

Scrublet: Computational Identification of Cell Doublets in Single-Cell Transcriptomic Data
- PMID: 30954476
- PMCID: PMC6625319
- DOI: 10.1016/j.cels.2018.11.005
Scrublet: Computational Identification of Cell Doublets in Single-Cell Transcriptomic Data
Abstract
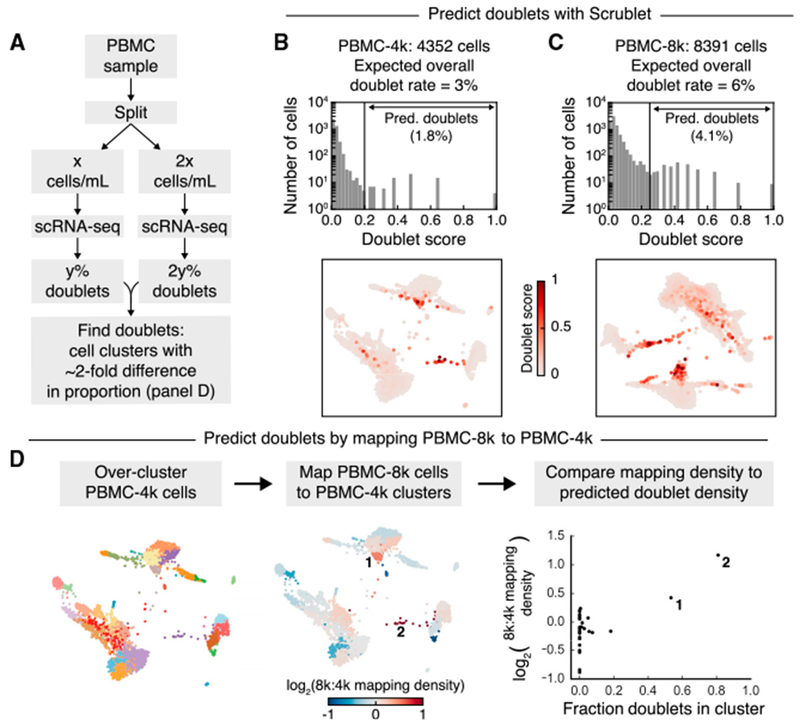
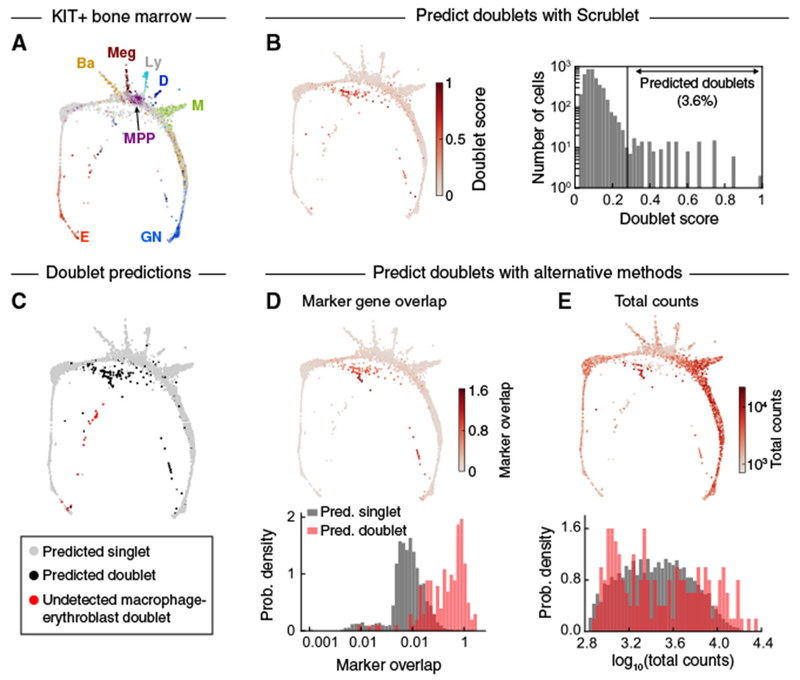
Single-cell RNA-sequencing has become a widely used, powerful approach for studying cell populations. However, these methods often generate multiplet artifacts, where two or more cells receive the same barcode, resulting in a hybrid transcriptome. In most experiments, multiplets account for several percent of transcriptomes and can confound downstream data analysis. Here, we present Single-Cell Remover of Doublets (Scrublet), a framework for predicting the impact of multiplets in a given analysis and identifying problematic multiplets. Scrublet avoids the need for expert knowledge or cell clustering by simulating multiplets from the data and building a nearest neighbor classifier. To demonstrate the utility of this approach, we test Scrublet on several datasets that include independent knowledge of cell multiplets. Scrublet is freely available for download at github.com/AllonKleinLab/scrublet.
