

Superheat: An R package for creating beautiful and extendable heatmaps for visualizing complex data
- PMID: 30911216
- PMCID: PMC6430237
- DOI: 10.1080/10618600.2018.1473780
Superheat: An R package for creating beautiful and extendable heatmaps for visualizing complex data
Abstract
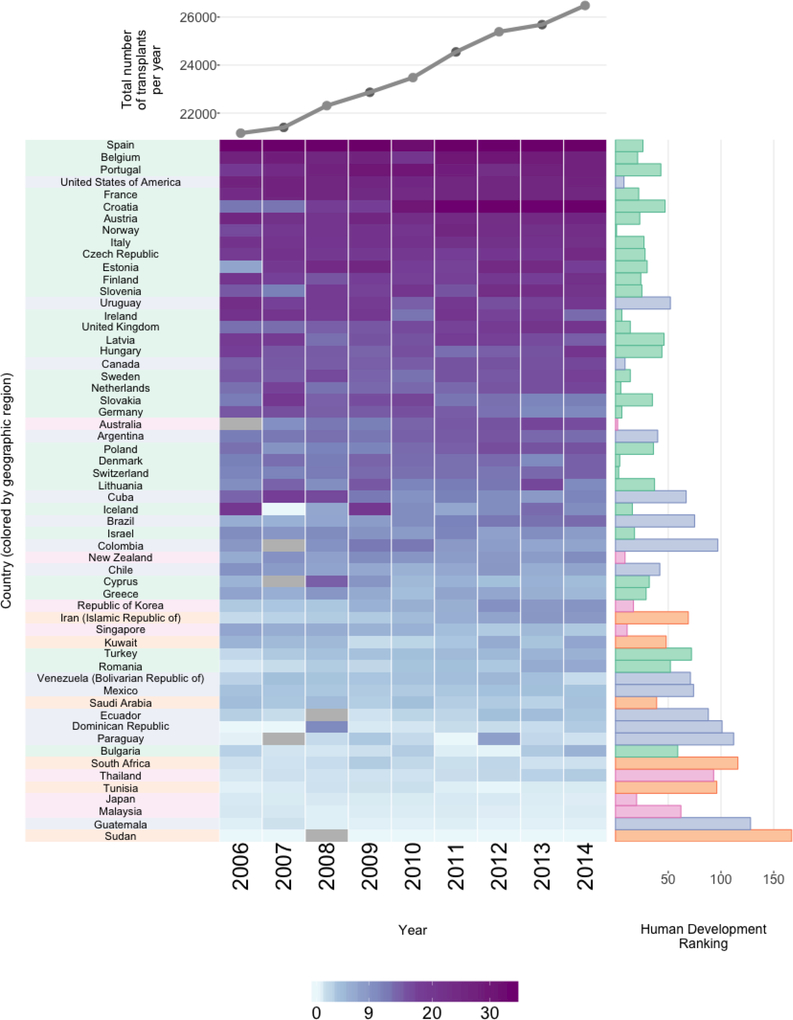
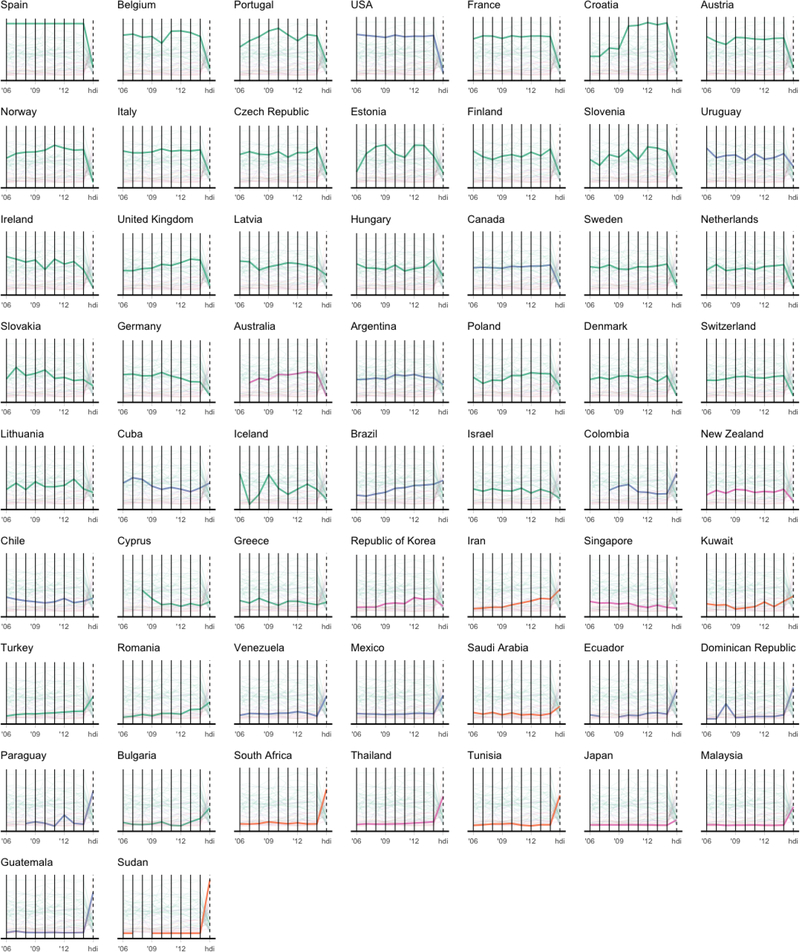
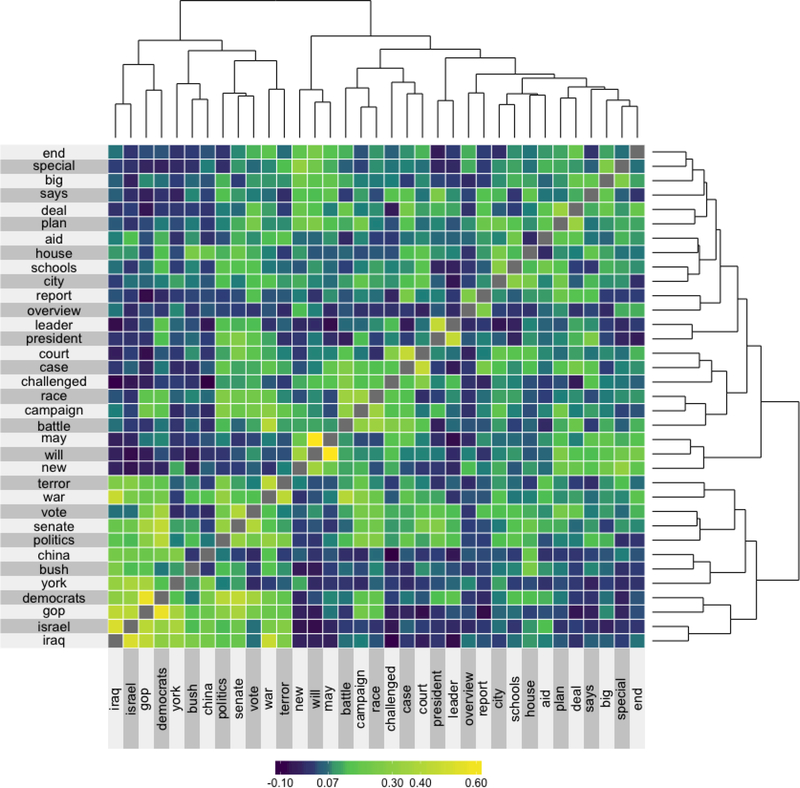
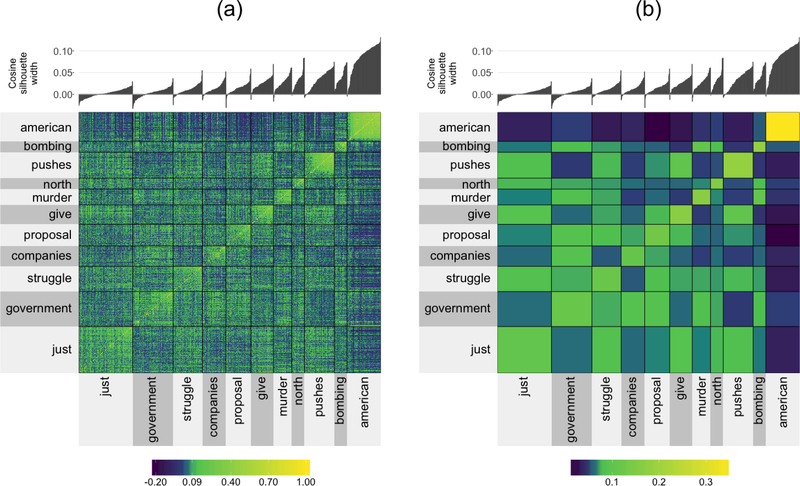
The technological advancements of the modern era have enabled the collection of huge amounts of data in science and beyond. Extracting useful information from such massive datasets is an ongoing challenge as traditional data visualization tools typically do not scale well