

Functional Logistic Mixed-Effects Models for Learning Curves From Longitudinal Binary Data
- PMID: 30950747
- PMCID: PMC6802892
- DOI: 10.1044/2018_JSLHR-S-ASTM-18-0283
Functional Logistic Mixed-Effects Models for Learning Curves From Longitudinal Binary Data
Abstract
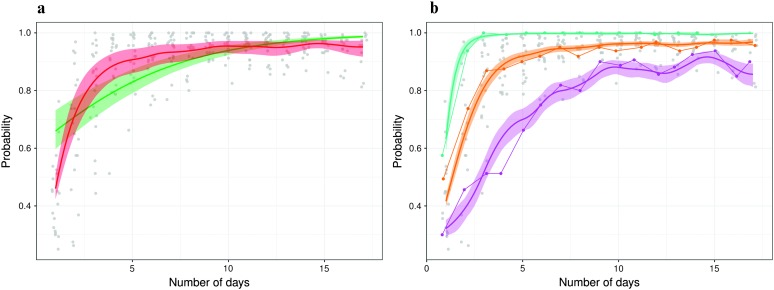
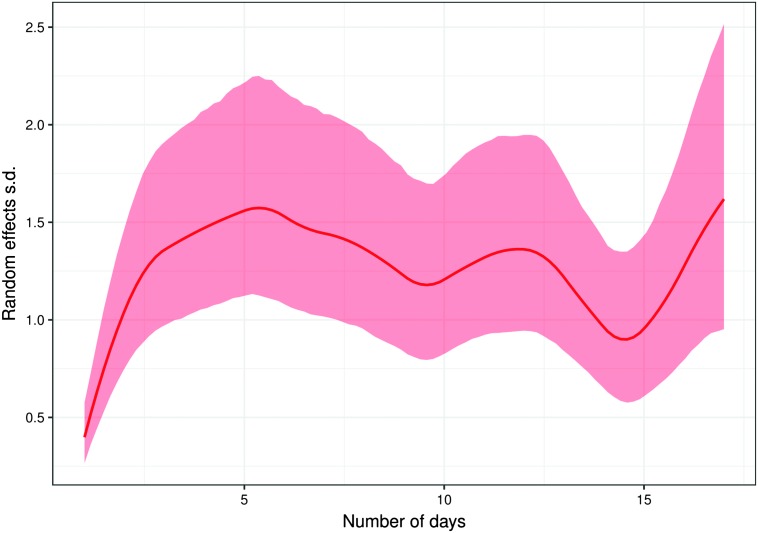
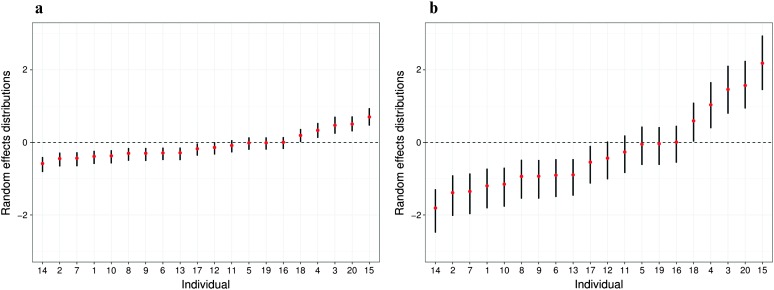
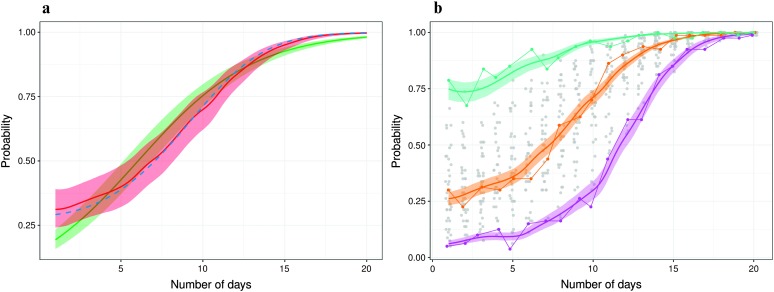
Purpose We present functional logistic mixed-effects models (FLMEMs) for estimating population and individual-level learning curves in longitudinal experiments. Method Using functional analysis tools in a Bayesian hierarchical framework, the FLMEM captures nonlinear, smoothly varying learning curves, appropriately accommodating uncertainty in various aspects of the analysis while also borrowing information across different model layers. An R package implementing our method is available as part of the Supplemental Materials . Results Application to speech learning data from Reetzke, Xie, Llanos, and Chandrasekaran (2018) and a simulation study demonstrate the utility of FLMEM and its many advantages over linear and logistic mixed-effects models. Conclusion The FLMEM is highly flexible and efficient in improving upon the practical limitations of linear models and logistic linear mixed-effects models. We expect the FLMEM to be a useful addition to the speech, language, and hearing scientist's toolkit. Supplemental Material https://doi.org/10.23641/asha.7822568.
