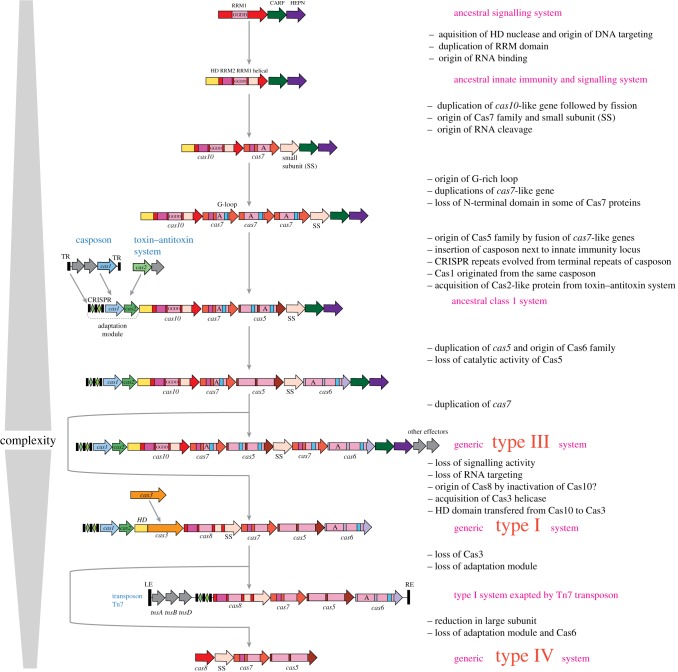
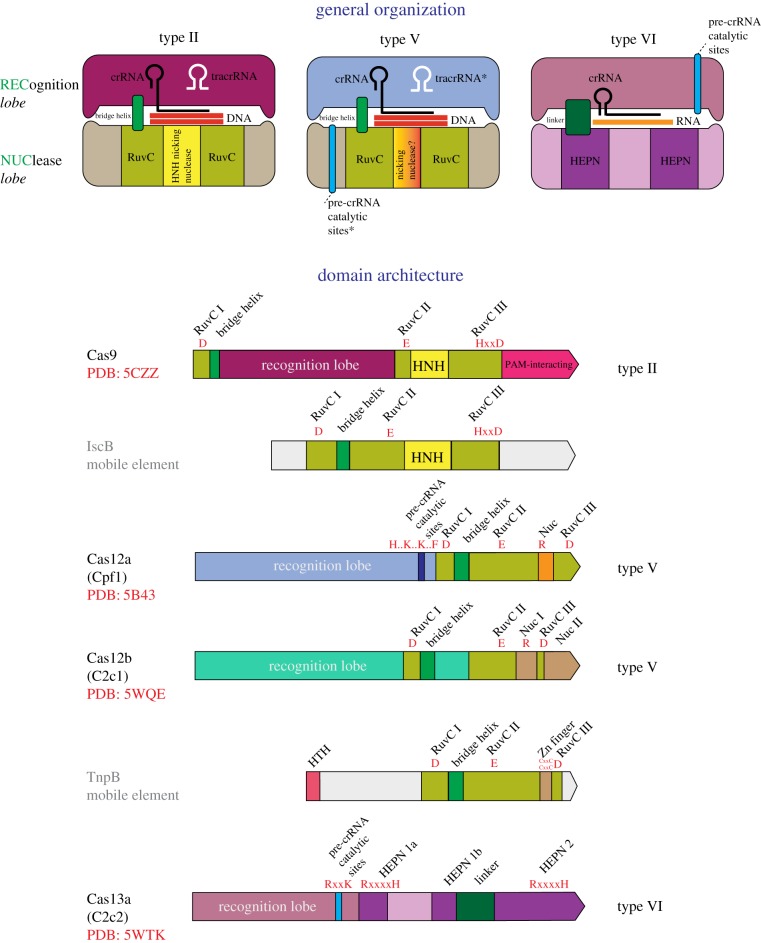
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