Keywords: RNA-seq; artifact detection; bioinformatics; cell doublets; decoy classifier; high dimensional data analysis; single-cell.
Copyright © 2018 Elsevier Inc. All rights reserved.
Conflict of interest statement
DECLARATION OF INTERESTS
A.M.K. is a co-founder of 1Cell-Bio.
Figures
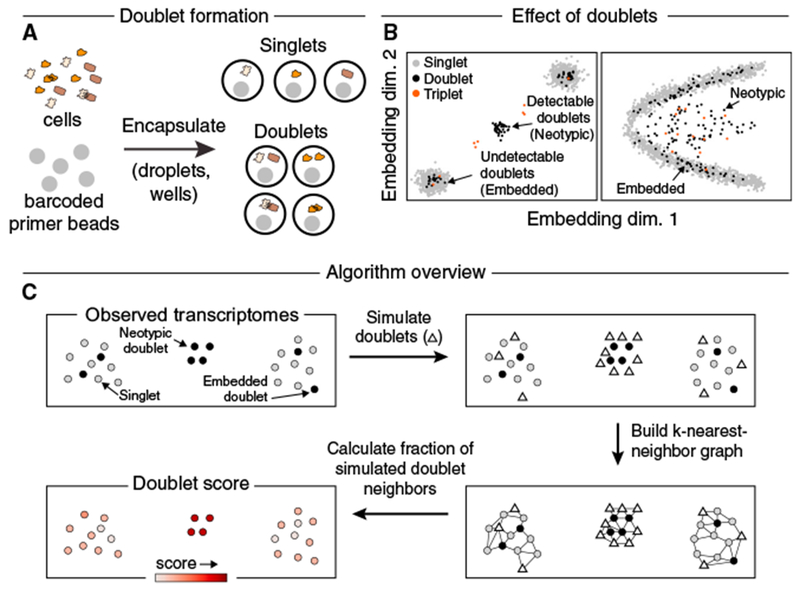
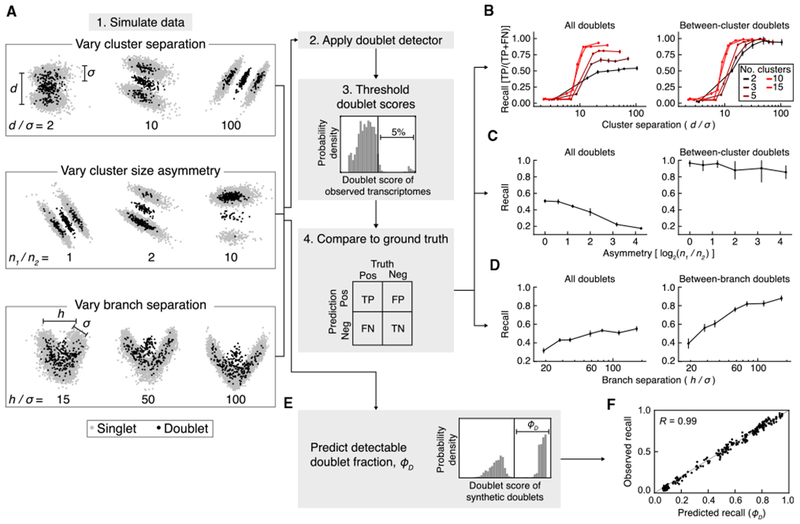
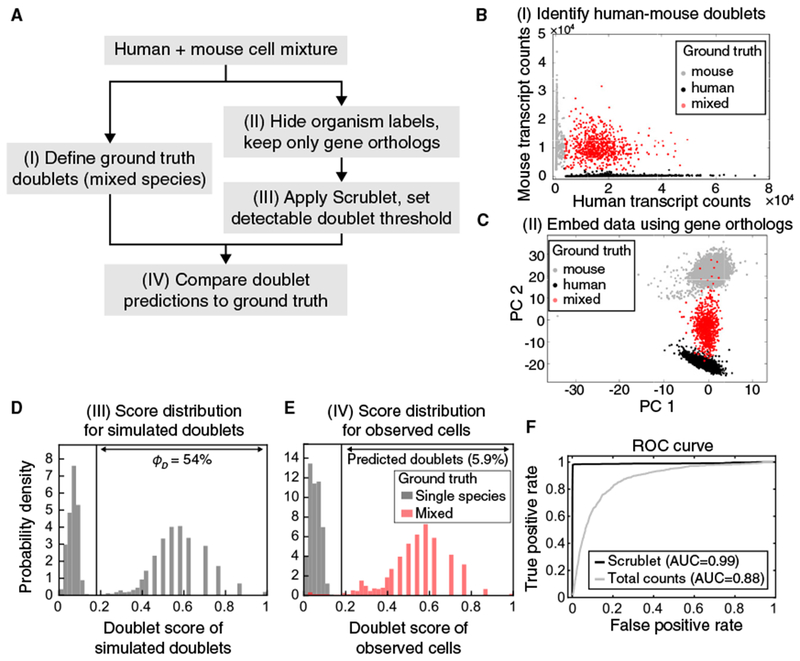
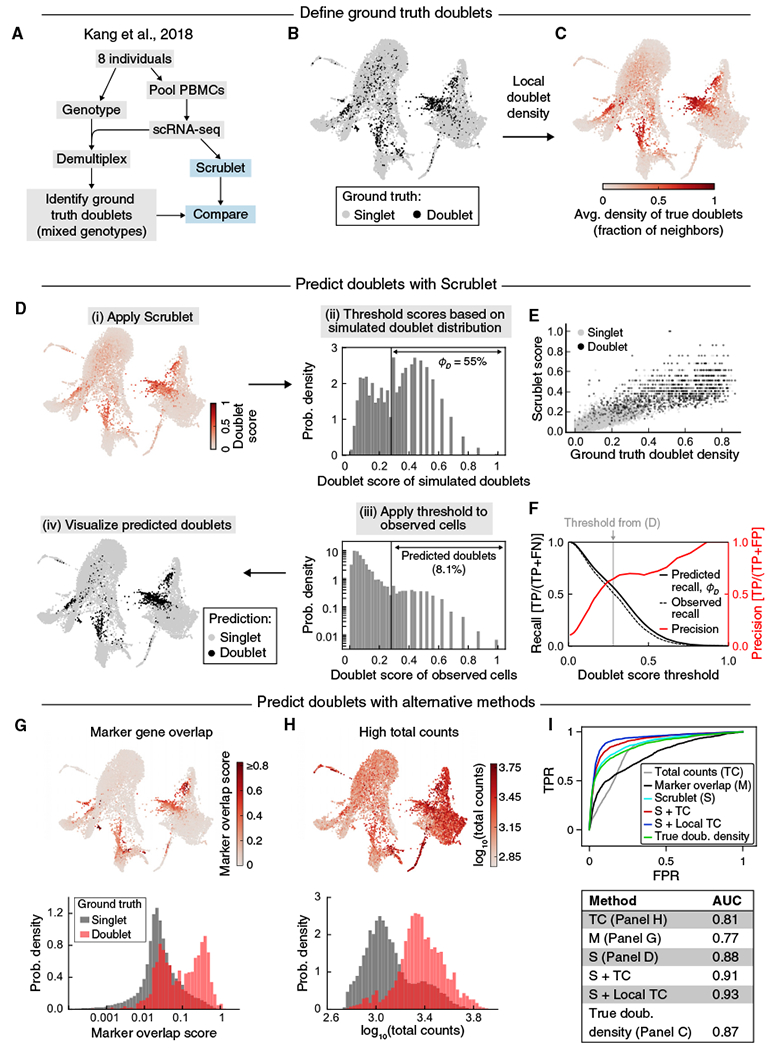
References
-
- Benjamini Y, and Hochberg Y (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. B (Methodol.) 57, 289–300.
-
- Bernhardsson E (2013). Annoy: approximate nearest neighbors in C++/Python optimized for memory usage and loading/saving to disk (2013).
-
- Blondel VD, Guillaume J-L, Lambiotte R, and Lefebvre E (2008). Fast un-folding of communities in large networks. J. Stat. Mech. Theory Exp
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