Figures
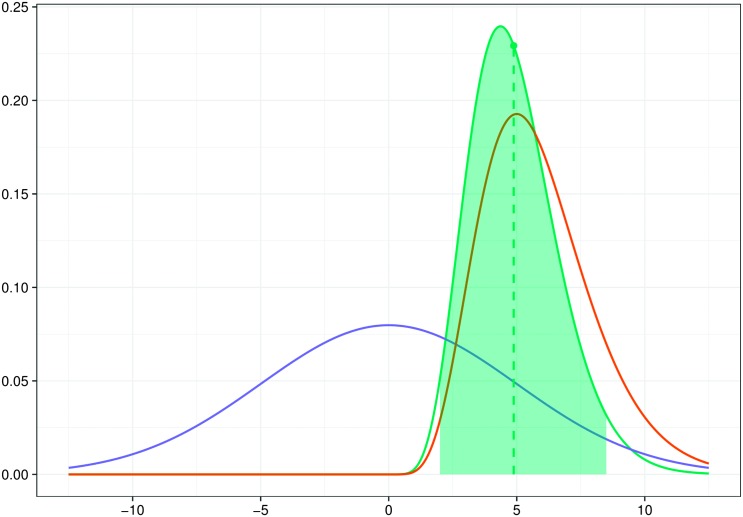
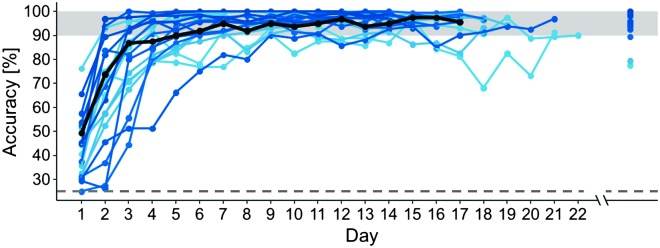
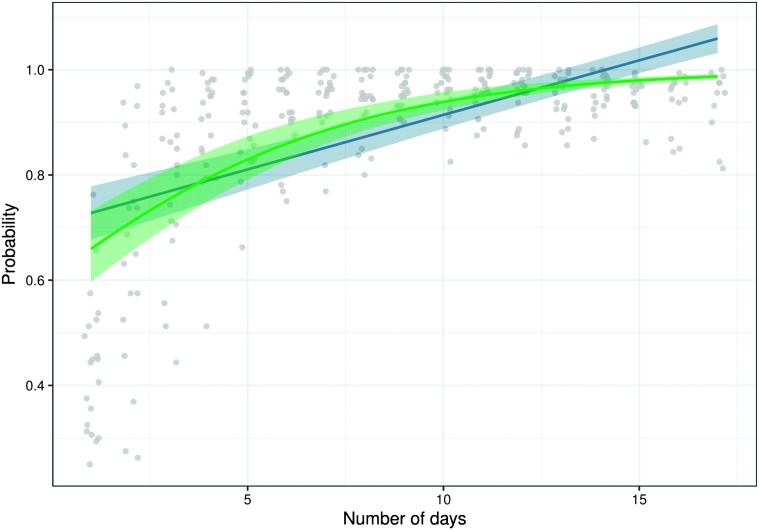
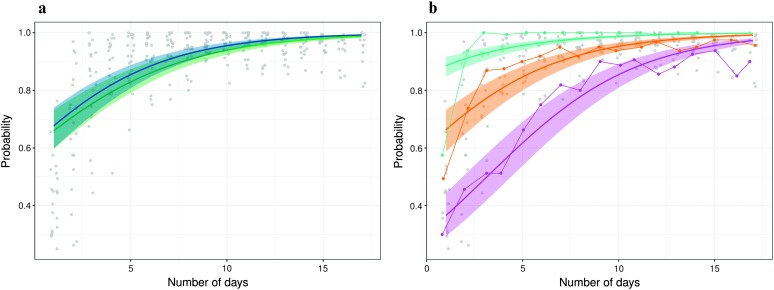
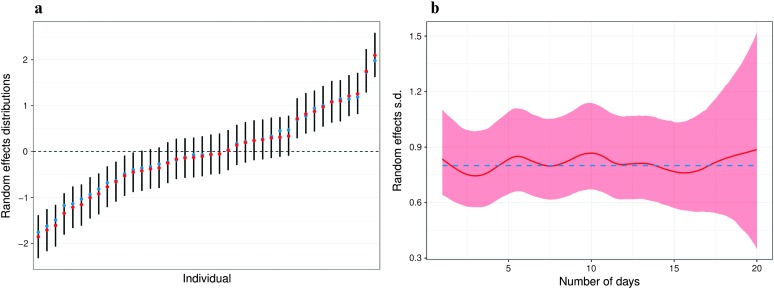
References
-
- Agresti A. (2002). Categorical data analysis (2nd ed.). New York, NY: Wiley-Interscience.
-
- Bates D., Maechler M., Bolker B., & Walker S. (2014). Package lme4: Linear-mixed effects models using Eigen and S4. R Package Version 67.
-
- Berger J., & Delampady M. (1987). Testing precise hypotheses. Statistical Science, 3, 317–352.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