in high-dimensional settings. An existing visualization technique that is particularly well suited to visualizing large datasets is the heatmap. Although heatmaps are extremely popular in fields such as bioinformatics, they remain a severely underutilized visualization tool in modern data analysis. This paper introduces superheat, a new R package that provides an extremely flexible and customizable platform for visualizing complex datasets. Superheat produces attractive and extendable heatmaps to which the user can add a response variable as a scatterplot, model results as boxplots, correlation information as barplots, and more. The goal of this paper is two-fold: (1) to demonstrate the potential of the heatmap as a core visualization method for a range of data types, and (2) to highlight the customizability and ease of implementation of the superheat R package for creating beautiful and extendable heatmaps. The capabilities and fundamental applicability of the superheat package will be explored via three reproducible case studies, each based on publicly available data sources.
Keywords: Data Visualization; Exploratory Data Analysis; Heatmap; Multivariate Data.
Figures
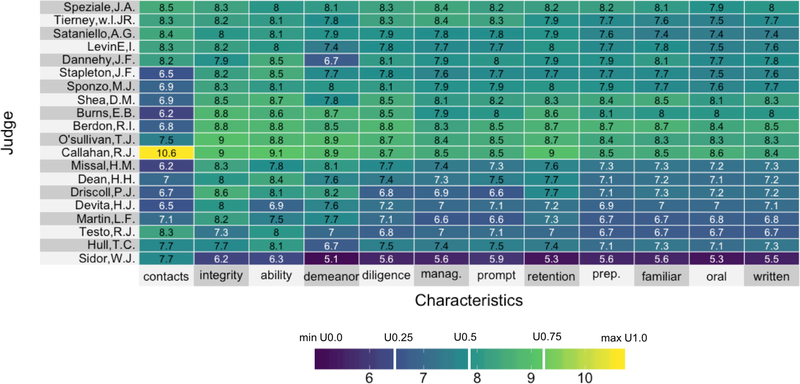
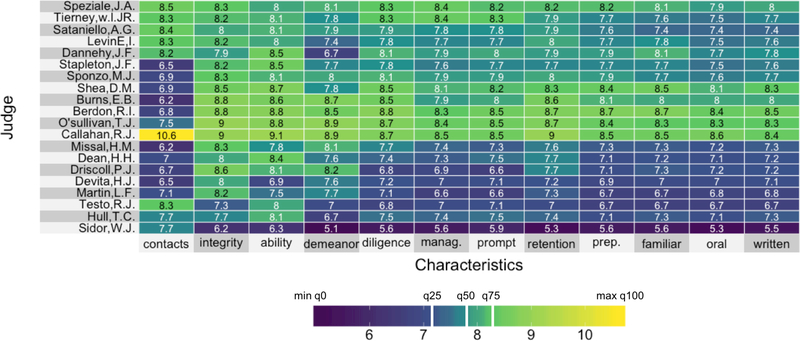
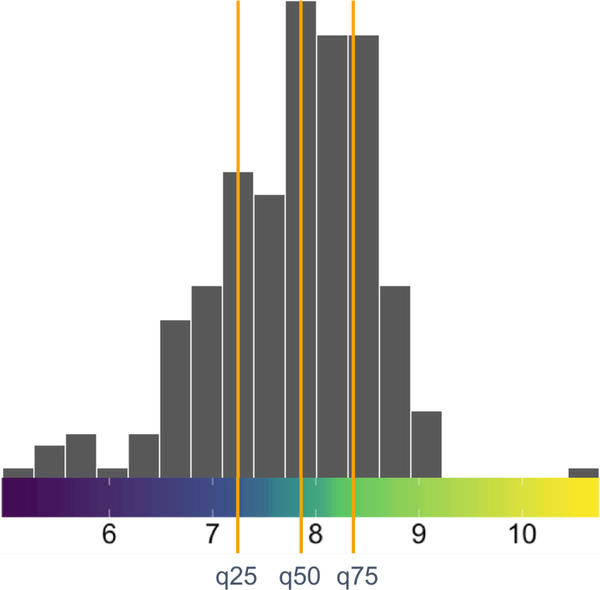
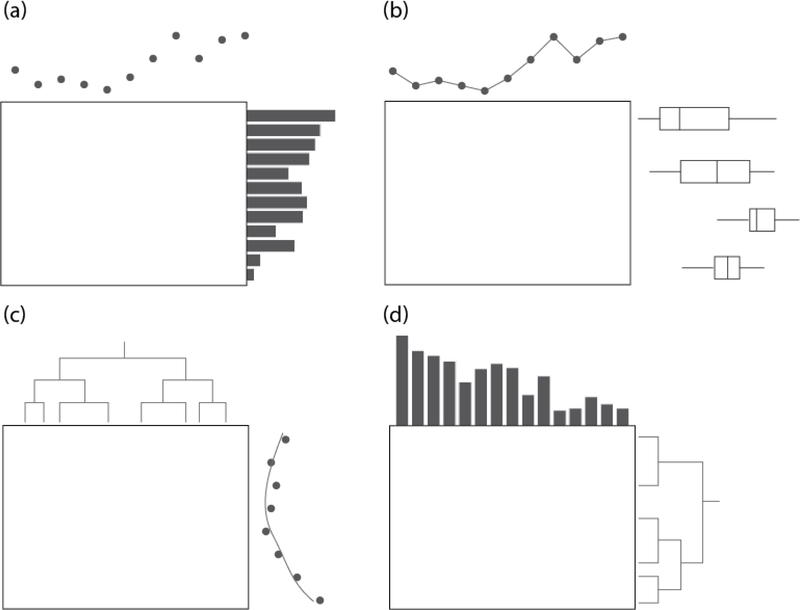


References
-
- Abouna GM (2008). Organ Shortage Crisis: Problems and Possible Solutions. Transplantation Proceedings 40(1), 34–38. - PubMed
-
- Andrews DF (1972). Plots of High-Dimensional Data. Biometrics 28(1), 125–136.
-
- Brinton W (1914). Graphic Methods for Presenting Facts,. New York: The Engineering Magazine Company.
-
- Bujack R, Turton TL, Samsel F, Ware C, Rogers DH, and Ahrens J (2018, January). The Good, the Bad, and the Ugly: A Theoretical Framework for the Assessment of Continuous Colormaps. IEEE Transactions on Visualization and Computer Graphics 24(1), 923–933. - PubMed
-
- Chen C (2002). Generalized Association Plots: Information Visualization via Iteratively Gener-ated Correlation Matrices. Statistica Sinica (12), 7–29.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources